
News & Events
[Machine Learning] 16. Logistic Regression을 처리하는 방법

앞에서 Classification 를 하기 위해서는 Logistic Regression의 모델을 사용해야 한다는 것을 알아봤습니다.
이번에는 Logistic Regression에 대해서 하나씩 알아보겠습니다.
Cost function
우리가 사용하는 dataset은 아래 그림에서와 같이 한개의 feature와 결과 y로 구성이 됩니다. 그리고 m의 사이즈 만큼의 데이터가 존재하고 한개의 feature는 x vector로 표현을 할 수 있습니다.
앞에서 본것처럼 우리의 h 함수는 sigmoid function이 적용된 함수였습니다.
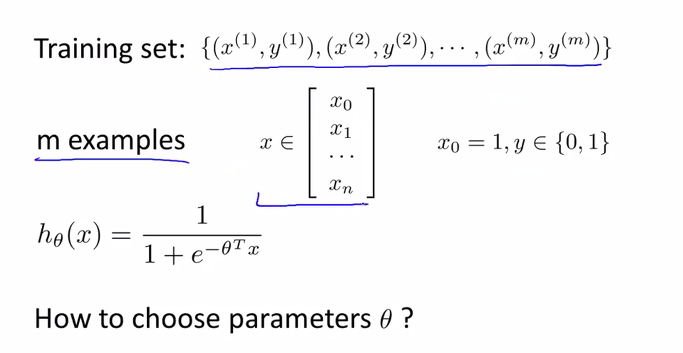
이제 Cost 함수를 만들어야 하겠죠?
앞서 배운 모델인 Linear regression에서의 Cost 함수 J는 아래 그림과 같이 공식으로 표현이 되었었습니다.
이 공식에 Logistic regression의 h 함수를 대입해서 적용을 해보려고 합니다. 어떻게 될까요
아래 그림의 왼쪽편에 그래프와 같이 non-convex한 함수가 됩니다. 왜냐하면 Logistic(sigmoid) 함수로 감싸야 했기 때문입니다. 이전 내용에서 배웠던 것입니다.
하지만 우리는 Gradient Descent Algorithm을 사용하기 위해서는 convex한 함수가 되어야 한다고 배웠습니다.(오른쪽 그래프와 같이 활모양의 함수가 convex 함수였습니다)
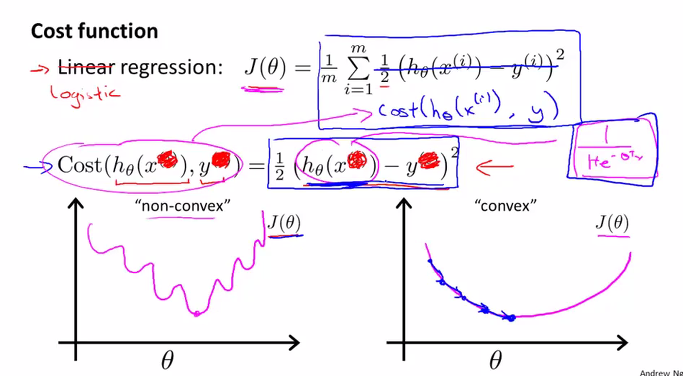
그 때문에 우리는 Cost 함수를 다르게 만들어야 합니다.
그래서 아래 그림의 Cost 함수와 같이 log의 함수가 되어야 합니다. 이 함수에 대해서 알아봅니다.
log 함수는 오른쪽 파란선의 그래프와 같이 0에서 마이너스 영역에서 시작해서 곡선을 그리면서 1을 지나가는 함수입니다. 이 log에 마이너스를 붙이면 빨간선의 그래프와 같이 뒤집어 집니다. 이 그래프 중에서 0~1사이만 취하면 왼쪽의 큰 그래프와 같은 함수가 됩니다. y=1일때 x가 0에 가까우면 무한대의 값을 가지고 x가 1에 가까우면 0의 값을 가지게 됩니다.
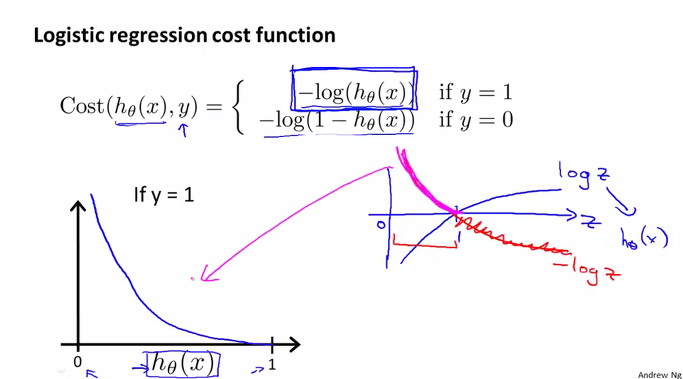
좀더 살펴보면, 이 log 함수는 y=1일때,
우리가 만든 h 함수의 예측값이 1이 나와야 하기 때문에 이때의 Cost는 0이 되고,
만약 h함수의 예측값이 0이 나온다면 이때의 Cost는 무한대로 커져서 우리가 찾고자 하는 minimize cost에 적합하다는 것을 알수 있습니다.

번에는 y=0일때를 살펴보면,
역시 -log(1-z)의 함수의 그래프는 오른쪽에 파란색의 그래프로 나타납니다.
이때도 마찬가지로 우리의 h 함수의 예측값이 0이길 기대하기 때문에 이때의 Cost는 0이 되고, 만약 예측값이 엉뚱하게 1이 나온다면 이때의 Cost가 무한대로 커지므로 우리가 원하는 Cost 함수에 적합하다는 것을 알수 확인할 수 있습니다.

위에서 배운것을 다시 정리하면 아래와 같이 공식으로 표현이 됩니다.
J 함수는 Cost 함수의 합이 되고, 우리의 Cost함수는 y가 1일때와 y가 0일때 각각 log의 함수가 되었습니다. 그리고 우리는 Classification을 원하기 때문에 y는 항상 0 아니면 1인 값만 가질 것입니다.

그런데 우리의 Cost 함수가 공식이 각각 2개로 나누어져 있어서 좀 애매합니다.
이것을 아래 그림의 공식과 같이 하나의 식으로 합칠 수 있습니다. 두 식의 앞에 각각 y와 (1-y)를 곱해주어 만들어졌습니다. y가 1일 때를 생각해보면 앞에 식은 y를 곱해주었기 때문에 그대로 남고, 뒤에 식은 (1-y)가 0이 되어 0을로 곱해지므로 뒤에 식이 사라집니다. 결국 우리가 원하는 위에 첫번째 식과 동일하다는 것을 알 수 있습니다.
마찬가지로 y가 0일때도 앞에 식에 0이 곱해져 사라지므로 이것 역시 두개의 식을 만족합니다. 결국 2개로 분리되어 있는 식을 하나의 식으로 합쳐놓은 것입니다.
이것이 우리의 Cost 함수가 되겠습니다.
실제로 이 J함수는 최대우도추정(maximum likelihood estimation) 원리를 이용해서 통계학적으로 만들어진 함수라고 하며, 이것은 features의 분포 관계에 대한 가우시안 가설(Gaussian assumption)을 기반으로 한다고 합니다.(통계학 나오니까 머리가 어질어질 하네요)

여하튼 우리가 원하는 것은 Cost가 가장 작은 케이스에서의 parameter를 찾는 것이므로 우리가 배운 알고리즘인 Gradient Descent가 적용이 가능한지 알아보겠습니다.
앞에서 다룬것처럼 J의 함수를 각각의 parameter로 편미분하여 세타의 함수를 생성하면 아래 그림의 세타의 공식처럼 표현할 수 있습니다. (h – y) * j 의 형태로 h함수는 조금 달라졌지만 파라미터의 함수는 Linear regression에서와 비슷한 형태가 됩니다. 이로서 우리는 Logistic regression에서도 동일하게 Gradient Descent 를 사용할 수 있게 되었습니다. 또, parameter인 세타의 업데이트는 동시에 이루어져야 한다는 것도 잊지 않으셨죠?

아래 그림에서와 같이 Linear regression에서와 Logistic regression에서의 Gradient Descent Algorithm이 달라진 것은 h 함수외에는 없습니다. 그러므로 사용이 가능하다는 것입니다.

Advanced Optimization Algorithm
이제 우리는 J함수와 이 J함수를 parameters로 편미분한 함수를 알고있습니다.
우리가 원하는 것은 minimize J를 찾는 것이며 이를 위해서 우리가 배운 알고리즘은 Gradient descent였습니다. 이 알고리즘을 사용해도 되지만 다른 더 좋은 알고리즘들도 있다고 합니다.
아래 그림의 왼쪽편에 리스트된 것과 같습니다.
Conjugate gradient
BFGS (Broyden-Fletcher-Goldfarb-Shanno)
L-BFGS (Limited memory – BFGS)
이러한 알고리즘은 더욱 빠르며 알파값(Learning rate)을 우리가 직접 선택하지 않아도 알아서 찾도록 되어 있어 보다 효율적인 장점들을 가지고 있습니다. 단점이라고 하면 조금 복잡한 알고리즘이라는 점입니다. 여기서 자세히 다루지는 않치만 이러한 알고리즘들을 사용해보면 좋을 것 같습니다.

예제입니다.
이 예제를 가지고 Octave에서 구현하는 것에 대해서 간단히 알아보겠습니다.
세타인 parameters가 2개가 있고, J 함수가 왼쪽 위 빨간 박스의 공식으로 주어졌습니다. 이를 편미분해서 그 아래 세타의 함수도 생성이 가능할 것입니다.
이것은 오른쪽에 Octave 함수로 구현을 할 수 있습니다. costFunction은 세타를 input으로 하여 gradient라는 2 by 1 Vector를 생성하고 1과 2에 대해서 연산하도록 되어 있습니다.
그리고 아래쪽에 구문들은 실제로 알고리즘을 수행시키는 내용들입니다.
options는 알고리즘에 입력할 옵션 데이터를 셋팅하는 것으로 앞에 두개의 입력값은 Gradient Objective parameter를 on하겠다는 의미이고 뒤에 두개의 입력값은 최대 100번 반복수행하겠다는 의미가 됩니다.
그리고 initialTheta는 parameters Vector로 생성하여 최종적으로 fminunc 함수에 입력값으로 함께 주어집니다.
fminunc 함수는 Octave에서 제공하는 함수로서 Gradient Descent와 비슷한 역활을 하는 알고리즘인데 알파를 우리가 직접 셋팅하지 않아도 되는 보다 upgrade된 알고리즘일 실행한다라고 생각하시면 됩니다.
이 예제를 실제로 돌려보시면 최종적으로 우리가 원하는 parameter 값을 리턴해줍니다. (세타one = 5, 세타two = 5)

costFunction에서 대해서 조금 살펴보면,
입력값으로 주어지는 theta Vector는 parameters로 구성이 되어 있고, Octave에서는 1-indexed Vector 프로그램이기 때문에 n+1개의 크기를 가지게 됩니다.
costFunction의 리턴 값은 jVal과 gradient 두개가 되며, 각각 J 함수를 연산하는 코드와 J 함수를 parameter로 편미분한 연산하는 프로그래밍 코드입니다.

이번에 알아본 Advanced Optimization Algorithm 들은 우리가 배운 기본이 되는 Gradient Descent 알고리즘보다 빠르고 효율적입니다. 복잡한 알고리즘들이라 그 내부를 알기 어렵고 디버깅하기도 보다 어려울 수 있겠지만 상당히 큰 dataset을 처리하기 유용하기 때문에 일반적으로 Gradient Descent보다 자주 사용된다고 하니 우리도 자주 사용해보도록 하면 좋을 것 같습니다.
