
News & Events
[Machine Learning] 9. Gradient Descent Algorithm 사용시 유의할 점

이번에는 Gradient Descent 알고리즘을 사용할때 유의할 내용에 대해서 알아보겠습니다.
Feature Scaling
이제 우리는 많은 features들의 data를 사용할 수 있게 되었습니다.
각각의 features는 다른 정보를 나타내는 값들이기 때문에 이 값들이 어떤것은 사이즈를 나타내어 단위가 1000단위로 표현이 되고 어떤것은 층수를 나타내어 1~10까지의 단위로 표현이 되기도 할 것입니다.
만약 이런 데이터들을 그대로 사용하면 어떻게 될까요
아래 그림과 같이 등고선의 형태가 각 feature의 단위에 따라서 홀쭉한 형태로 나타나거나 뚱뚱한 형태로 나타날 것입니다. 이렇게 되면 알고리즘이 목표로 하는 중앙의 점으로 찾아갈때 오래 걸리게 됩니다. 길 등고선을 따라 하강을 해야 하게 되기 때문입니다.
만약 이 feature가 동일한 단위(scale)을 가지고 있을 수 있다면 오른쪽 그림과 같이 균형잡힌 형태로 나타나고 보다 빠르게 목표점을 찾아 갈 수 있을 것 같습니다. 이와 같이 scale을 맞추기 위해서는 각 feature의 max값으로 나누어 주는 방법이 있습니다. 그러면 모든 feature의 값들이 0에서 1이하인 값들로 변하게 될 것입니다 ( 0 <= x <= 1 )
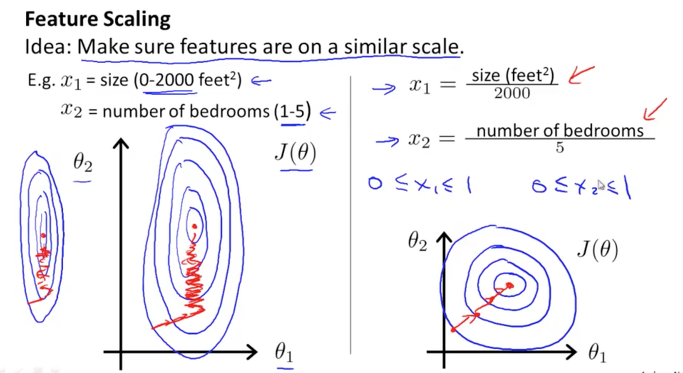
등고선의 중앙이 원점에 오도록 하기 위해서는 x가 -1에서 1사이의 범위를 갖는것이 좋을 것 같습니다
하지만 -100에서 100의 단위는 너무 크기 때문에 별로 좋은 범위가 아닙니다. 등고선이 엄청 뚱뚱해질 것이기 때문입니다.
혹은 -0.0001에서 0.0001의 범위는 너무 작기 때문에 등고선이 코딱지처럼 작아져서 미세한 움직임으로 동작될 것이기에 역시 좋치 않을 것 같습니다.
그래서 -3에서 3사이의 값을 갖도록 범위를 설정하는것이 가장 좋은 scale이라고 할 수 있습니다. 그러므로 데이터에 적당한 scale로 조정을 하면 보다 효율적으로 알고리즘이 동작되도록 할 수 있다는 것을 알아야겠습니다.

적정한 scale을 만드는 방법을 알아보겠습니다.
1번째 feature를 나타내는 x1은 집에 사이즈 데이터라고 생각해보겠습니다.
이 x1의 평균 값(avg)을 구해서 x1에서 빼고 난후 그 값을 다시 x1이 갖는 최고값에서 x1이 갖는 최저값을 뺀 값(range)으로 나누어 구할수 있습니다. 아래 그림의 공식이 이것을 의미합니다.(Mean normalization)
여기서 x0는 세타zero(상수 값)를 표현하기 위해서 1의 값(상수)을 가지고 있기 때문에 x0는 scaling에 대상에서 제외하도록 합니다

Learning Rate
Gradient Descent Algorithm에서 알파 값으로 불리우는 learning rate에서 유의할 점을 알아보겠습니다.
알파 값은 경사면을 하강하여 내려오는 발걸음의 폭과 같은 의미를 지닌다고 이전에 공부했었습니다.
이 알파 값이 잘 동작하는지를 판단하고 적정한 값은 얼마인지 알아보도록 합니다

J함수는 cost 함수였습니다.
이 J함수를 경사면을 따라서 하강을 하면서 최저점을 찾는 것이 목표이죠
아래 그림에서 학습을 100번 돌았다고 했을때의 J함수의 결과값과 200번 돌았을때의 J함수의 결과값을 보면 cost가 감소한 것을 알 수 있습니다. 이렇게 cost가 감소하다가 어느 수준이 되면 평평하게 이동하는 것을 볼 수 있습니다.(300-400구간)
그리고 cost가 0.001정도가 되면 우리의 목표에 도달했다고 판단할 수 있는 수준이라고 합니다. 0이 되면 좋겠지만 0이라는 의미는 실제 값과 100%로 동일한 결과를 항상 줄 수 있다는 뜻이기 때문에 현실적이지 않을 것입니다.

위와 같은 그래프로 나타나면 정상적인 알파 값을 가지고 동작하고 있다고 볼 수 있는데 반면에,
아래와 같이 상승하는 그래프(cost가 커지는 현상, diverge)이 발생하거나 상승하락을 반복하는 형태로 나타난다면 이것은 알파 값이 크게 설정이 되었다는 의미가 될 수 있습니다. 그러므로 이러한 현상이 발생하면 알파값을 보다 작은 값으로 조절을 하는 것이 좋습니다.
알파 값이 충분히 작으면 경사면을 하강하면서 적절하게 cost가 낮아지겠지만 또, 너무 작은 값이되면 목적지까지 도달하는데 걸리는 시간이 상당히 길어지게 되니 주의해야 합니다
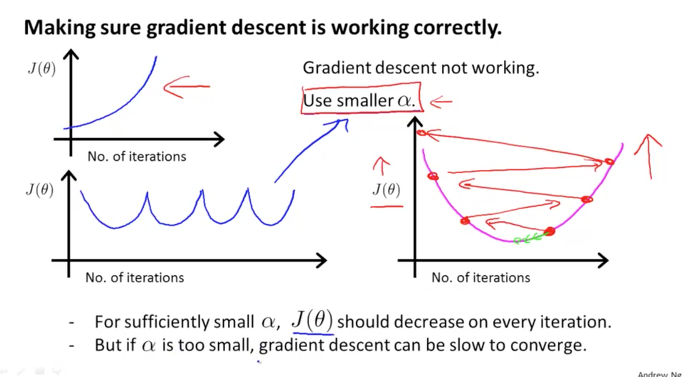
알파 값은 너무 작아도 또 너무 커도 안되며 적절한 값으로 조절을 해야합니다.
자신의 dataset에서 일부 작은 수의 약 10%수준의 데이터를 먼저 돌려보면서 조절을 해도 될 것 같고,
아래 그림의 하단부분에 있는 수치들과 같이 0.001에서 1사이의 값들을 사용해서 한번 실행시켜 보면서 큰 값 혹은 작은 값으로 변경해보고, 적절한 수준에 왔다고 생각이 들면 현재 알파값에서 3배로 조정을 하면서 미세조정을 하는 방법을 제시하고 있습니다.
cost가 충분히 빠르게 감소할 수 있고 알고리즘이 잘 동작할 수 있는 알파를 통해 학습 속도를 상향시키는 것이 좋겠습니다

