
News & Events
[Reinforcement Learning] 3. Markov Decision Processes (1)

1. Markov Processes

이번에 다루게 될 MDP에 대해서 소개를 하면 RL, 강화학습에서 가장 중요한 핵심 이론이 됩니다.
이 강의에서는 전제조건으로 agent가 환경에서 발생되는 모든 정보를 볼 수 있다고 가정합니다. (fully observable) 설명을 하기 쉬운 환경이지만 실제로 우리가 살고 있는 환경은 그렇치 않죠. 우리는 아무리 노력을 해도 세상의 모든 뉴스를 다 보고 알수는 없기 때문입니다.
어떠한 현재 상태는 큰 프로세스가 진행이 되고 있는 과정 중에서 특정 시점이 될 것이고, 모든 환경을 다 볼 수 있기 때문에 완전히 특성들을 갖추고 있다고 볼 수 있겠습니다.

Markov property에 대한 정의를 알아봅니다.
agent가 environment에서 어떠한 action을 하기 위해서는 의사결정이 필요합니다. 그리고 의사결정을 하기 위해서는 environment로 부터 정보들을 받게 되는데 이러한 정보들의 특성을 Markov property라고 합니다.
현재의 상태는 과거의 어떠한 과정들을 거쳐서 발생이 된 것 임으로, 현재 상태에서의 정보들은 과거의 중요한 정보들을 포함하고 있다고 볼 수 있습니다. 모든 과거의 정보들을 포함하고 있지는 않지만 앞으로 다가올 미래를 예측하는데 필요한 정보는 충분히 포함하고 있다는 것입니다.
그래서 의사결정을 할때에는 현재의 정보들에 집중하면 되는데 이는 현재의 정보가 Markov property를 가지고 있기 때문입니다. 그러므로 미래는 과거와 독립적이라고 강의에서 이야기 합니다.
이를 통해서 강화학습은 현재 시점에서 미래 가치를 예측하고 그에 따른 의사결정을 할 수 있게 됩니다.

현재의 상태인 s 와 연속된 다음의 상태를 s’ 라고 했을때 상태가 s에서 s’로 변경될 확률을 위와 같이 수학적으로 표현을 할 수 있습니다.
통계에서 사용하는 조건부 확률을 이용한 표현이 되겠습니다.
St가 s인 현재 상태일때를 조건으로 하는 St+1이 s’로 다음의 상태가 될 확률을 Pss’로 표현하기로 합니다.
이를 상태가 발생하는 경우에 수만큼 나열하여 매트릭스의 형태로 표현을 하면 테이블 형태의 P로도 표현이 됩니다.
P11 은 현재 상태가 1이라고 할때 다음의 상태도 1인 경우, 즉 현재 상태를 유지하는 경우의 확률이 될 것입니다. p12는 현재 상태가 1에서 다음 상태가 2로 변경이 될 확률이고 이렇게 n 만큼 나열을 하면 P1n이 되겠습니다. 현재 상태가 2에서 n 까지 있다면 세로 방향으로 더 많아지게 되겠어 Pnn까지 표현이 됩니다.

이 강좌에서는 Markov process가 기본적으로는 랜덤한 프로세스라고 생각하고 진행합니다. 과거에 무엇을 했는지는 중요하지 않고 기억도 하지 않고 현재 상태에서 하고 싶은 것만을 랜덤하게 선택한다고 생각합니다.
이런 모든 상태들을 고려하여 앞으로 변경될 확률까지를 고려한 것이 Markov process 혹은 Markov chain 이라고 합니다. 그리고 S와 P matrix로 이를 표현을 할 수 있게 되었습니다
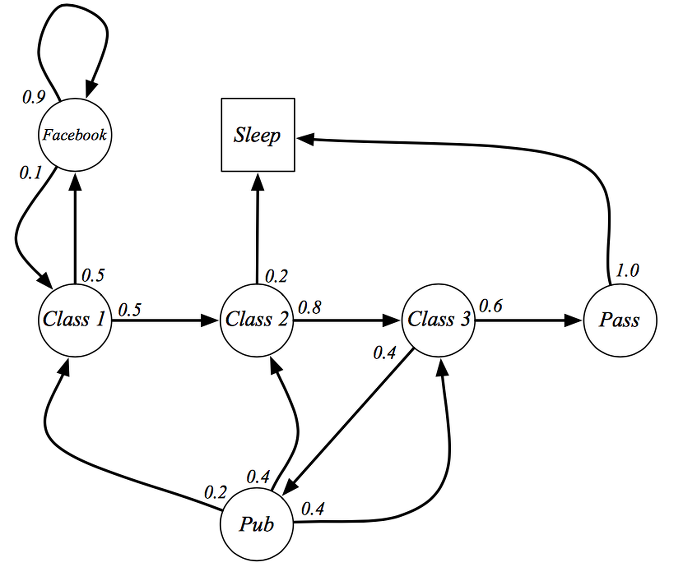
대학생들이 학교에서 수업에 참여하는 혹은 딴짓을 하는 Markov process를 예제로 설명하고 있습니다.
심플하게 3개의 class를 모두 참여하면 해당 과정을 pass 할 수 있는 프로세스를 표현하고 있습니다. 하지만 학생들이 모두 열심히 공부를 하지는 않죠. 그래서 가끔 페이스북을 하거나 수업을 땡땡이 하고 술을 먹으로 가거나 잘 수도 있는 state들도 표현이 되어 있습니다.
class 1에서 시작을 해보죠. class 1을 마치고 학생들이 class 2로 갈 확률이 50%이고 class 2로 가지 않고 facebook으로 갈 확률이 50%입니다. 한번 facebook으로 간 학생들을 90%의 확률로 계속 facebook에 빠져 있게 되고 10%만 다시 수업으로 복귀하게 됩니다.
힘들게 class 2로 갔지만 갑자기 졸음이 몰려와서 자는 경우도 있네요. 열심히 하는 학생들은 class 3까지 완료하고 Pass 를 하게 되는데 모든 학생들이 자러 갑니다. 이때 sleep state를 terminal state라고 합니다. 모든 프로세스가 종료되는 시점을 말합니다.
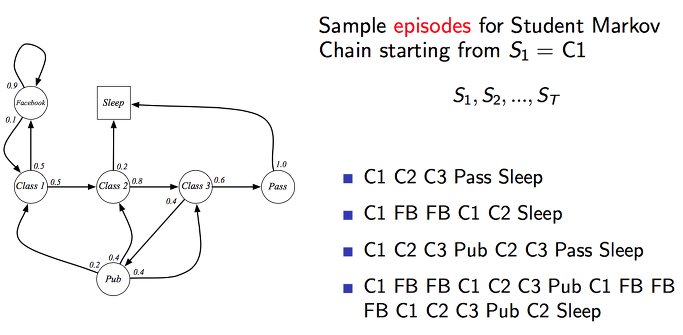
위의 예제 상황에서 몇가지 에피소드를 만들어보았습니다. 순서대로 상태가 변화하는 것을 볼 수 있습니다. 가장 첫번째의 에피소드는 상당한 모범생 스타일이라는 것을 추론할 수 있습니다.^^ 그외 학생들은 양아치(?)…
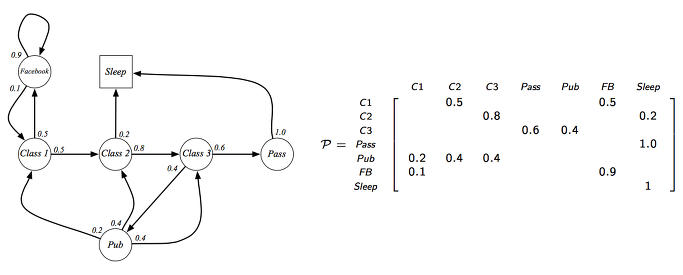
위 예제에서 이동한 가능한 상태들에 대해서 P matrix에 테이블로서 정리하여 표현을 하면 발생한 케이스와 확률들을 모두 표현할 수 있습니다.
2. Markov Reward Processes
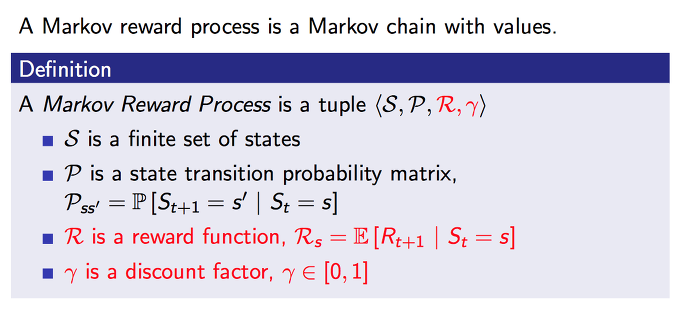
앞에서 알아본 Markov chain에다가 values (가치)라는 개념을 추가하여 생각해 볼 수 있습니다. 이를 Markov Reward Process 라고 합니다.
이 가치를 판단하기 위해서는 두가지 factor가 추가가 되는데 하나가 reward이고 다른 하나는 discount factor입니다.
reward는 현재 상태를 기준으로 하여 다음 상태에 받게 될 기대되는 보상을 표현합니다. 그리고 discount factor는 0에서 1 사이의 값으로 할인율 입니다.
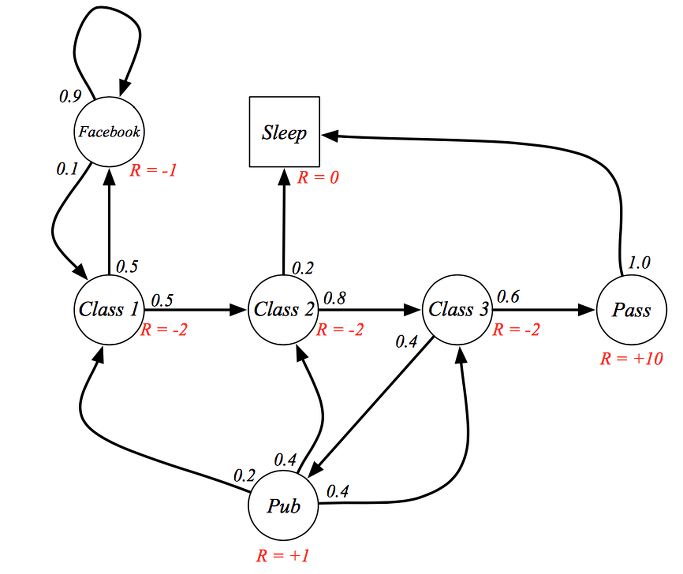
학생 예제로 돌아가서 class 1에서 시작하여 학생이 50%의 확률로 class 2를 선택하고 이동하게 되었었습니다. 이 때 빨간색의 reward가 추가가 된 것을 볼 수 있습니다. class 2로 이동한 학생들이 받을 보상이 -2 값이 됩니다. 그리하여 class 3까지 모두 완료한 학생들은 pass가 되면서 +10 이라는 큰 보상을 받게 되고 모두 자러 갑니다.
모두가 자러가서 이 프로세스가 종료가 되면 reward는 0을 받게 됩니다.

우리가 원하는 목표로 하는 것은 이러한 reward에 총합을 구하는 것입니다. 현재 시점에서 앞으로 내가 보상을 받게 될 모든 것들을 계산해 보는 것이지요.
하지만, 이때 현재 즉시 받는 보상과 미래에 받게 되는 보상과는 다른 가치를 가지고 있으므로 할인율을 적용해서 discount를 해줍니다. 이것은 미래 가치를 현재 가치로 환산하는 것이라고 생각하면 될 것 같습니다.
할인율이 0에서 1사이의 실수 값이기 때문에 이를 제곱하게 되면 특정한 값으로 수렴하게 됩니다. time step k에서 수렴을 하게 될 경우를 보면 바로 다음의 time step k+1에서의 보상이 값이 있더라도 너무 먼 미래의 보상임으로 고려하지 않게 되는 것과 동일합니다. 이러한 특성이 있기에 무한대로 time step이 진행이 된다고 해도 현재 시점에서 우리가 의사결정시에 고려할 미래 가치는 유한하게 고려되어 집니다.
그리고, 이 할인율이 0이 되면 미래에 받게 될 보상들이 모두 0이 되어 고려하지 않게 됩니다. 그렇기에 바로 다음의 보상만을 추구하는 근시안적인 행동을 하게 될 것입니다. 반대로 할인율이 1에 근처에 가까워 지면 질수록 미래 보상에 대한 할인이 작아지기 때문에 미래 보상들을 더 많이 고려하게 되는 원시안적인 행동을 하게 될 것입니다.

대부분의 경우에서 할인율을 사용하여 강화학습을 하게 되는 이유를 설명하고 있습니다.
수학적으로 계산을 하기가 편리하고 무한대로 프로세스가 진행이 되더라도 markov reward를 계산할 수 있게 됩니다. 미래에 대한 보상은 사실적으로 불확실한 것이기 때문에 어느정도 할인하여 감가를 하는 것이 좋기도 합니다. 지금 100만원을 받는 것과 내년에 100만원을 받는 것은 동일하지 않으니까요. 즉각적인 보상에 좀더 끌리는 것이 당연하기도 합니다.
때로는 환경에 따라서 할인율을 적용하지 않는 것도 가능합니다. 보통은 현재 상태를 유지하는 어떤 것을 하는 경우에 적용이 됩니다. 현재 상태를 유지 하지 못하는 경우에는 종료가 되는 환경이 되고 이런경우는 대체로 무한대로 유지를 할 수 있는 경우는 별로 없으니까요.
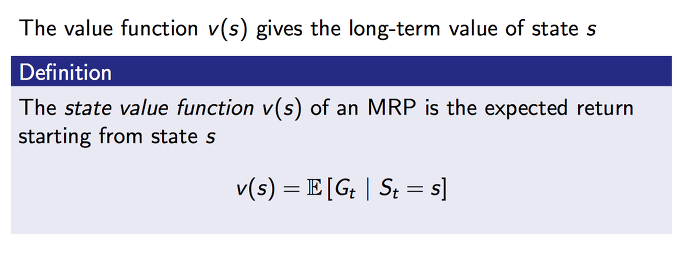
현재 상태가 s 라는 state일때 앞으로 발생할 것으로 기대되는(E) 모든 rewards 의 합을 value 라고 합니다. 이것을 조건부 확률로 수학적으로 표현을 하면 위와 같이 됩니다.
이 value function는 현재 시점에서 미래의 모든 기대하는 보상들을 표현하고 이를 미래 가치라고 할 수 있습니다.
강화학습에서 핵심적으로 학습을 통해서 찾고자 하는 것이 바로 이 value function을 최대한 정확하게 찾는 것이라고 할 수도 있습니다. 다시 말해서 미래 가치가 가장 큰 의사결정을 하고 행동하는 것이 우리의 최종 목표가 되며 이는 매우 중요한 내용입니다.

학생 예제로 다시 돌아서 각각의 에피소드들에 대한 value 를 구해보면 위와 같이 됩니다.
가장 모범생의 행동 스타일이 가장 좋은 value 값을 가지고 있는 걸 보니 가장 잘 한 학생인거 같아 보입니다.^^
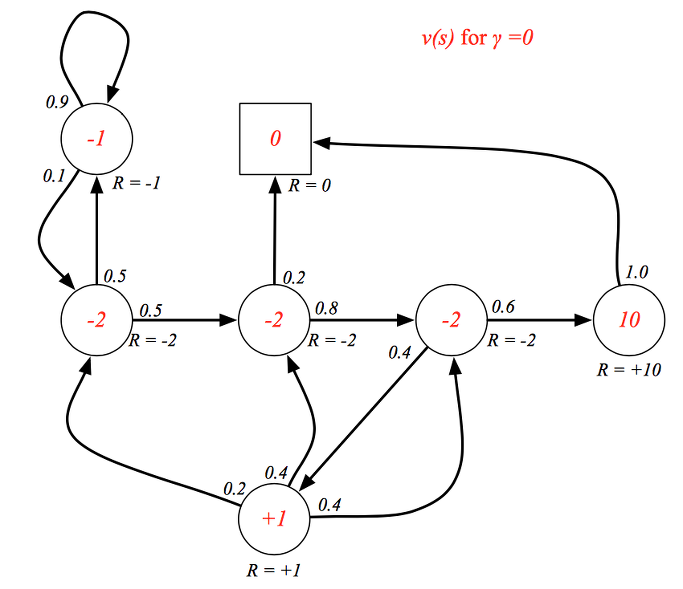
위의 예제 도면에서 할인율이 0이라고 전제하고 각각의 상태에 따른 value 값을 빨간색으로 표현을 하였습니다. 할인율이 0으로 미래의 보상을 고려하지 않기 때문에 근시안적인 value 값으로만 나타납니다.
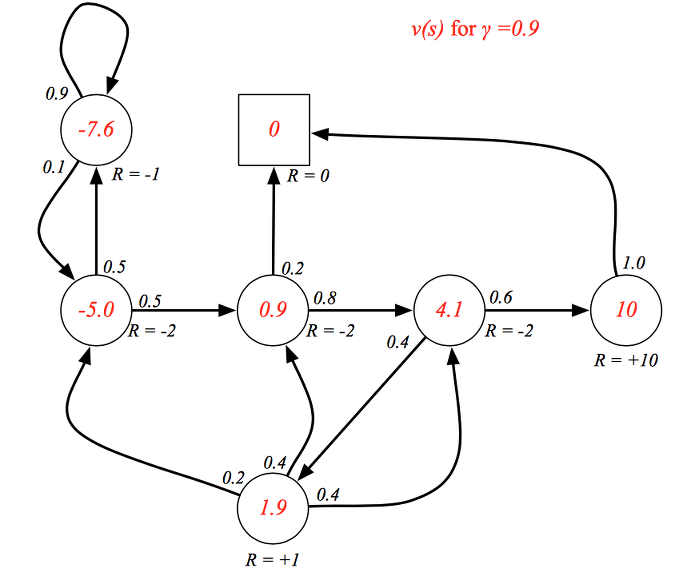
이번에는 할인율이 0.9라고 전제를 하고 value 값을 보면 위와 같이 미래 보상을 고려한 각각의 현재 상태에서의 가치를 표현할 수 있게 됩니다. pass 쪽으로 갈 수록 value 가 커지는 것을 볼 수 있습니다.
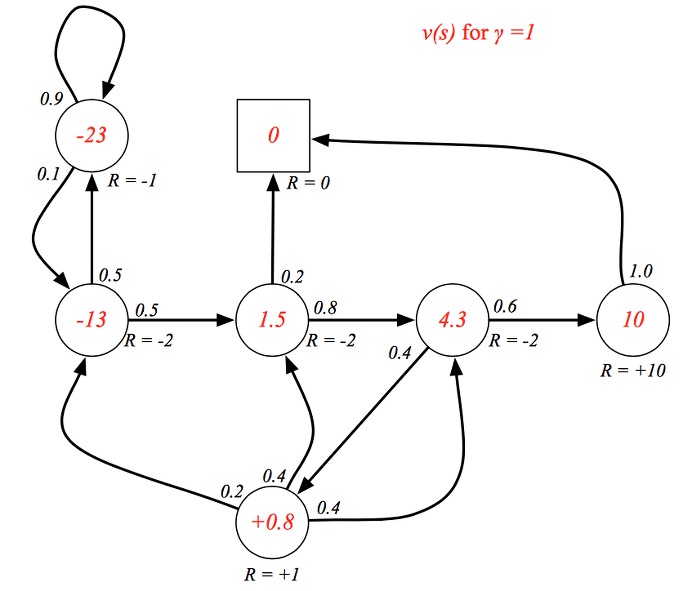
할인율이 1인 경우는 모든 미래 가치를 할인없이 고려하고 있으므로 매우 원시안적인 상태로 value 값들이 나타나집니다.

이러한 value function을 두가지 파트로 분리할 수 있는데 이때 사용되는 것이 Bellman Equation 입니다. Bellman Equation은 dynamic program에서 널리 사용되는 방정식입니다.
위의 공식을 따라가보면, value function은 현재 시점에서 미래에 기대되는 보상들의 총합으로 표현을 했습니다. 이를 할인율을 적용하여 풀어서 쓰면 두번째 라인의 공식이 됩니다. 이를 다시 할인율로 묶어서 표현을 하면 세번째 라인의 공식이 되는데, 이때 괄호 안에 내용이 바로 다음 time step의 Goal이 되는 것을 알 수 있습니다. 그래서 다시 정리하면 네번째 라인으로 표현을 할 수 있습니다. 마지막으로 next time step의 Goal은 다시 해당 next time step의 value function과 같습니다. 그리하여 마지막 라인이 동일한 value function을 표현하고 있습니다.
우리는 이 Bellman equation을 통해서 현재 시점의 value는 현재의 보상과 다음 시점의 value로 표현할 수 있다는 것을 알수 있게 되었습니다. 재귀적인 형태로서 미래의 가치들이 현재의 가치에 영향을 주고 있는 형태가 됩니다.
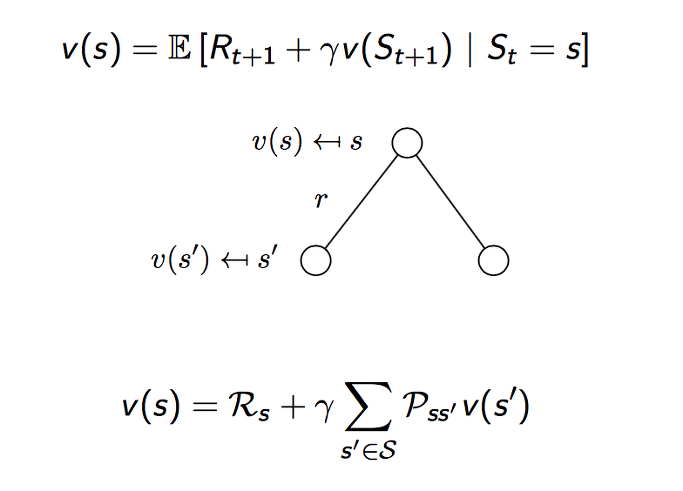
위에 중간 그림을 backup diagram 이라고 합니다. 이 다이이그램이 위의 공식으로 표현된 Bellman Equation을 도식화한 것이라고 보시면 되겠습니다.
최상단의 현재 상태 s 에서의 value function이 v(s)로 표현이 되어 있고, 현재 상태에서 어떤 행동을 하여 다음 상태로 넘어가면 아래 부분의 s’ 이 되고 이때의 value function은 v(s’)가 될 겁니다. 우리가 취할 수 있는 행동들이 여러개 있을 수 있으니 트리 구조로 생겨지게 됩니다.
미래의 가치가 현재의 시점의 가치를 결정하기 때문에 반대로 밑에 부분에서의 v(s’) 두개를 합하여 할인하면 현재 시점 s의 가치를 구성하는 형태가 됩니다. 여기서 진행이 트리구조로 되어 지기 때문에 앞으로 의사결정을 통해서 선택하게 될 행동을 취하면 선택한 가치가 될 것이고, 다음 시점에서의 선택되지 않은 가치는 경제학에서 말하는 기회비용이 될 수 있습니다.
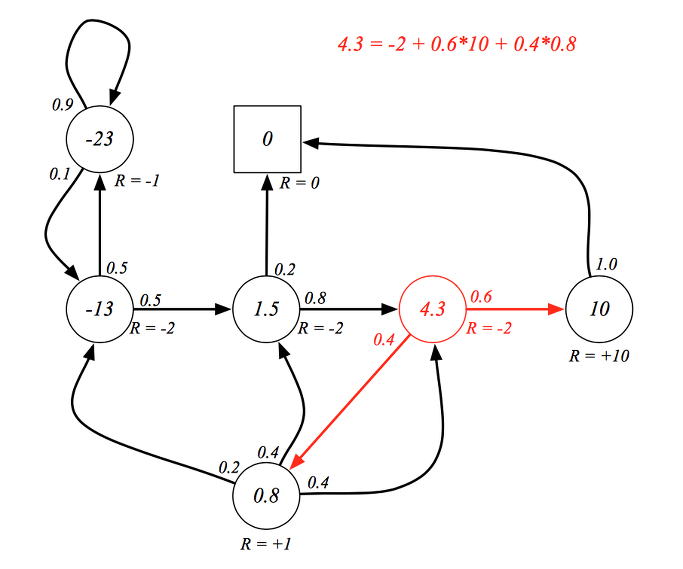
다시 학생 예제로 돌아가서 class 3를 현재 상태라고 하고 value function을 계산하면 위와 같이 됩니다. 현재 시점에서의 보상 -2를 더하고 확률적으로 선택될 다음 상태들의 value를 계산하면 4.3의 값이 나오게 됩니다. 이 값이 class 3에서의 value 입니다.

지금까지 단위 state에서 다음 state에서의 Bellman equation을 살펴보았는데 이제 이를 모두 표현하는 matrix 형태로 표현을 하면 위와 같이 됩니다.
v(1)~v(n)은 value function으로서 column vector 로 표현이 되며 각각의 state 1 ~ n 까지를 모두 표현합니다. 동일한 내용의 식을 모두 펼쳐 놓았다고 생각하면 되겠습니다.
실제로 프로그래밍으로 구현을 할때에는 이와 같이 연산을 하게 될 것입니다.

Bellman equation이 선형 방정식입니다. 물론 matrix에 대한 선형 방정식입니다. 이것은 v 에 대한 식으로 묶고 이항하면 위와 같은 공식이 됩니다. 이러한 방식으로 직접 푸는 것은 사이즈가 작은 MRP에서만 가능하다는 것을 명심하도록 합니다.
대부분의 복잡한 경우에는 아래 나열된 방식으로 해결하게 되며 이는 다음 내용에서 다루게 될 예정입니다.
