
News & Events
[Machine Learning] 15. Supervised Learning – Classification 표현

지금까지 여러분은 머신러닝 학습 방법중에 하나인 Supervised Learning에서 regression을 처리하는 방법에 대해서 배웠습니다. 실제 구현까지 했으니 마스터 했다고 볼수 있습니다.^^
이제부터는 Supervised Learning에서 다른 분야인 Classification에 대해서 알아볼 차례입니다. 이제는 2강에서 살짝 다룬것과 같이 결과값을 예측하는 모델이 아니라 데이터를 분류하여 처리하는 모델에 대해서 알아보겠습니다.
Classification
Classification은 어떤 기준에 의해서 데이터를 처리하고 그 결과로 A 아니면 B 혹은 0 아니면 1로 분류가 되는(판단을 하는) 결과 값을 원할 때 사용되는 모델입니다. 예를 들어, 아래 그림과 같이 이 메일이 스팸인지 아닌지 여부를 판단하고자 하거나 어떠한 결과가 진실인지 거짓인지를 판단할때 또는 암이 악성인지 아닌지 여부를 판단하고 결정해야 하는 경우에 사용됩니다.
일반적으로 참,거짓으로 판단되는 것을 프로그램에서는 1이면 참(true), 0이면 거짓(false)로 표현을 합니다. 암의 진단 결과가 1이면 악성이다라고 판단하는 것이지요. 여기서 1을 Positive Class라고 하고 0을 Negative Class라고도 말합니다.
추후에는 2가지중에 하나가 아닌 여러가지중에 하나를 판단하는 케이스도 배우게 될 것입니다.

샘플 데이터를 보면서 이야기해보겠습니다.
빨간색 X 표시가 결과입니다. 암의 사이즈가 일정 수준 이상으로 커지면 악성이라고 판단하는 dataset입니다.
아래 그림에서와 같이 이것을 판단하는 기준을 직선을 그어서 할수 있을 것입니다. 직선이 0.5 포인트를 통과하는 것을 기준으로 삼아서 암의 사이즈가 그보다 크면 악성이다. 작으면 양호하다라고 말이지요.
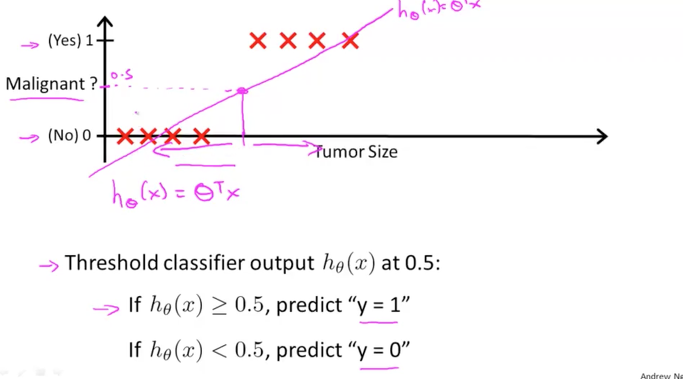
여기서 데이터중에 조금 쌩뚱맞는 것이 나타나서 맨 오른쪽에 사이즈가 엄청 큰 악성 암이 발견되었다고 가정을 해보겠습니다. 그럼 데이터가 범위가 넓어지므로서 직선이 파란색으로 더 기울어지는 것을 예상할 수 있습니다.
그렇게 변경된 파란색 직선이 통과하는 0.5의 기준 사이즈는 기존 빨간색 직선에서 보다 오른쪽으로 이동을 하게 되고 이것은 악성의 판단이 잘못되는 경우를 야기 시킬 것 같습니다.
이것은 잘못된 결과이므로 사용할 수 없는 것이 되겠습니다. 즉, Classification에서는 Linear Classification이 적용될 수 없다라는 결론이 나옵니다.
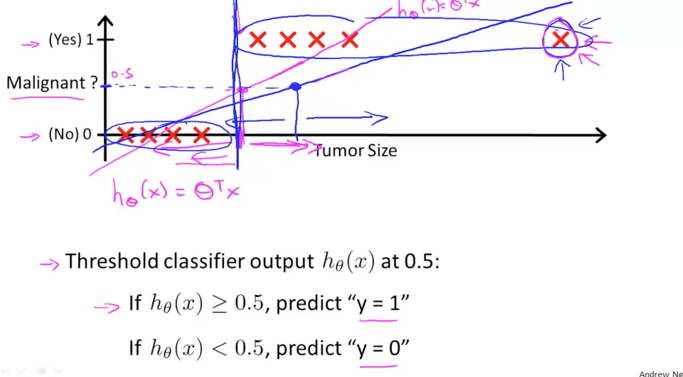
이번에는 h 함수를 확인해보겠습니다.
우리가 원하는 결과 값인 y는 0 아니면 1이 되어야 하는데 h 함수의 값은 0보다 작거나 1보다 큰 값이 된다고 합니다. 이것도 문제가 될 것 같습니다.
그래서 앞으로 우리는 이 h 함수가 0과 1사이가 되도록 하기 위한 Logistic Regression을 사용할 것입니다.
즉, Classification 모델을 처리하는 방법이 Linear Regression이 아니라 Logistic Regression이 되어야 하며 이제부터 이 모델에 대해서 배우도록 하겠습니다.

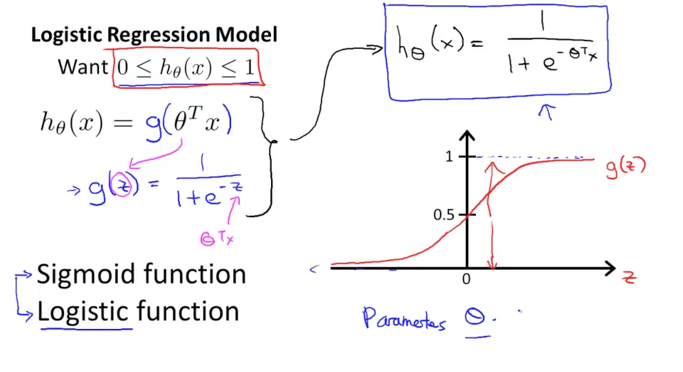
우리가 원하는 것은 h 함수의 결과 값이 0에서 1사이의 값으로 표현이 되어야 합니다. 그래야 어떤 기준점에서 1에 가까우면 참이다 라고 판단을 할 수 있을 것이기 때문입니다. 이것을 공식으로 표현하면 아래 그림에서와 같이 h 함수는 g의 함수가 됩니다. 그냥 g라는 함수로 감싸주었습니다.
이 g 함수는 아래와 같이 e를 사용하여 분수로 나타나지는 함수가 되며 이 함수의 이름을 Sigmoid 함수 혹은 Logistic 함수라고 불리웁니다. 두가지 이름은 동일한 의미를 지니며 그저 이름이 두 개씩이나 있는 함수가 되겠습니다. 그리고 이 함수를 그래프로 표현하면 아래 그림의 그래프와 같이 0에서 1사이에서 0.5값을 지나가는 S자와 비슷한 형태를 가지고 있습니다.
Hypothesis(h함수)의 결과는 곧 가능성을 의미합니다.
즉, x가 결정되었을때 y가 1이 되는 가능성이 얼마 정도임을 알려주는 것입니다.
만약에 h 함수의 값이 0.7로 나왔다면 이것은 최종 결과가 1일 가능성이 70%다 라고 말할 수 있습니다. 아래 그림의 예제에서는 의사가 환자에게 당신의 종양 사이즈로 판단을 해보았을때 악성일 가능성이 70%정도 됩니다. 라고 말할 수 있겠습니다.
이것을 수학적으로 표현을 하면 P(가능성)으로 표현을 할 수 있습니다. h 함수는 y=1이 될 가능성이 x와 theta에 의해 결정이 되며 그 결과값은 70%이다. 가 됩니다. 반대로 y=0이 될 가능성은 1 – (y가 1일될 가능성) 으로 표현도 가능합니다.

이제 Logistic regression에 대해서 정리를 해보겠습니다.
h 함수는 아래 그림의 식과 같이 표현이 되면 이것은 g의 함수로 감싸서 나타낼 수 있습니다.
이 함수는 그래프는 오른쪽과 같이 0과 1로 수렴하는 함수이며 0.5를 통과하는 S자 형태입니다.
y가 1이 되는 기준을 살펴보면 h 함수가 0.5보다 큰 값이 되어야 하고 그와 동시에 theta transpose * x의 값이 0보다 큰 값이 되는 것과 동일합니다. 반대로 y가 0이 되는 기준을 보면 h 함수가 0.5보다 작은 값이 되어야 하며 동시에 theta transpose * x의 값이 0보다 작으면 y가 0이 됨을 알수 있습니다.

그러면 이 y가 0인지 1인지를 판단하는 기준은 무엇이 될까요
이 기준을 Decision Boundary라고 합니다. 아래 그림의 예제 데이터에서 h 함수는 3개의 항을 갖는 g로 감싸진 함수라고 생각해봅니다. 여기서 theta를 임의로 -3, 1, 1의 Vector로 셋팅하였습니다. (이 theta를 알아내는 것이 곧 기준을 찾는 것이고 이것은 머신이 학습하여찾게 되는 것입니다.)
여기서에서 y가 1이 되는 기준은 theta Vector를 적용한 h 함수가 0보다 커지는 것입니다. 즉, 직선의 함수가 되어 왼쪽 그래프에서 직선으로 표기가 된 선이 되며 이 직선이 곧 Decision Boundary가 됩니다.

이번에는 데이터가 둥그렇게 퍼져있는 예제라고 생각해보겠습니다.
아래 그림에서와 같이 h 함수는 2차 방정식의 함수가 된다고 가정하고 theta vector를 임의로 생성하였습니다. 이경우에 y가 1이 되는 h 함수는 2차 방정식이 되어 그래프로 그리면 원과 같은 형태의 함수가 됩니다. 이때 이 원이 Decision Boundary가 되며 이것은 직선의 형태가 아님을 알수 있습니다.
이 원의 바깥쪽에 있으면 y 가 1이 되며 원 안쪽에 있으면 y 가 0이 된다고 판단할 수 있습니다.

더욱 복잡한 모델을 생각해보면 아래 그림의 그래프와 같이 원도 아니고 이상한 모양의 곡선으로 나타나지는 경우가 될 수도 있을 것입니다. h 함수도 3차 4차 방정식의 다항식으로 변해집니다.
이렇게 Decision boundary는 다양한 형태의 함수가 될 수 있다는 것을 이해하면 됩니다.
어떻게 이것을 찾고 h 함수를 만드는가는 다음에 다루게 될 것입니다.

