News & Events
[Tensorflow] 15. Tensorflow 시작하기 – Logging & Monitoring

이번에는 Tensorflow를 이용해서 모델을 학습하는 알고리즘을 구현할 때,
Tensorflow의 로깅하는 기능과 모니터링 할때 사용하는 api에 대해서 알아보겠습니다.
이번 내용에서는 이전에서 다뤘던 tf.contrib.learn Quickstart 에서 사용했던 내용을 기반으로 합니다. 안보신 분들은 한번 읽어보시고 오시면 좋을 것 같습니다.
이 예제는 Iris 3개종 중에서 하나를 예측하는 내용입니다.
이를 위해서 Neural Net classifier 를 사용하여 학습을 하게 됩니다.
그런데 이 예제 소스를 그냥 실행시키면 현재는 결과 값만 볼 수 있습니다. 학습이 진행되는 과정에 대한 내용을 볼 수 없는 상태입니다.
로깅을 하지 않으면 일종에 눈가리고 프로그래밍을 하는 것과 같습니다. 실제 어떻게 동작하고 수행이 되고 있는지에 대해서 우리가 볼수가 없기 때문이지요. 기본적인 테스트를 진행할때 반듯이 적절한 로깅은 선택이 아닌 필수가 되어야 할 것 같습니다.
여기에서는 Tensorflow에서 제공하는 Gradient Descent 알고리즘을 사용할때 적절하게 값이 minimize 하게 수렴하고 있는지를 확인을 해야하고, 또 수렴 과정이 다 진행이 되지 않았는데도 불구하고 완료로 처리되는 것은 아닌지등의 확인을 해야하기 때문에 학습 과정의 로깅을 해야하겠지요.
그런데 학습 과정중에 데이터를 로깅을 하기 위해서 모델 자체를 분리하거나 쪼개서 학습을 하게 된다면 전체적인 시스템 성능이 저하되는 결과를 만들게 됩니다. 학습을 진행하는 속도가 떨어지게 되기 때문입니다. 이러한 문제를 해결하기 위해서 Tensorflow에서는 Monitor API 를 제공하고 있습니다.
그럼 이제부터 로깅을 어떻게 하면 되는지, 그리고 연속적인 데이터를 평가하고 TensorBoard를 통해 데이터를 시각화하기 위해서 무엇을 해야하는지를 알아보겠습니다.
Enabling Logging with TensorFlow
TensorFlow에서는 5가지의 로깅 타입을 제공하고 있습니다. ( DEBUG, INFO, WARN, ERROR, FATAL )
순차적으로 상위의 로깅 타입이 되며, 만약 로깅 설정시에 ERROR로 되어 있으면 ERROR와 FATAL 로그를 볼수있게 됩니다. 마찬가지로 DEBUG로 설정을 하게 되면 모든 타입의 로그를 볼수 있게 되어 있습니다.
기본 설정은 WARN으로 되어 있는데,
이것을 INFO로 변경하고자 하면 아래와 같이 설정을 변경할 수 있습니다.
tf.logging.set_verbosity(tf.logging.INFO)
그런후에 다시 실행을 해보면 아래와 같이 다양한 로그들이 볼 수 있게 됩니다.
결과 내용의 중간쯤에 INFO 레벨 로그를 보면, tf.contrib.learn 에서 자동적으로 각 100 step 마다 loss 값을 출력하도록 되어 있는 것을 알수 있습니다. 그외에도 몇가지 로그들이 INFO로 보여지네요.
…
INFO:tensorflow:Create CheckpointSaverHook
INFO:tensorflow:loss = 0.0192276, step = 36001
INFO:tensorflow:Saving checkpoints for 36001 into /tmp/iris_model/model.ckpt.
INFO:tensorflow:loss = 0.0192274, step = 36101
INFO:tensorflow:loss = 0.0192069, step = 36201
INFO:tensorflow:loss = 0.0192045, step = 36301
…
INFO:tensorflow:loss = 0.0190661, step = 37901
INFO:tensorflow:Saving checkpoints for 38000 into /tmp/iris_model/model.ckpt.
INFO:tensorflow:Loss for final step: 0.0187804.
INFO:tensorflow:Transforming feature_column _RealValuedColumn(column_name=”, dimension=4, default_value=None, dtype=tf.float32, normalizer=None)
INFO:tensorflow:Restored model from /tmp/iris_model
INFO:tensorflow:Eval steps [0,inf) for training step 38000.
INFO:tensorflow:Input iterator is exhausted.
INFO:tensorflow:Saving evaluation summary for 38000 step: loss = 0.317697, accuracy = 0.966667
Accuracy: 0.966667
WARNING:tensorflow:float64 is not supported by many models, consider casting to float32.
INFO:tensorflow:Transforming feature_column _RealValuedColumn(column_name=”, dimension=4, default_value=None, dtype=tf.float32, normalizer=None)
INFO:tensorflow:Loading model from checkpoint: /tmp/iris_model/model.ckpt-38000-?????-of-00001.
Predictions: [1] , [1]
ValidationMonitor
이와 같이 심플하게 loss를 확인하는 것도 좋치만,
좀더 다양한 인사이트를 얻기 위해서는 Monitor API를 활용하는 것이 좋습니다.
Monitor API는 다음과 같은 몇가지 종류가 있습니다.
| Monitor | Description |
|---|---|
CaptureVariable | 학습단계에서 매 n step 마다 collection 내의 변수의 값을 저장합니다. |
PrintTensor | 학습단계에서 매 n step 마다 tensor의 값을 로깅합니다. |
SummarySaver | 학습단계에서 매 n step 마다 tensor의 Summary data를 SummaryWriter를 사용하여 파일 저장합니다. |
ValidationMonitor | 학습단계에서 매 n step 마다 evaluation metrics 구조를 로깅합니다. 혹은 특별한 조건이 되면 중지되도록 구현도 가능합니다. |
(참조 : https://www.tensorflow.org/versions/master/tutorials/monitors/index.html)
Evaluating Every N Steps
이 예제에서 학습과정 중에서 로깅을 하면서도 동시에 test dataset을 사용해 모델을 평가할 수 있는 방법이 있습니다.
바로 ValidationMonitor 를 사용하면 됩니다. 그리고 every_n_steps 옵션을 통해서 step 수를 지정해줄 수 있는데 기본값은 100입니다.
아래와 같이 Monitor 정의를 해주고 이 구문은 Classifier 상단에 위치하도록 해줍니다.
validation_monitor = tf.contrib.learn.monitors.ValidationMonitor(
test_set.data,
test_set.target,
every_n_steps=50)
그리고 Classifier에는 config 옵션을 추가해줍니다. 이것은 RunConfig를 통해서 checkpoint를 저장할 초단위를 지정해줄 수 있습니다. 여기서는 1초로 셋팅을 해주었는데요. 우리가 사용하는 예제 data가 매우 작기 때문입니다. 만약 큰 데이터셋을 사용한다면 적정하게 키워주어야 할 것 같습니다.
그리고 model_dir 옵션에서 model 데이터가 저장이 되는 디렉토리 경로를 지정할 수 있습니다. 이렇게 저장된 정보는 이 예제가 다시 실행이 될때 로딩이 되어 이전에 학습했던 내용 이후의 학습이 진행이 되게 됩니다. 만약, 이를 원치 않고 처음부터 다시 학습하기를 원한다면 실행하기 전에 해당 디렉토리를 삭제하면 됩니다.
# Build 3 layer DNN with 10, 20, 10 units respectively.
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model",
config=tf.contrib.learn.RunConfig(
save_checkpoints_secs=1))
마지막으로 fit 함수 옵션으로 monitors에 해당 validation_monitor를 지정해주면 모든 설정이 완료됩니다.
# Fit model.
classifier.fit(x=training_set.data,
y=training_set.target,
steps=2000,
monitors=[validation_monitor])
그런후 다시 예제를 실행해보면 다음과 같이 Validation 로그를 볼 수 있게 됩니다.
…
INFO:tensorflow:Validation (step 43651): loss = 0.334428, global_step = 43624, accuracy = 0.966667
INFO:tensorflow:Validation (step 43851): loss = 0.335053, global_step = 43846, accuracy = 0.966667
INFO:tensorflow:Saving evaluation summary for 44000 step: loss = 0.335488, accuracy = 0.966667
Customizing the Evaluation Metrics
위에서 알아본것과 같이 ValidationMonitor는 기본적으로 loss와 accuracy를 모니터링 할 수 있습니다. 만약에 여러분이 다른 통계적인 평가모델을 사용하고자 하면, tf.contrib.metrics module 을 활용하여 할 수 있습니다.
대표적인 통계적 함수는 streaming_precision 와 streaming_recall 이 있습니다.
현재 Tensorflow r0.11 버젼의 문서에 있는 해당 관련 내용은 사용이 안되는 버젼입니다. 이를 해결하기 위해서 많은 삽질을 했네요. 이 내용이 공식적인 내용이 아닐수도 있지만, 실행은 잘됩니다. 차기 버젼의 문서로 업데이트가 되면 다시 살펴봐야겠습니다.
아래와 같이 MetricSpec 을 import 해줍니다.
from tensorflow.contrib.learn.python.learn.metric_spec import MetricSpec
그리고 validation_metrics를 아래와 같이 지정해줍니다.
여기서 loss는 기본적으로 항상 monitor가 되도록 되어 있어 생략해주어도 됩니다.
key – value 형식으로 accuracy와 precision과 recall을 MetricSpec 객체를 이용해서 지정해 줍니다.
validation_metrics = {"accuracy" : MetricSpec(metric_fn=tf.contrib.metrics.streaming_accuracy
, prediction_key="classes"),
"precision" : MetricSpec(metric_fn=tf.contrib.metrics.streaming_precision
, prediction_key="classes"),
"recall" : MetricSpec(metric_fn=tf.contrib.metrics.streaming_recall
, prediction_key="classes")}
이제 다시 실행을 해보면 4가지 통계적인 평가 값이 출력되는 것을 볼 수 있습니다.
그런데 값이 조금 이상하게 출력되는 것을 볼 수 있습니다. recall과 precision이 항상 1.0으로 나오네요. 그리고 loss가 줄어가다가 마지막에 다시 커집니다. 이상하지요?
이를 해결하기 위해서 다음 내용에서 사용하는 early stop 기능을 사용해보도록 합니다.
..
INFO:tensorflow:Saving evaluation summary for 1 step: recall = 1.0, accuracy = 0.4, precision = 1.0, loss = 1.07354
INFO:tensorflow:Validation (step 50): recall = 1.0, accuracy = 0.4, global_step = 1, precision = 1.0, loss = 1.07354
…
INFO:tensorflow:Saving evaluation summary for 51 step: recall = 1.0, accuracy = 0.8, precision = 1.0, loss = 0.372704
INFO:tensorflow:Validation (step 100): recall = 1.0, accuracy = 0.8, global_step = 51, precision = 1.0, loss = 0.372704
…
INFO:tensorflow:Saving evaluation summary for 175 step: recall = 1.0, accuracy = 0.966667, precision = 1.0, loss = 0.10386
INFO:tensorflow:Validation (step 200): recall = 1.0, accuracy = 0.966667, global_step = 175, precision = 1.0, loss = 0.10386
…
INFO:tensorflow:Saving evaluation summary for 340 step: recall = 1.0, accuracy = 0.966667, precision = 1.0, loss = 0.061462
INFO:tensorflow:Validation (step 350): recall = 1.0, accuracy = 0.966667, global_step = 340, precision = 1.0, loss = 0.061462
…
INFO:tensorflow:Saving evaluation summary for 467 step: recall = 1.0, accuracy = 1.0, precision = 1.0, loss = 0.0574344
INFO:tensorflow:Validation (step 500): recall = 1.0, accuracy = 1.0, global_step = 467, precision = 1.0, loss = 0.0574344
…
INFO:tensorflow:Saving evaluation summary for 1438 step: recall = 1.0, accuracy = 0.966667, precision = 1.0, loss = 0.0649915
INFO:tensorflow:Validation (step 1450): recall = 1.0, accuracy = 0.966667, global_step = 1438, precision = 1.0, loss = 0.0649915
…
INFO:tensorflow:Saving evaluation summary for 2000 step: loss = 0.0685454, accuracy = 0.966667
Accuracy: 0.966667
Early Stopping with ValidationMonitor
ValidationMonitor 는 어떠한 조건에 맞는 상황이 되면 Early Stopping을 하기 위한 기능을 쉽게 사용할 수 있도록 제공해주고 있습니다.
이를 위해서 3가지 parameter가 제공되고 있습니다.
| Param | Description |
|---|---|
early_stopping_metric | early stopping을 수행할 특정한 조건 항목을 지정해줍니다. Default is "loss". |
early_stopping_metric_minimize | 이 값이 True 이면 early_stopping_metric 항목의 값이 최소값이 되면 stopping 준비를 합니다. False 이면 early_stopping_metric 항목의 값이 최대값이 되었을때 stopping 준비를 합니다. Default is True. |
early_stopping_rounds | 일정 시간 동안 early_stopping_metric_minimize 조건에 따라서 early_stopping_metric 값이 감소하거나 증가하지 않으면 학습을 stop 시켜줍니다. Default is N one. (early stopping을 사용하지 않음) |
(참조 : https://www.tensorflow.org/versions/master/tutorials/monitors/index.html)
이제 위의 3가지 param을 추가해서 아래와 같이 변경을 해보겠습니다.
아래 조건은 loss 값을 대상으로 하여 가장 작은 값이 되어 200 steps 동안 더 감소하지 않으면 stopping하도록 되어 있습니다.
validation_monitor = tf.contrib.learn.monitors.ValidationMonitor(
test_set.data,
test_set.target,
every_n_steps=50,
metrics=validation_metrics,
early_stopping_metric="loss",
early_stopping_metric_minimize=True,
early_stopping_rounds=200)
실제로 잘 동작하는지 실행을 해보면 아래와 같이 Stopping 로그와 함께 불필요한 추가 학습을 더이상 진행하지 않고 완료됩니다.
…
INFO:tensorflow:Saving evaluation summary for 1160 step: recall = 1.0, accuracy = 0.966667, precision = 1.0, loss = 0.0474243
INFO:tensorflow:Validation (step 1200): recall = 1.0, accuracy = 0.966667, global_step = 1160, precision = 1.0, loss = 0.0474243
INFO:tensorflow:Stopping. Best step: 900 with loss = 0.0467167161405.
INFO:tensorflow:Saving checkpoints for 1200 into /tmp/iris_model/model.ckpt.
INFO:tensorflow:Loss for final step: 0.0506959.
…
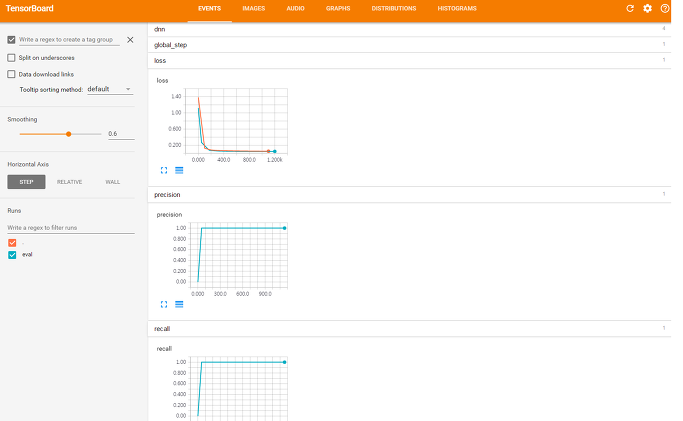
최종 결과를 TensorBoard 에서 확인해보면 다음과 같은 그래프를 볼 수 있습니다.
$ tensorboard –logdir=/tmp/iris_model/