
News & Events
[알고리즘 트레이딩/시장미시구조] 9. Madhavan 모형 (2) – 모수 추정

시장미시구조론 (Market Microstructure) – (9)
Madhavan 모형 (2) – 모수 추정
이전 시간에는 시장가 주문의 연속성과 관련된 Madhavan의 주가 모형을 설정해 보았다. 이번 시간에는 주가 모형에 포함된 모수들을 (Parameters : φ, Θ) 추정해 보고, 실제 코스피200 지수 선물의 틱 데이터를 이용하여 추정된 모수들의 특징을 분석해 보기로 한다.
아래의 1) 식은 이전 시간에 설정한 주가 모형이다. 현재 주가 (Pt)는 이전 주가 (Pt-1)에 거래비용 (φ), 정보의 비대칭 정도 (Θ), 시장가 주문 indicator (xt) 및 주문의 자기상관성 (ρ) 같은 거래 행위로 인한 변동 부분과, News와 같은 공공 정보의 발생으로 인한 변동 부분 (잔차 성분)으로 설명해 볼 수 있다. 여기서 xt 는 틱 데이터의 체결 정보를 이용하여 측정 가능한 값이고, ρ는 측정한 xt 를 이용하면 계산이 가능한 값이다. 따라서 추정할 모수는 φ, Θ 이며 잔차 성분이 최소가 되도록 추정해 볼 수 있다.
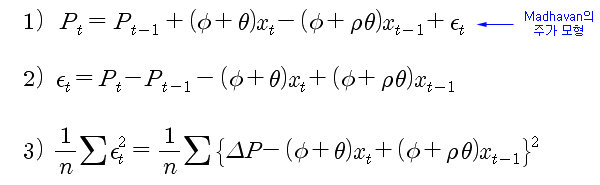
φ 와 Θ를 추정하기 위해서는 OLS (Ordinary Least Square), GMM (Generalization Method of Moments) 등의 수치해석 기법을 적용해 볼 수 있다. 여기서는 알고리즘 트레이딩을 염두에 두고, 실시간 추정을 위해 OLS 방법으로 공식을 (Closed form) 만들어서 추정해 보기로 한다.
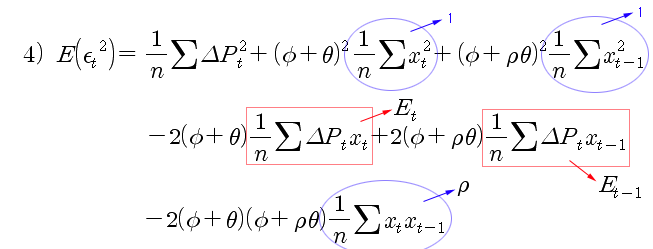
OLS 개념으로 식 1)의 잔차 성분의 제곱 평균이 최소가 되도록 φ 와 Θ를 추정한다. 잔차 성분은 식 2)로 표현할 수 있고, 잔차의 제곱 평균은 식 3)으로 표현할 수 있다. 식 3)의 우변을 모두 전개하면 식 4)가 된다. 식 4)에서 시장가 주문 indicator (xt) 의 제곱 평균은 1 이 되고 (xt 는 1 아니면 -1 이므로 제곱 평균은 1이 됨), 마지막 항의 indicator 곱의 평균은 ρ가 된다. 그리고 빨간색 박스 부분은 Et, Et-1로 정의한다 (표현의 간소화를 위해). 식 4)를 다시 정리하면 아래 식 5)와 6)이 된다.
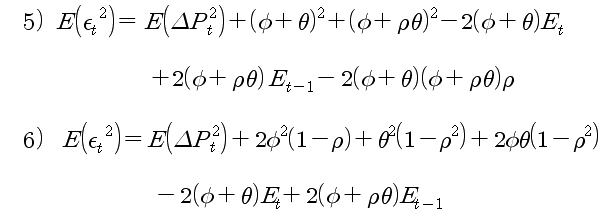
식 6)은 추정할 모수가 2개인, φ 와 Θ의 다중 회귀식 (Multi Regression)이므로, 잔차 제곱의 평균이 최소가 되도록 하려면, 아래와 같이 표현할 수 있다. 식 7)과 8)은 φ 와 Θ 이외는 모두 시장에서 측정 가능한 상수이므로 φ 와 Θ의 연립 방정식이 된다.

식 7), 8)의 연립 방정식을 풀면 식 9)의 결과를 얻을 수 있다 (연립 방정식은 역행렬을 이용 하였으며, 풀이 과정은 생략함). 식 9)의 결과는 체결 가격의 변화, 시장가 주문 indicator 그리고 indicator의 자기상관계수를 이용하여 거래 비용 (φ)과 정보의 비대칭 정도 (Θ)를 측정할 수 있는 식이 된다. 또한, Spread = 2(φ + Θ) 이므로 (이전 포스트의 식-3), 식 9)를 이용하면 시장의 Bid-Ask Spread를 계산할 수 있다.

이번에는 실제 시장 데이터를 이용하여 식 9)의 결과를 계산해 보고, 거래 시간대 별로 φ 와 Θ의 변화를 살펴보기로 한다. 특정일의 코스피200 지수 선물의 틱 데이터 중 체결 데이터 (A3, G7)를 관찰해 보았더니 약 50,000개 정도의 틱 데이터가 발생하였다. 이 데이터를 10,000 개씩 나누어서 φ 와 Θ를 측정해 보기로 한다. 아래 그림은 처음 10,000개 틱 데이터를 분석한 결과이다. 10,000개 틱이 발생한 시간대는 오전 09:00 ~ 09:34 이었다.
첫 번째 틱의 체결 가격은 265.70, 체결량은 -1 (매도 주문) 이었고, 세 번째 틱의 체결 가격은 265.80, 체결량은 +2 (매수 주문) 이었다. 체결량을 매수, 매도 indicator (xt)로 바꾸고 (체결량에 상관없이 매수 주문이면 +1, 매도 주문이면 -1), 체결 가격의 차이, indicator의 차이를 계산한다 (dp 와 dx). 그리고 식 4)에서 정의한대로 Et와 Et-1을 계산하고, xt의 자기상관계수 (시차=1)를 계산한다 (ρ = 0.371).
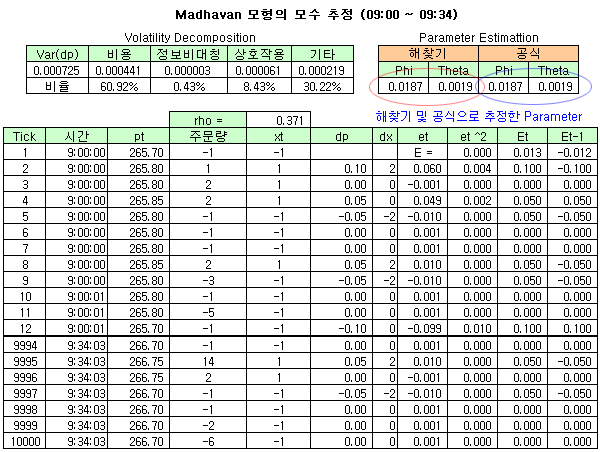
식 9)를 이용하여 φ와 Θ를 계산해 보면, 각각 0.0187과 0.0019가 나온다. 식 9)의 결과가 제대로 되었는지 확인해 보기위해 엑셀의 해찾기 기능으로도 추정해 보았다. 잔차 제곱의 평균을 계산하고 (et^2 의 평균), 이 값이 최소가 되도록 φ와 Θ를 추정해 보면 식 9)의 공식으로 계산한 결과와 잘 일치한다.
전체 50,000개 틱 데이터 중 나머지 40,000개에 대해서도 위와 동일한 과정으로 φ와 Θ를 추정해 보면 아래와 같다. 장 초반에는 거래의 활동성 (trading activity)이 매우 높아 10,000개 틱 데이터가 발생한 시간이 불과 34분 이었지만, 장 중반 이후에는 거래 활동성이 낮아져서 10,000개 틱 데이터가 발생하는데 2시간이 걸렸다.

시간대 별로 φ와 Θ를 추정해 본 결과, φ (거래 비용)는 장 초반에 높았다가, 장 중반으로 갈수록 감소하다가, 장 후반에 다시 상승하는 것으로 나타났다 (U-자형). 장 초반에는 주가 변동성이 높아 마켓메이커의 요구 프리미엄이 높아지고, 장 중반으로 갈수록 주가 변동성이 낮아져서 프리미엄이 낮아진다. 그리고 장 후반으로 갈수록 마켓메이커의 재고 보유 부담 (Overnight 대비)으로 인한 프리미엄이 추가되어 거래 비용이 다시 높아진다 (Madhavan 논문의 설명을 인용한 것임). Θ (정보 비대칭의 정도)는 φ에 비해 낮은 수치이며 (1/10 수준임), 시간대 별로 불규칙한 모습을 보인다. 따라서 Bid-Ask Spread는 φ의 영향을 받아 φ의 특성과 마찬가지로 U-자형의 모습을 나타낸다.
이번 시간에는 Madhavan의 주가 모형으로부터, 거래 비용과 정보의 비대칭 정도를 추정하여 시간대 별 특성을 살펴보았다. 다음 시간에는 주가 모형으로부터 변동성 모형을 설정하고, 주가의 변동성을 요인별로 분해하여, 어떤 요인이 주가 변동성에 큰 영향을 미치는지를 확인해 보기로 한다.
(2015.10.28 update) Madhavan 논문의 결과보다 Θ비중이 대단히 낮게 측정되었음. Madhavan 논문 등에서는 동일 주체에 의해 분할 체결된 주문은 1개의 주문으로 간주해야 한다고 언급하고 있으나, 거래소에서 제공하는 데이터로는 이를 확인할 수 없음. 위의 결과는 직전 주문과 현재 주문의 주체가 서로 다르다는 가정하에 분석한 것임. (참고 : 지수 옵션에서 관측한 결과 : http://blog.naver.com/chunjein/220522580766)
[출처]9. Madhavan 모형 (2) – 모수 추정|작성자아마퀀트
