News & Events
[Machine Learning] 33. 자율적으로 학습하기 (Unsupervised Learning) : K-means algorithm

이번에는 Unsupervised Learning이 어떤 방식으로 Clustering을 찾는지 살펴보고 대표적인 알고리즘인 K-means algorithm에 대해서 알아보겠습니다.
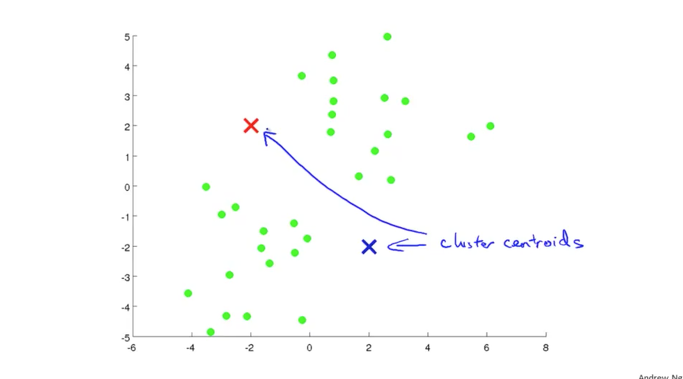
녹색으로 표기되는 x data 들이 그래프와 같이 분포가 되어 있고 임의의 2개의 지점에 파란색 X와 빨간색 X를 위치했다고 생각해보겠습니다. 이 두개의 X를 Cluster Centroids라고 하고 두 개의 cluster를 구성하는 중심점으로서의 역할을 하게 됩니다. 이렇게 원하는 Cluster의 중심점을 생성하여 특정 위치에 위치 시키는 것이 unsupervised learning에서 첫번째 과정이 되겠습니다.
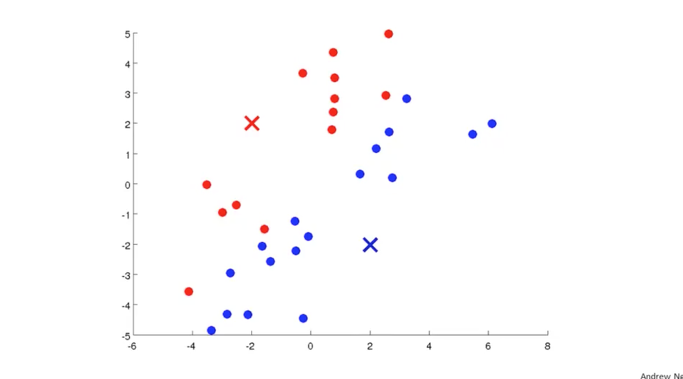
그렇게 위치시킨 두개의 cluster 중심점을 기준으로 근처에 있는 x data들을 색으로 구분을 해보겠습니다. 아래 그림과 같이 파란색과 빨간색으로 data들이 구분되어질 수 있습니다. 그리고 여기서 cluster 중심점을 살짝 이동시켜 보겠습니다.
파란색 X와 빨간색 X의 위치를 조금 변경하고 그 때를 기준으로 다시 근처에 x data들을 구분하여 색을 변경하면 아래와 같이 변하게 됩니다.
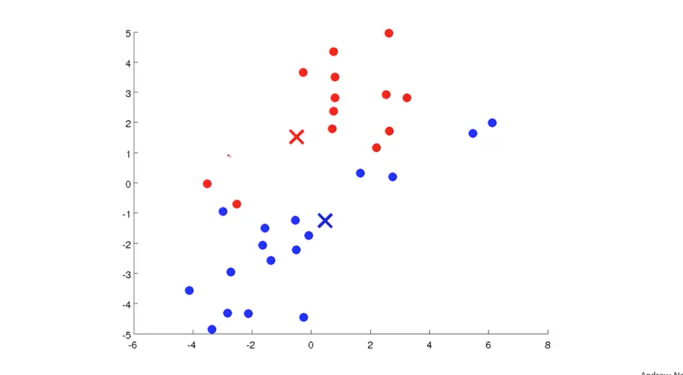
여러번 중심점들을 이동시키면서 아래 그림과 같이 위치하게 되면 x data들도 적절하게 구분이 되어가는 것을 볼 수 있습니다. 이렇게 Cluster centroids 를 적절한 위치로 이동시키는 것이 Unsupervised Learning의 두번째 단계가 됩니다. 이 두가지 단계를 통해서 학습을 하고 Clustering 된 결과를 얻을 수 있습니다.
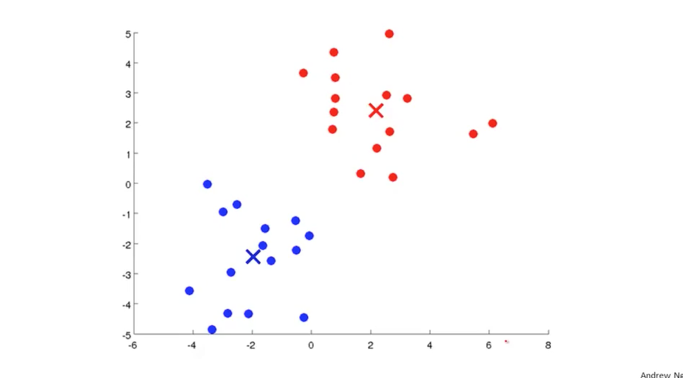
위와 같은 방식으로 K-means algorithm이 탄생하게 되었습니다. 이 알고리즘은 두가지의 입력값을 가지게 됩니다. 하나는 clusters로 구분되어질 수를 지정해주는 것입니다. 이 값을 대문자 K로 표시를 하겠습니다. 그리고 또 한가지는 입력 dataset인 x data들입니다.
그리고 이 x data들은 n개의 사이즈를 갖는 vector (n-dimensional Vector)로 표현이 가능합니다.

K개의 cluster로 구분을 한다고 가정을 할 때 Cluster centroid를 mu(뮤)라는 기호로 표기를 하며 1부터 K개 만큼의 (μK) 중심점이 존재하게 됩니다. 위에서 살펴본것과 같이 두가지의 과정을 아래 그림과 같이 구현을 할 수 있습니다.
첫번째 step인 Cluster assignment 에서는 1부터 m까지 반복하면서 x data가 어느 cluster centroid에 가까운지 체크하여 그 결과를 c(i)로 나타내게 됩니다. c(i)는 i번째의 x data가 몇번째 index의 Cluster에 속하는지를 의미합니다.
두번째 step인 Move Centroid 입니다. 1부터 K까지의 cluster centroids을 이동시키는 것입니다. 이때 각 cluster에 속하는 x data들을 평균 값을 구해서 그 위치로 이동을 하게 됩니다.
아래 그림의 예를 살펴보면, x(1), x(5), x(6), x(10)이 2번째 cluster라고 할때 c(1)=2, c(5)=2, c(6)=2, c(10)=2 의 값이 될 것이고, 이때 mu2 는 1/4 ( x(1) + x(5) + x(6) + x(10) ) 의 위치로 이동을 하게 됩니다.

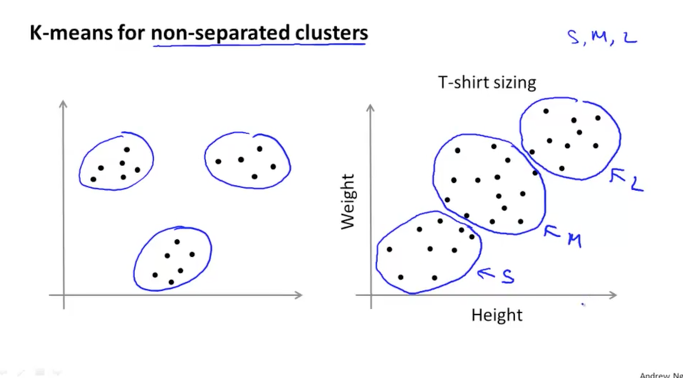
눈으로 보았을때 분리가 쉽게 되는 경우도 있겠지만, 아래 그림의 오른쪽과 같이 불규칙적인 data들로 구성이 되어 있더라도 clustering을 할 수 있습니다. 아래의 에제는 티셔츠의 사이즈를 예를 통해서 그래프로 표시를 한 내용으로 각 사이즈마다 small, medium, large로 구분이 가능하며 3개의 clusters로 생성하면 아래 그림에서와 같이 구분이 될 것입니다. 이러한 방식으로 x Segmentation에 이용하면 시장 점유율등을 나타내는데 유용하게 활용이 될 수 있습니다.