
News & Events
[Machine Learning] 10. Feature를 선택하는 방법과 다항식 모델(Polynomial regression) 인 경우

Feature
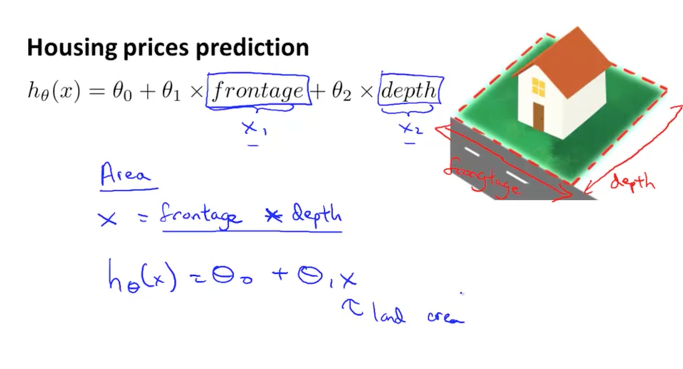
아래 그림과 같은 두개의 features가 있다고 생각해보겠습니다.
집의 사이즈를 나타내기 위한 폭과 넓이, 이 두가지 데이터가 있습니다.
features가 두개임으로 h함수는 아래와 같이 3개의 parameters를 갖는 함수로 표현이 됩니다.
여기서 우리는 이 두개의 features이 의미하고자 하는 정보를 다시 생각해볼 수 있을 것입니다. 결국 우리가 원하는 것은 집의 사이즈 정보이지 사이즈가 어떻게 구성이 되었는지는 별로 중요하지 않다는 것을 이해할 수 있습니다. 그러므로 이 두개의 features를 하나의 feature로 만들수 있다면 h 함수는 심플해질 것입니다.
같은 의미의 데이터가 중복되어 있다면 feature를 줄일 수 있는지 생각해 봐야겠습니다.
Polynomial regression (다항회귀)
h함수가 일차방정식이 아니라 다항식이 된다면 어떻게 될까요
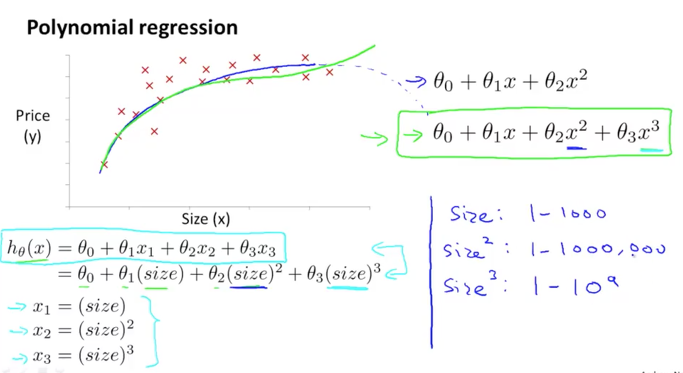
아래 그림에서와 같이 집의 사이즈에 따른 매매가격을 그래프로 표현을 했더니 직선(linear)의 형태로 나타나지 못하는 경우도 있을 수 있을 것입니다. 곡선과 같이 나타나는 이차방정식, 혹은 3차방정식의 dataset를 가지고 있다면 우리가 지금까지 배운 linear regression을 이용하지 못할까요
아닙니다. 단순히 features를 조정해서 할 수 있습니다.
아래 그림에서 보는 바와 같이 x1, x2, x3를 제곱, 세제곱의 값으로 만들어서 일차방정식이 되도록 할 수 있습니다.
feature를 변경하여 linear한 데이터로 변형하고 적용하는 것이 됩니다.
즉, 우리가 보유한 dataset의 feature를 조정하여 다항식을 일차방정식으로 만들면 우리가 지금까지 배운 h 함수와 J함수를 이용해서 Gradient Descent 알고리즘을 사용하여 머신을 학습시킬 수 있게 되는 겁니다
혹은 아래 그림의 그래프와 같이 이차방정식으로 표현이 되는 dataset을 보면,
집의 사이즈가 커지면서 곡선의 형태로 집의 가격이 상승하지만, 이차방정식은 곡선이 점선과 같은 그래프로 만들어지는데 실제 집값은 사이즈가 커지더라도 하락하지 않기 때문에 이는 잘못된 h 함수일 수 있습니다.
그래서 원점에서부터 곡선의 형태를 띄며 상승하는 그래프(오른쪽 아래 작은 그래프)와 같은 형태의 h 함수로 만드는 것이 더 나을 것 같습니다. 이 그래프는 제곱근 루트의 그래프입니다.
아래 식과 같이 이차항을 루트 사이즈로 변경할 필요가 있을 수 있습니다.
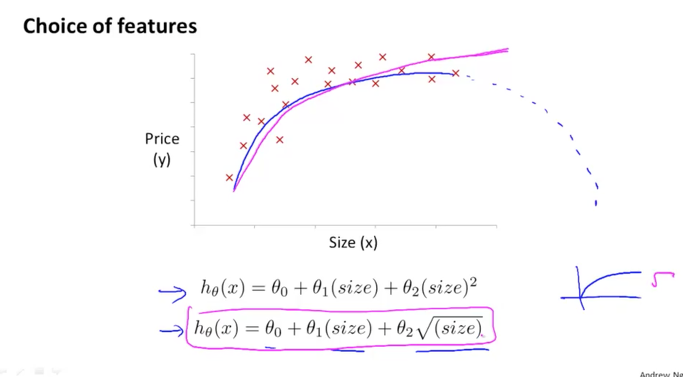
이와 같이 feature를 잘 선택하면 성능을 향상시킬 수 있으며 보다 심플하게 처리할 수 있게 됩니다.
또, feature를 잘 선택하면 다항식의 h함수를 심플한 일차방정식의 함수로 만들어 처리도 할 수 있게 됩니다.
이처럼 feature를 변경하게 되면 데이터의 범위가 상당히 커지거나 작아질 수 있으므로 scale 조정에 신중하게 접근을 해야 하겠습니다.
