
News & Events
딥러닝을 이용한 주가 예측

인간 투자가가 성공할 수 있다면, 기계도 가능하지 않을까?

* 이 글은 towardsdatascience에작성된 Yacoub Ahmed의 글을 번역하였습니다.

이 포스팅는 전적으로 연구 목적의 프로젝트이다. 필자는 딥러닝을 배우고 있는 학생일 뿐이고, 프로젝트는 진행 중인 작업이다. 오늘 학습 할 알고리즘에 실제로 돈을 넣진 말자!
알고리즘 트레이딩은 주식 시장과 그 주변 산업에 혁명을 일으켰다. 현재 미국에서 일어나고 있는 모든 거래의 70% 이상이 봇에 의해 처리되고 있다[1]. 전화기에 대고 소리치며 종이 한 장을 흔드는 실무자들로 이루어지는 증권 거래의 시대는 지났다.
이는 어떻게 하면 주식을 거래할 수 있는 나만의 알고리즘을 개발하거나 적어도 주가를 정확하게 예측할 수 있을까? 하는 생각을 하게 했다.

Machines are great with numbers!
결과는 나름 나쁘지 않았다.

MSFT 주식 2019년 9월 -10월 거래 알고리즘
여름 동안 신경망과 머신 러닝에 대해 많이 배웠으며, 가장 최근에 배운 적용 가능한 ML 기술 중 하나는 LSTM 셀[2]이다.

LSTM 셀. Credit: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
롱숏텀 메모리 셀은 더 큰 신경망에서 메모리를 허용하도록 설계된 미니 신경망과 같다. 이는 LSTM 셀 내부의 반복 노드를 사용하여 달성된다. 이 노드는 무게가 1인 에지 루프 자체에서 되돌아온다. 즉, 모든 피드포워드 반복 시 셀은 이전 단계뿐만 아니라 이전의 모든 단계의 정보를 보유할 수 있다. 루프 연결의 무게가 1이기 때문에, 오래된 기억은 전통적인 RNN에서와 같이 시간이 지남에 따라 사라지지 않을 것이다.
결과적으로 LTSM과 반복 신경망은 과거를 기억하는 능력 덕분에 시계열 데이터를 잘 다룰 수 있다. 이러한 반복 노드에 이전 상태 일부를 저장함으로써, RNN과 LSTM은 현재 정보뿐만 아니라 네트워크가 1단계, 10단계 또는 1000단계 전에 보았던 정보에 대해서도 추론할 수 있다. 더 좋은 것은, LSTM 셀의 구현체를 직접 작성할 필요가 없다는 것이다. 텐서플로 케라스의 기본 레이어이다.
그래서 필자는 LSTM과 Keras를 주식시장을 예측하기 위해 사용하고, 돈을 벌기 위해 계획을 세웠다.
코드로 바로 들어가려면 GitHub repo를 확인해보자 🙂
데이터세트
주가 히스토리의 장점은 기본적으로 잘 표시된 데이터 세트라는 점이다. 몇 번의 구글 서치 끝에 AlphaVantage라는 서비스를 찾았다. AlphaVantage는 지난 20년 동안 나스닥 주식의 일일 가격 히스토리를 제공했다. AlphaVantage에는 오늘부터 1999년까지 매일의 시가, 고가, 저가, 종가, 거래량이 포함되어있다. 더 좋은 점은 서비스를 위한 파이썬 래퍼가 있다는 것이다. 필자는 웹사이트에서 무료 API 키를 받았고 마이크로소프트의 일일 주가 히스토리를 다운받았다.
AlphaVantage의 무료 API는 분당 5 콜(하루 최대 500 콜)만 허용하므로 데이터 세트를 다운로드하여 CSV 형식으로 저장하여 원하는 만큼 자주 사용할 수 있도록 하였다.
지난 20년 간 IPO 상장을 한 종목의 경우 거래 첫날이 거래량이 많아 이례적으로 보이는 경우가 많았다. 부풀려진 최대 거래량 값은 데이터를 정규화할 때 데이터 세트의 다른 볼륨 값이 어떻게 확장되는지에 영향을 미쳤기 때문에 모든 집합에서 가장 오래된 데이터 포인트를 삭제하기로 선택했다. 필자는 또한 모델이 거래가 언제 일어났는지 알 필요가 없기 때문에 날짜를 생략한다. 필요한 것은 주문된 시계열 데이터만 제대로 처리하면 된다.
필자는 또한 우리가 사용하고자 하는 {history_points}개의 숫자도 추적하고 있다. 그 모델이 예측을 기초로 삼을 수 있는 주가 히스토리 일수도 추적한다. 따라서 history_points가 50으로 설정되면 이 모델은 계속 학습되며 지난 50일 동안의 주식 히스토리가 다음날에 대한 예측을 하도록 요구된다.
이제 네트워크를 얼마나 빨리 통합하는지를 개선하기 위해 데이터를 0에서 1로 확장해야 한다. Sklearn은 이를 위한 훌륭한 사전 처리 라이브러리를 가지고 있다.
data_normalised는 정규화된 주가를 포함한다.
이제 모델을 사용할 수 있는 데이터 세트를 준비한다.
ohlcv_histories 리스트는 신경망 훈련 시 x 매개 변수가 될 것이다. 리스트의 각 값은 가장 오래된 값에서 최신 값으로 이어지는 50개의 시가, 고가, 저가, 종가, 볼륨 값을 포함하는 숫자 배열이다. 이 값은 슬라이스 작업 내에서 볼 수 있는 history_points 파라미터에 의해 제어된다.
따라서 각 x 값은 [i: i + history_points] 주가가 된다. 그러면 해당 값은 단수 [i + history_points] 주가여야 한다. 바로 다음날의 주가이다.
여기서 우리는 또한 우리가 예측하고자 하는 값이 무엇인지 선택해야 한다. 다음 날 시가를 예측하기로 결정했으므로 데이터의 모든 ohlcv 값의 0번째 요소를 구해야 한다. 따라서 data_scale [:,0].
또한 y_normaliser라는 변수를 보유할 수 있다. 이것은 예측의 마지막에 사용되며, 모델에서 정규화된 숫자를 0과 1 사이에 뱉을 때, 우리는 데이터 세트 정규화의 역방향을 적용하여 실제 값으로 다시 확장하고자 한다. 이후에는 또한 이를 사용하여 모델의 실제(비정상화) 오류를 계산할 것이다.
그런 다음 데이터를 Keras로 작업하기 위해 np.expand_dims()를 통해 y 배열을 2차원화한다. 그리고 마침내 필자는 나중에 결과를 모의할 수 있는 비균형적인 다음 날 시가를 얻을 수 있다.
데이터를 반환하기 직전에 x의 수 == y의 수를 확인한다.
이제 다음을 실행하여 csv 파일이 있는 모든 데이터 세트를 얻을 수 있다.
데이터 세트가 준비되어있다.
The Model
필자는 이 프로젝트를 순차적으로 Keras 코드를 작성하는 방법만 알고 시작했지만, 더 복잡한 네트워크 구조를 원했기 때문에 기능적인 API를 배우게 되었고, 결국 각 분기에 서로 다른 레이어 유형을 가진 두 개의 입력을 피쳐로 했다.
필자가 먼저 생각해 낸 가장 기본적인 모델도 검토해 보자.

Basic model architecture
각 입력 데이터 포인트는 [history_points × OHLCV]와 같은 배열이기 때문에 입력 레이어는 셰이프(history_points, 5)를 가진다. 이 모델에는 첫 번째 레이어에 50개의 LSTM 셀이 있으며, 과적합을 방지하기 위한 드롭아웃 레이어와 모든 LSTM 데이터를 결합하기 위한 일부 밀도가 높은 레이어가 있다.
이 네트워크의 중요한 기능은 선형 출력 활성화로, 모델이 자신의 최대 가중치를 정확하게 조정할 수 있다.
The Training
이것이 필자가 케라스를 사랑하는 이유이다. 말 그대로 3줄의 코드를 사용하면 모델이 데이터 세트에서 얼마나 잘 작동하는지 즉시 알 수 있다. 최종 평가 점수 0.00029를 받았는데, 이 점수가 너무 낮은 것 같지만 정규화된 데이터의 평균 제곱 오차임을 기억하자. 확장 후에는 이 값이 크게 증가하므로 손실에 대한 메트릭이 그리 크지 않다.
The Evaluation
모형을 보다 정확하게 평가하기 위해 검정 집합을 실제 값과 비교하여 예측하는 방법을 알아보자. 먼저 예측 값을 스케일업한 다음 평균 제곱 오차를 계산하지만, 이를 테스트 데이터의 ‘스프레드’ 즉 최대 테스트 데이터 포인트에서 최소값을 뺀 값으로 나눈 데이터 세트에 상대적인 오차를 만든다.
따라서 수정된 평균 제곱 오차는 7.17이다. 놀라운 것은 아니다. 평균적으로 예측된 선이 실제 선으로부터 7% 이상 이탈한다는 의미이다. 그래프에서 어떻게 보이는지 살펴보자.

Real and predicted daily opening stock price of MSFT from the last 500 days, basic network
나쁘진 않다! 예측 값이 실제 값보다 일관되게 낮은 이유는 잘 모르겠다. 테스트와 훈련 세트가 분할되는 방식과 관련이 있을 수 있다. 전체 데이터 세트의 결과는 다음과 같다.

Real and predicted daily opening stock price of MSFT since 1999, basic network
이 전체 그래프에서 알고리즘이 얼마나 잘 작동하는지 알기는 어렵지만, 예상대로 훈련 세트 전체에서 더 잘 맞는 것을 볼 수 있다.
The Improvements
우리는 모델을 더 복잡하게 만들고 데이터 세트의 크기를 늘릴 수 있다. 좀 더 복잡한 모델을 만드는 것부터 시작해보자.
주식 시장 애널리스트들이 흔히 사용하는 지표는 기술 지표[4]이다. 기술적 지표는 주가 역사에 대해 이루어지는 수학적 작업이며, 전통적으로 시장이 변화할 방향을 식별하는 시각적인 보조 수단으로 사용된다. 우리는 2차 입력 분기를 통해 이러한 기술적 지표를 받아들이도록 모델을 확장할 수 있다.
우선 간단한 이동 평균 SMA 표시기만 네트워크에 추가 입력으로 사용하자.
주식의 단순 이동 평균을 계산하려면 지난 n단계[5] 동안의 주식 종가 평균을 구하면 된다. 이는 주가 기록의 고정된 시간 블록을 이미 다루고 있기 때문에 우리에게 매우 효과적이다. SMA를 모델에 포함하려면 데이터 세트 처리 코드를 변경해야 한다.
이 문제는 ohlcv_history 및 next_day_open_values 배열을 정의한 직후에 발생한다. 우리는 모든 50 가격 블록의 데이터를 반복하여 3번째 열의 평균인 종가를 계산하고 그 값을 technical_ indicator 목록에 추가한다. 그런 다음 리스트는 나머지 데이터와 동일한 변환을 거치며 0 – 1의 값에 맞게 조정된다. 그런 다음 return 문을 변경하여 technical indicator와 이전에 반환한 다른 항목을 반환한다.
이제 모델을 확장하여 이 새로운 데이터 세트와 일치시킨다. 우리는 이전의 LSTM 구조를 사용할 수 있기를 바라지만 SMA technical indicator가 통합되기를 원한다. SMA는 시계열 데이터가 아니기 때문에 LSTM을 통해 전달하면 안된다. 대신에 우리는 최종 예측이 이루어지기 전에 혼합해야 한다. 끝에서 두번째의 64-노드 dense 레이어에 입력해야 한다. 따라서 우리는 두 개의 입력, 즉 연결 레이어와 하나의 출력을 가진 모델이 필요할 것이다.

Model architecture after augmentation to use technical indicators
technical_indicators.shape[1]을 tech_input layer의 입력으로 사용한 방법에 주목하자.
즉, 모델을 다시 컴파일할 때 추가되는 모든 새로운 technical indicator가 적합하다.
이 데이터 세트 변경과 일치하도록 평가 코드도 변경해야 한다.
[ohlcv, technical_indicators] 리스트를 모델에 입력으로 전달한다. 이 순서는 우리가 모델의 입력을 정의하는 방식과 일치한다.
그리고 우리는 2.25의 수정된 평균 제곱 오차를 얻을 수 있다! 훨씬 더 낮고 예측은 그림으로 표시된 검정 집합에 훨씬 더 가까운 것으로 보인다.

Real and predicted daily opening stock price of MSFT from the last 500 days, using SMA
이 모델은 정해진 양만큼 지속적으로 떨어져야 하는 기존 문제를 겪지 않고 급점프를 잡지 못해 어려움을 겪는 것으로 보인다. x 좌표 120에서와 마찬가지로 실제 가격에서 큰 폭의 점프와 하강이 발생하지만 모델은 이를 효과적으로 포착하지 못한다. 하지만 점점 좋아지고 있다! 그리고technical indicator가 앞으로 나아갈 길이 될 수 있을 것 같다.
좀 더 발전된 기술 지표인 이동 평균 수렴 차이를 포함해보자. MACD는 12주기 EMA[6]에서 26주기 지수 이동 평균을 빼서 계산한다. EMA는 다음 공식을 사용하여 [7] 계산된다.

MACD 표시기를 포함하도록 technical indicator 루프를 업데이트하려면:
SMA 및 MACD 인디케이터를 사용하여 우리의 모델은 2.60의 수정된 평균 제곱 오차를 달성한다. SMA만 사용하는 경우보다 약간 높다. 아래 그래프를 보자.

Real and predicted daily opening stock price of MSFT from the last 500 days, using SMA and MACD
SMA를 사용할 때처럼 정확하게 맞지 않는다는 것을 알 수 있다. 모델에 데이터를 더 많이 제공하기 때문에 더 많은 레이어가 필요하다. 하지만 지금은 MACD technical indicator의 사용을 생략할 것이다.
우리는 더 큰 데이터 세트를 사용하여 실험할 수도 있다. 마이크로소프트 주식의 주식 예측에 적용된 기법이 모든 주식으로 일반화될 수 있다고 가정한다면, 우리는 많은 다른 주식 히스토리에 대해 csv_to_dataset() 함수의 결과를 결합할 수 있을 것이다. 예를 들어, 우리는 AMZN, FB, GOOGL, MSFT, NFLX의 주식 히스토리를 훈련하고 AAPL 주식의 결과를 테스트할 수 있다.
먼저 사용하고자 하는 모든 주식에 대해 이 포스팅의 처음부터 다시 save_dataset 메소드를 실행한다. 데이터 세트 생성 방법은 다음과 같다.
기본적으로 현재 디렉터리의 각 csv 파일이 test_set_name 파일이 아닌 경우 해당 파일에서 데이터 집합을 로드하여 전체 데이터 세트에 추가한다. 그런 다음 test_set_name csv 파일을 로드하고 이를 테스트 데이터 세트로 사용한다. AMZN, NFLX, GOOGL, FB, MSFT의 주가를 이용하여 우리는 19854개의 훈련 샘플을 얻는다. AAPL 주식을 테스트 세트에 사용하여 4981개의 테스트 샘플을 얻는다.
SMA 인디케이터로 50 epoch에 대한 새롭고 더 큰 데이터 세트를 사용하여 훈련한 후, 우리는 하나의 주식에서만 훈련했을 때보다 더 높은 12.97의 조정된 MSE 값을 얻을 수 있다. 주식 예측이 실제 심볼에 따라 다를 수 있다. 서로 다른 주식이 약간 다른 방식으로 움직일 수 있다. 네트워크가 서로 다른 주식에서 훈련하고 일반화할 수 있었기 때문에 기본적으로 모두 비슷하게 행동한다는 것은 분명하지만, 가장 정확한 예측은 주식의 히스토리만을 훈련하는 것이 최선일 것이다. 결국, 마이크로소프트 데이터셋은 그것을 알아내기에 충분한 훈련 데이터를 가지고 있는 것 같다.
The Algorithm
괜찮은 주식 예측 알고리즘으로 무장한 필자는 그 주식의 히스토리을 고려해 볼 때 오늘 주식을 사고 팔기로 결정하는 봇을 만드는 순진한 방법을 생각했다. 본질적으로 당신은 다음날 주식의 시가를 예측하고, 만약 그것이 임계치를 넘으면 당신은 주식을 살 것이다. 만약 그것이 한계치보다 낮다면, 주식을 팔 것이다. 이 간단한 알고리즘은 실제로 꽤 잘 작동하는 것 같았다. 적어도 시각적으로는.

좋아 보인다! 알고리즘은 정확히 낮은 가격에 사고 높은 가격에 팔고 있는 것으로 보인다. 이 모든 것이 테스트 데이터, 즉 네트워크가 이전에는 보지 못했던 데이터라는 것을 기억하자. 이 데이터가 실제로 존재할 수 없었을 이유는 없으며, 이러한 거래는 실제로 실현된다!
이러한 매수와 매도를 고려할 때, 매 ‘매수’마다 10달러어치의 주식을 사들이고, 매 ‘매수’마다 전 주식을 판다면 알고리즘은 38.47달러를 벌었을 것이다. 하지만 500일 이상이라는 것을 명심하자. 알고리즘의 수익을 계산하는 코드는 다음과 같다.
만약 우리가 30일 동안 동일한 $10 구매 금액과 임계값 레벨 0.2를 사용하여 이 알고리즘을 시도했다면, 알고리즘은 겨우 $1.55를 벌었을 것이다. 하지만 없는 것보다는 낫지!
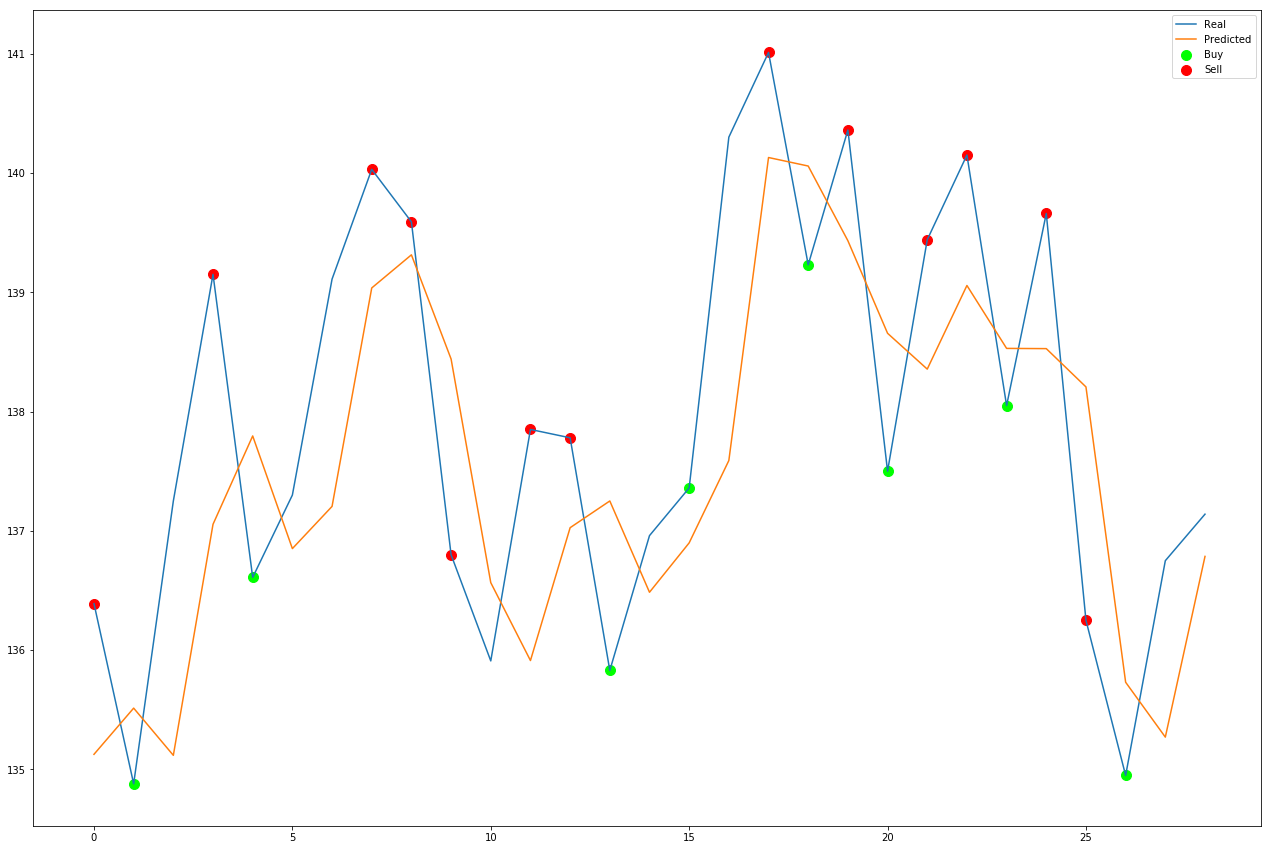
Trading algorithm for the MSFT stock over the past 30 days
The Conclusion
필자는 아직 예측 알고리즘에 대한 개선의 여지가 있다고 생각한다. 즉, 사용된 technical indicator, history_points 하이퍼 파라미터, 매수/매도 알고리즘/하이퍼 파라미터 및 모델 아키텍처가 모두 필자가 미래에 최적화하고 싶은 것이다.
AlphaVantage에서 사용할 수 있는 각 시간 단계마다 LSTM 분기가 하나씩 더 많아져서 네트워크가 단기, 중기 및 장기 추세에 따라 결정할 수 있도록 모델에 더 많은 데이터를 제공하는 방안도 검토하고자 한다.
이 프로젝트의 전체 코드는 필자의 GitHub에서 사용할 수 있다. 페이지에 피드백/개선 사항을 남겨 주세요!
필자는 이 프로젝트를 좀 더 확장해서 주식 예측을 위한 수치 데이터만으로 달성할 수 있는 것의 한계를 실제로 밀어붙일 계획이다.
References
[1]: https://www.experfy.com/blog/the-future-of-algorithmic-trading
[2]: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
[3]: https://jovianlin.io/why-is-normalization-important-in-neural-networks/
[4]: https://www.investopedia.com/terms/t/technicalindicator.asp
[5]: https://www.investopedia.com/terms/s/sma.asp
[6]: https://www.investopedia.com/terms/m/macd.asp
오늘 배운 딥러닝은 5월 29일(토)에 개설되는
[실시간 온라인] 파이썬과 케라스를 이용한 딥러닝/강화학습 주식투자
강의를 통해 심화하여 학습할 수 있습니다.
번역 – 핀인사이트 인턴연구원 강지윤(shety0427@gmail.com)
원문 보러가기>
