
News & Events
[페어 트레이딩/고급편] 42. 페어 트레이딩의 단기 전략 (2)

페어 트레이딩 (Pairs Trading) – 추가편 (26)
페어 트레이딩의 단기 전략 (2)
이전 포스트에 이어 페어 트레이딩의 스프레드를 기술적으로 분석해 보자. 몇 가지 기술적 지표를 이용하여 의사결정 트리 (Decision Tree)라는 기계학습 (Machine learning) 알고리즘을 사용해 보기로 한다. 기계학습을 접해보지 못한 분들에게는 생소한 분야겠지만, 기술적 분석에 기계학습을 이용할 수 있고, 최종 결과가 어떤 식으로 나오는지 정도라도 봐둔다면 향후 분석에 도움이 될 것으로 생각된다 (기계학습에 대해서는 2015년 프로젝트로 블로그에 정리해 볼 계획임).
이전 포스트에서 언급한 개별 요인 분석 (Feature generation) 단계에서는 스프레드에 영향을 미치는 요인들을 선별해서, 각 요인들을 계량화한다. 아래 그림의 (A) 데이터는 LG디스플레이와 SK하이닉스의 주가와 거래량이다. 이 데이터를 기초로 페어 트레이딩의 스프레드를 계산한다. 그리고 스프레드와 거래량을 이용하여 factor1 ~ factor4 까지의 요인들을 계산한다.
factor1 은 스프레드에서 노이즈를 제거한 것이다 (Kalman filter를 이용함). 스프레드를 그대로 사용해도 되지만 학습 효율을 약간이라도 높여 보려고 노이즈를 제거하였다. factor2 는 factor1과 factor1의 5일 지수이동평균 (EMA)의 차이로 계산하였다. factor2 > 0 이면 스프레드가 상승 중이고, factor2 < 0 이면 하락 중임을 의미한다. factor3 은 스프레드의 과거 5일간 평균 변동성 (5일간 이동 표준편차)이고, 연간 단위로 환산하였다. factor4 는 두 종목의 거래량의 차이로 계산하였다. 거래량의 차이를 반영하는 것이 적당한지는 잘 모르겠지만, 일단 거래량의 차이로 적용해 본다.

2. 요인 통합 모형화 (Feature Aggregation)
개별 요인 분석이 끝나면 각 요인들을 통합하여 학습이 가능한 형태의 Data Set을 구성한다. 일자별로 각 요인들을 병합한다. 그리고 각 요인들의 결과로 향후 스프레드가 어떻게 변했는지를 (ahead와 class) 기록해 둔다. 이것은 학습 알고리즘에 과거의 결과를 알려주기 위함이다 (Supervised learning).
ahead 항목은 향후 5일간 스프레드의 평균값이다. 2013-01-09일의 경우 향후 5일간 스프레드의 평균값은 0.6681537이고, 이 값이 2013-01-09일의 ahead 값이다. 이것은 2013-01-09일 스프레드의 수준 (factor1)은 6.26 이었고, 스프레드가 하락 중 (factor2)이었으며, 스프레드의 단기 변동성 (factor3)이 34.09% 이고, 거래량의 차이가 13,263이었을 때는 향후 스프레드가 하락했음을 의미한다 (ahead < spread 임). 학습 알고리즘은 이 정보를 이용하여 (과거의 요인들과 ahead 값을 학습하여) 나름의 규칙을 만든다. 학습 알고리즘이 과거의 데이터로 규칙을 만들었다면, 이 규칙과 2014-12-26일의 요인들을 이용하여 미래의 ahead 값을 예측할 수 있다 (2014-12-26일의 ahead 는 모르는 상태임).
여기서는 기계학습 알고리즘 중 의사결정 트리 (Decision Tree)를 이용해 보기로 한다. 이산적 형태로 (Discrete) Decision Tree를 적용하기 위해 ahead 값을 직접 추정하는 대신 ahead가 현재의 spread보다 클지 작을지만 예측해 보기로 한다. 위의 Data Set에 class 항목은 ahead < spread 이면, “1”, 아니면 “2” 이다. class=1 은 향후 스프레드가 하락함을 의미하고, class=2 는 향후 스프레드가 상승함을 의미한다.
3. 모형의 학습 (Learning) 과 예측
위의 Data Set 중 2013-01-09 ~ 2013-12-18 까지의 데이터 (training data set)를 학습하여 Decision Tree를 만든다. 이 Decision Tree가 학습의 결과이며 각 요인들이 class로 분류되는 규칙이다. 이 규칙을 이용하여 2014-12-26 일의 데이터 (test data set)가 어느 class로 분류되는지 추정한다. 아래 결과는 2014-12-26일 이후 5일간 평균 스프레드는 83.33%의 확률로 하락할 것으로 예측하고 있다. 즉, 2014-12-26일의 요인들을 규칙에 대입해 보면 class=1 으로 분류된다고 예측하고 있다. 참고로, 아래 분석은 R 의 rpart 패키지를 이용하였다.

위의 예측 결과에 큰 의미가 있을지는 잘 모르겠지만, 과거의 패턴을 학습하여 미래 상황을 확률적으로 추정해 볼 수 있다는 것은 의미가 있어 보인다. 다만, 향후 스프레드에 영향을 미치는 요인들을 얼마나 잘 구성 했는가, 학습 시 모형의 복잡도나 과적합 (overfitting) 등의 문제는 효과적으로 처리 하였는가 등이 관건이 될 수 있다. 참고로, 위의 결과는 과적합 문제를 해결하기위해 Tree의 pruning 작업을 수행하였고, 결과의 변동성을 안정시키기 위해 bagging 작업을 수행하였다.
4. 예측의 성과 분석 (Cross validation test)
위의 예측 결과를 얼마나 신뢰할 수 있는지를 확인하려면 과거의 Data Set을 학습용 데이터 (training data set)와 시험용 데이터 (test data set)로 나눈 후 학습용 데이터로 만든 규칙이 시험용 데이터에 얼마나 잘 적용하는지를 확인하면 된다. 시험용 데이터는 학습에 사용되지 않았으므로 규칙을 모르는 상태이다. 시험용 데이터가 학습 규칙으로 잘 설명된다면 위의 예측은 신빙성이 있다고 말할 수 있다. 이런 방식의 시험을 Cross validation test라 한다.
아래의 Tree는 위의 예측 과정에서 생성된 학습 규칙 (Decision Tree)이다. 이 규칙에 의해 2014-12-26일의 데이터는 class=1 (83.33%)으로 분류된 것이다. 83.33%의 의미는 이 구간 (예측 지점)에는 class=1 이 83개, class=2 가 17개 정도의 비율로 섞여 있다는 것을 의미한다. Decision Tree는 각 지점 (노드)에 class=1 이나 class=2의 비율이 가능한 높도록 (순도가 높다 라고 하고, 엔트로피, Gini, Information gain 등으로 측정함) 규칙을 만드는 것이다.
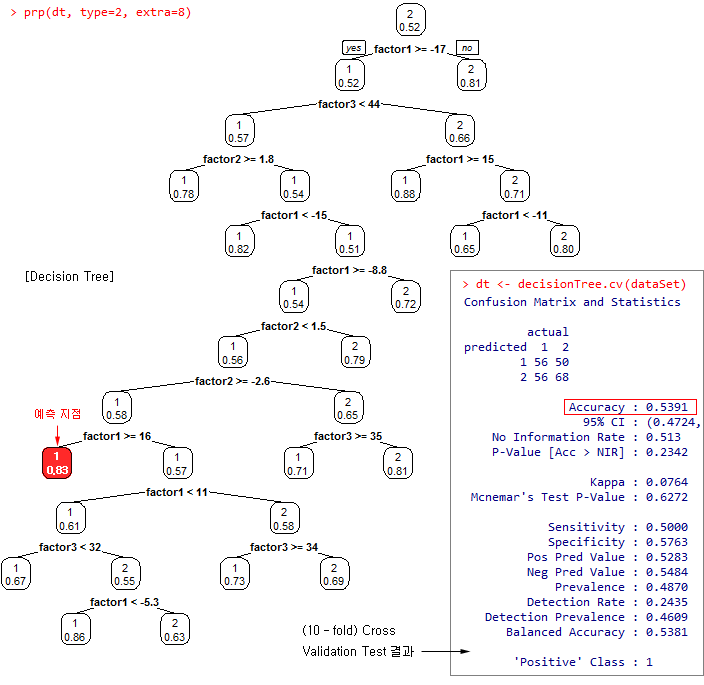
위의 Tree에서 factor4가 포함되지 않았다는 것도 주목할 만하다. factor4는 두 종목간의 거래량의 차이이다. 위의 Tree는 가지치기 작업 (pruning)에 의해 별로 중요하지 않은 요인이거나, 중복된 요인 등은 제거된 결과이다. 즉, factor4는 향후 스프레드를 예측하는데 별로 효과가 없었다는 것을 의미한다. 거래량이라는 정보는 이미 주가나 스프레드에 (factor1) 반영되었거나, 스프레드의 변동성 (factor3)에 반영되었기 때문에 별로 중요하지 않은 요인일 수도 있다. 아니면 단순히 거래량의 차이로 반영한 것이 문제가 됐을 수도 있다. 거래량이라는 정보를 어떤 방식으로 포함시킬 것인가도 관건이 된다.
위 그림의 오른쪽 박스는 Cross validation test 결과이다. 전체 Data Set을 10 구간으로 나누고 이 중 첫 번째 구간을 시험용 데이터, 나머지 구간을 학습용 데이터로 만들어서 학습 규칙을 만들고 시험용 데이터를 얼마나 잘 맞추는가를 시험한 것이다. 이런 시험을 다시 10번 반복하여 두 번째부터 마지막 구간까지를 시험용 데이터로 사용하여 시험한 결과이다 (k-fold Cross validation 이라 함). 테스트 결과 학습 규칙들은 시험용 데이터의 class 들을 약 54% 정도 맞췄다. 즉, 100개 중에 54개는 맞추고 46개는 틀린 것이다. 테스트 결과가 만족스럽지는 못하다. 이 정도의 성능이라면, 위에서 예측한 “스프레드의 하락 가능성 83.33%” 라는 결과를 어떻게 받아들여야 할지 모르겠다.
사실 주가 차트나, 스프레드 차트의 단기 예측은 쉽지 않다. 위의 54% 라는 성능은 거의 50:50 이므로, 단기 예측이 어렵다는 것을 의미한다. 성능을 개선하기 위해서는 다른 요인들을 더 추가해 볼 필요가 있다. 향후 스프레드에 영향을 미치는 중요한 요인들 중에 주요 거래자 (기관/외국인) 들의 수급, 전체 시장의 변동성, 다른 페어들의 움직임 등의 요인들도 포함해서 학습 규칙을 개선해 볼 필요가 있다. 또한, 기계학습 알고리즘 중에 다른 알고리즘 (ex : Naive bayes, Bayesian network, Neural network, Logistic regression 등)들을 사용해 볼 필요도 있다.
여기까지 페어 트레이딩의 단기적 접근 전략에 대해 살펴보았다. 단기 예측 결과가 만족스럽지는 못하지만 의사결정에 참고는 될 수 있을 것이다.
[출처]42. 페어 트레이딩의 단기 전략 (2)|작성자아마퀀트
