
News & Events
[Machine Learning] 27. 머신러닝 시스템을 디자인 하는 방법 (Machine Learning System Design)

지금까지 머신러닝에 대한 중요한 내용들을 배웠습니다.
이번에는 조금 다른 방향으로 생각해보려고 합니다.
스팸 메일을 분류하는 시스템을 만든다고 생각해 보겠습니다.
이 시스템은 분류(classification)에 대한 내용임으로 Supervised Learning에 속하는 문제가 됩니다.
이메일의 features를 x라고 하고 스팸인지 아닌지 여부를 y라고 합시다. (스팸은 1, 정상은 0)
이중에서 100개의 단어를 선택하여 이메일과 대조를 해보면서 각 features가 이메일 내용에 포함이 되어 있으면 1과 그렇치 않으면 0으로 표현을 할 수 있습니다. 아래 그림과 같이 x는 각 단어를 포함하는지 여부에 대한 vector가 될 것입니다. 100의 기본 단어로 시작을 했지만 점차적으로 5만여개까지 늘어날 수도 있을 것 같습니다.
여기서 선별된 100개의 단어는 reference vector 라고 합니다. 그리고 x는 feature vector 라고 합니다.
그리고 우리는 이와 같은 reference vector를 어떻게 선택했을까요. 우리가 가지고 있는 dataset에서 자주 나타나는 단어들을 그냥 선택했을 겁니다. 이것이 좋은 방법일까요?

또 다른 방법들도 있을 겁니다.
첫번째는 아주 많은 스팸 메일의 주소들을 수집하는 것입니다.(honeypot project에서 했던 것과 같습니다.) 그런데 실제적으로 크게 도움이 되지 못합니다. 스팸 메일 주소를 계속 동일하게 사용하는 스팸 발송자는 많치 않겠지요
두번째는 이메일이 전달되는 경로에 대한 정보를 분석해서 이상한 점을 찾아내는 것입니다. 보통 스팸메일들이 비정상적인 루트와 주소를 가지고 발송되기 때문이지요
세번째는 메일 내용에 이상한 단어들을 찾아내는 것입니다. 단어를 교모하게 사용하거나 비슷한 단어를 사용하거나 합니다.
네번째는 이상한 스펠링으로 된 단어들을 찾아내는 것입니다. 단어 필터링을 우회하기 위해서 스팸 발송자들이 비슷하게 생긴 문자를 섞어서 사용하는 것을 종종 발견하게 되기 때문입니다.
이와 같은 방법들은 스팸을 차단하고자 하는 알고리즘에 효과적일까요.
일반적으로 사람들은 일단 생각나는 대로 시도해보는 경향이 있습니다. 때로는 어느날 갑자기 번듯이는 아이디어가 생각나서 그것을 시도해 보려고 몇달을 보내는 경우도 생기게 됩니다. 또 어느날 갑자기 유행처럼 한 방향에 꼽혀서 모두가 달려가는 경우도 생깁니다. 이런 것들이 정말로 크게 도움이 될까요?

Error Analysis
위에서 살펴본것과 같이 스팸임을 판단하는 방법들이 꼭 나쁜것은 아니지만 그냥 감으로 적용해보고 결과를 확인하는데 소요되는 시간을 좀더 효율적으로 사용하기 위해서는 무언가 체계적인 방식이 필요할 것 같습니다.
머신러닝 시스템을 구상할때도 많은 문제들을 마주하게 되는데 보다 효율적인 방법에 대해서 알아보려고 합니다.
추천하는 접근 방식은 아래 그림에서와 같은 단계별로 진행을 해보는 것입니다.
처음 시작할때는 아주 빨리 그리고 심플하게 구현을 먼저 합니다. 약 하루정도안에 만들수 있는 정도의 수준으로 말입니다. 그리고 cv set을 이용해서 테스트를 돌려보는 것입니다.
그리고 그 결과를 learning curves의 그래프로 그려보고 이 시스템이 가지고 있는 문제가 high bias인지 high variance인지 확인하고 그에 적절한 조치 방안(이전에 배운대로 데이터를 늘리거나 features를 늘리거나 고차항을 도입하거나등)을 결정하여 진행하는 것입니다.
그 다음으로 실제 사람이 하나씩 결과들을 검토해서 알고리즘이 발생한 에러들을 분석해봅니다. 이 에러의 문제가 어떤 특징이나 트랜드를 가지고 있는지 확인을 하는 것입니다.

스팸 메일에 대한 예제를 다시 보면서 구체적으로 이야기를 해보겠습니다.
500개의 cv set 데이터중에서 알고리즘이 약 100개의 이메일을 잘못 분류했다고 해봅니다. 그럼 직접 사람이 100개에 대한 내용을 확인하고 다음과 같은 정보를 수집하는 것입니다.
첫번째는 이 이메일들의 타입이 무엇인지 파악하는 것입니다. 그리고 어느 타입이 많은지를 파악하는 것입니다. 아래 예제에서는 패스워드를 훔치려는 스팸메일이 53개로 많았다고 합니다.
두번째는 이 스팸메일의 유형을 보다 잘 처리하기 위한 정보를 파악하는 것입니다. 이것이 features가 되겠지요. 아래 예제에서는 punctuation을 이용한 방법이 좋을 것 같다고 파악이 되었나 봅니다.
이와 같이 한 단계씩 문제를 확인하고 그 문제를 처리하고 그리고 나서 다음 단계로 나아가는 것이 좋습니다.

Numerical Evaluation
다시 비슷한 단어를 같은 단어로 처리하는 것이 좋을까? 에 대해서 생각해보겠습니다.
이런 류의 것들을 처리하는 좋은 방법이 있습니다. 바로 형태소 분석(stemming)을 통해 처리하는 것입니다.
그런데 이것을 적용하는 것이 좋을지 아닌지에 대하여 결정하는 것이 중요한데 그냥 감으로 하는 것이 아니라 실제 오류에 대한 변화를 수치적으로 평가하는 것이 좋습니다. 이것은 보다 효율적인 결정을 할 수 있게 해줄 것입니다.
아래 그림의 예제에서처럼 stemming을 적용 안했을 때는 5% 에러가 발생하고 적용했을 때는 3% 에러라고 하면 당연히 우리는 적용하는 것이 좋다는 것을 알 수 있습니다. 만약 또 다른 방법으로 대소문자 구분에 대한 알고리즘을 적용했을때 3.2% 에러라고 하면 이에 대한 것은 적용하지 않아도 될 것이라는 판단을 쉽게 할 수 있습니다.
이렇게 수치적으로 오류를 판단할 수 있으면 우리의 알고리즘이 무엇을 적용했을때 개선이 되는지 판단 할 수 있으며 어떤 방법을 적용하는 것이 효율적인지도 알 수 있게 됩니다.
그리고 이런 방식으로 Error Analysis 을 파악할때에는 cv set을 이용해서 테스트를 진행하는 것이 좋습니다.

skewed classes (Precision / Recall)
또 다른 한가지에 대해서 생각해 보려고 합니다.
아래 그림의 예제와 같이 암환자를 판별하는 알고리즘을 만들었습니다. 그리고 이 시스템을 test set으로 확인해보니 1%의 에러율을 보였습니다. 99%가 정확하다는 것은 대단한 결과이지요. 우리는 와 대단한 것을 만들었다고 행복할 것입니다.
그런데 한번 다시 보겠습니다. 실제로 암인 환자를 파악해 보니 전체중에서 0.5%만 암환자였습니다. 그럼 우리의 시스템이 정확도가 높은것이 맞을까요? 만약에 그냥 찍어서 ‘모든 환자는 암이 아니다’ 라는 시스템을 만들었다고 생각해보겠습니다. 그럼 이 시스템의 정확도는 99.5%가 나올 것입니다. 0.5%만 실제 암환자였으니까요. 이 시스템과 비교를 해보면 우리가 열심히 만든 시스템은 무려 0.5%나 덜 정확한 것이 되버리는 이상한 사태가 발생합니다. 뭔가 대단히 이상합니다.
이렇게 핵심 데이터가 소규모일때 발생되는 왜곡된 현상을 skewed classes라고 합니다. 이런 경우는 일반적인 오류 판별로는 찾아내기 쉽지 않기 때문에 특별한 방법이 필요할 것 같습니다.

그래서 Precision과 Recall이라는 개념이 나옵니다.
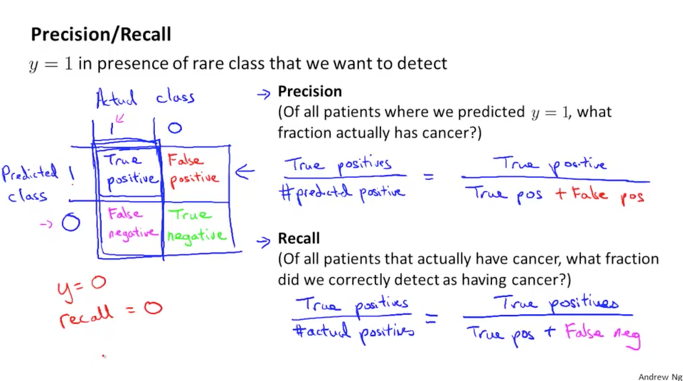
아래 그림에서와 같이 y가 1일때 즉, 실제 데이터상으로 암환자인데 시스템이 예측한 결과가 1로 나왔다면 정확한 결과가 됩니다. 그와 반대로 동일한 암환자인데 예측된 결과가 0으로 나왔다면 오류가 됩니다. 이것을 아래 왼쪽과 같이 분류하면 1,1 은 암환자를 암환자로 분류했으니 정상임으로 true positive가 되고 1,0은 암환자를 정상으로 오판했으니 false negative가 됩니다. 또 0,1은 정상인인데 암환자로 분류가 되었으니 false positive가 되고 0,0은 정상인을 정상인으로 분류했으니 true negative가 됩니다.
Precision 은 우리 알고리즘이 얼마나 오류를 냈는지에 대한 내용입니다. 이것을 비율로 나타내면 아래 그림의 공식과 같이 됩니다.
[ true pos / (true pos + false pos) ]
이 값이 1에 가까울수록 좋은 것입니다. false pos가 0이 될 수록 정확도가 높아지는 것이기 때문입니다.
Recall 은 우리 알고리즘이 가지는 민감도에 대한 내용입니다. 이것을 비율로 나타내면 아래 그림의 맨밑에 공식이 됩니다.
[ true pos / (true pos + false neg) ]
이 값도 1에 가까울수록 좋은 것입니다. false negative 즉 암환자를 정상인이라고 오판한 것이 0이 될 수록 실수가 없는 것이기 때문입니다.
이 두가지는 실제적으로 우리의 알고리즘이 얼마나 잘 동작하는지를 판단할 수 있는 유용한 지표임을 알 수 있습니다.
Trading Off Precision and Recall
precision과 recall은 둘다 실제적인 수치로 나타나기 때문에, 이 두가지 값은 서로 관계를 가지고 변화하게 됩니다.
이전에 배운 logistic regression에서는 1의 값을 판단하는 기준(threshold)을 0.5로 했었습니다. 0.5의 값보다 h 함수의 결과 값이 크면 1로 보고 반대로 작으면 0으로 분류를 했기 때문입니다.
만약에 이 threshold 값을 0.7, 0.9로 크게 잡는다고 가정해 보겠습니다. 암환자로 판단되는 결과가 어떻게 나타나게 될까요. 아래 그림과 같이 higher precision, lower recall로 나타날 것입니다. 즉 암환자에 대한 정확도는 올라가겠지만, 암환자를 오판하여 정상인으로 판단하는 비율이 커지게 될 것입니다.
반대로 threshold 값을 0.3으로 작게 잡았다고 가정해 보겠습니다. 그럼 결과도 반대로 나타나게 되겠습니다. higher recall, lower precision이 됩니다. 즉 암환자를 오판하는 경우는 작아지지만 정상인도 암환자로 판단하는 경우가 커져서 정확도가 떨어지게 될 것입니다.
이 threshold 값의 변화에 따라 precision과 recall이 나타내지는 값을 그래프로 표현하면 아래 그림의 오른쪽과 같이 됩니다.(파란색이 기본이나 시스템에 따라 다양하게 분홍색으로 나타날 수도 있습니다.) threshold 가 0.99로 1에 가까울 수록 precision이 같이 커지고, threshold 가 0.01로 0에 가까울 수록 recall이 커지는 것을 알 수 있습니다.

자 그럼 어떻게 좋은 알고리즘인지 여부를 판단할 수 있을까요?
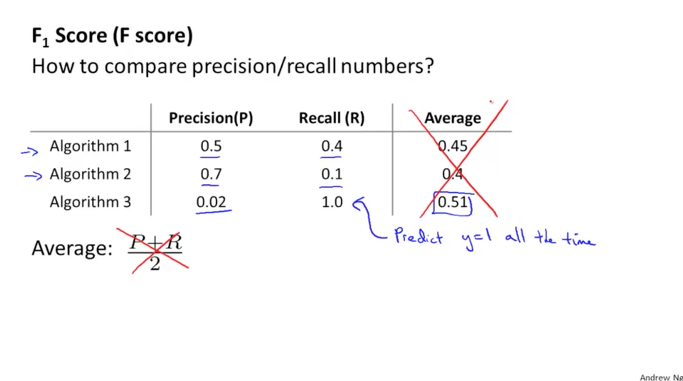
아래와 같이 3가지 알고리즘이 있습니다. precision(P)과 recall(R)의 값을 평균을 내고 그 값을 알고리즘별로 비교한다고 생각해보겠습니다. 아래 그림과 같이 3가지 알고리즘에 대한 평균 값이 큰 것을 보면 recall이 1로 그냥 모든 환자를 암환자라고 한것과 같은 알고리즘이 되겠습니다. 좋은 알고리즘이 아님에도 평균 값이 크게 나와서 정확한 판단의 기준이 될 수 없겠습니다.
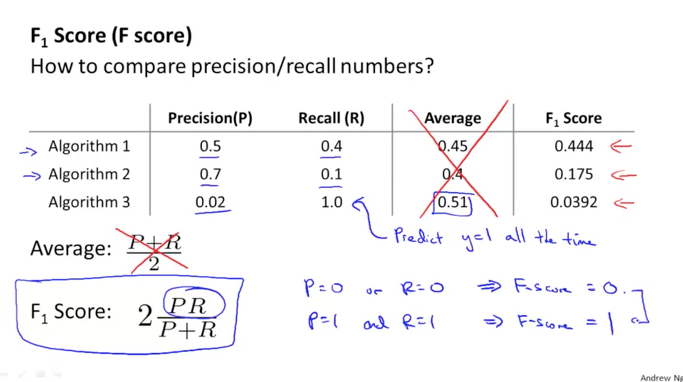
그래서 우리는 아래와 같이 F score를 사용하도록 합니다.
이 값은 보다 더 좋은 알고리즘을 판단할 수 있도록 도와줍니다. f score가 높은 알고리즘 1번이 적절한 precision과 recall 값을 나타내고 있으며 이는 또 적정한 threshold 값으로 판단하고 있다고 할 수 있습니다.
f score가 1이 되기 위해서는 precision과 recall이 동시에 1이 되어야 하며 이런 경우는 발생하지 않겠지만 높은 값일 수록 좋은 알고리즘이라는 것을 의미합니다.
Data For Machine Learning
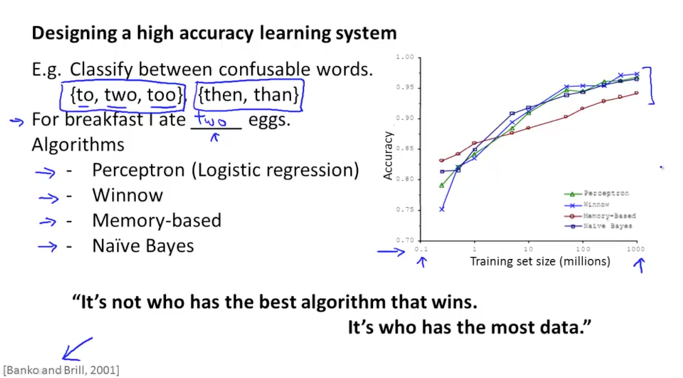
단어를 찾아 문장을 완성하는 머신러닝 알고리즘을 만든다고 할때 아래 그림의 목록과 같이 여러가지 알고리즘들을 사용할 수 있습니다. perceptron 은 우리가 배운 logistic regression과 비슷하고 winnow도 logistic regression과 비슷한데 최근에 많이 사용되지는 않는 알고리즘이라고 합니다. memory-based로 최근에는 많이 사용되지 않는다고 하고 Naive Bayes는 강의 후반에 다루게 될 알고리즘입니다.
이들의 알고리즘으로 예측한 결과에 대해서 분석해보면 오른쪽 그래프와 같이 나타나는데 알고리즘별로 결과가 큰 차이를 보이지 않는다는 것을 알수 있습니다. 그리고 또 한가지 중요한 것은 dataset이 커질 수록 더 좋은 결과를 보인다는 것입니다.
즉, 좋은 알고리즘을 사용하는 것보다는 적절한 데이터를 많이 보유하는 것이 더 좋은 결과를 나타낸다고 할 수 있습니다.
많은 데이터도 좋기는 하지만, 결과를 예측하는데 있어서 중요한 정보들을 많이 가지고 있는 것이 좋습니다.
사람이 어떠한 결과를 판단할때, 어떤 정보들을 이용해서 판단하는데 사용하는지를 생각해보면 좋은 정보(features)가 무엇인지 알 수 있을 것입니다.

이렇게 많은 데이터를 사용해서 알고리즘을 구성할때 많은 features를 처리하는 logistic regression 혹은 linear regresssion과 많은 수의 hidden units을 가지고 있는 neural network를 이용한다면 이들은 low bias algorithms들일 가능성이 있습니다. 그러므로 J train의 결과는 작은 값이 될 것입니다. 또 많은 수의 training set을 사용하면 overfit이 안되어 J test도 작은 값으로 J train의 값과 비슷하게 될 것입니다. 이전에 bias와 variance에 대해서 배운것 처럼 우리의 알고리즘은 어느 성향을 보이는지에 따라 알고리즘의 복잡도를 조절하거나 데이터의 양을 늘림으로서 좋은 결과를 나타내는 머신러닝 시스템이 될 수 있습니다.

