
News & Events
강화 학습을 이용한 주식 거래 자동화

* 이 글은 analyticsvidhya에 작성된 Ekta15의 글을 번역하였습니다.
도입
주식 시장에서 자주 들을 수 있는 말은 곰과 소다. 베어런(bearrun)은 장기간에 걸친 시장 가격 하락을 암시하는 용어이고, 불런(bull run)은 그 반대를 가리킨다. 이것들은 당일 거래를 거래하는 트레이더들이 사용하는 용어이다. 장중거래는 거래자가 같은 거래일 내에 금융상품을 사고팔아 그날 시장이 마감되기 전에 모든 시장 포지션이 폐쇄되는 증권 투기의 한 형태다. 많은 양의 금융상품이 인더데이 거래 방식을 통해 거래된다.
이것은 통상적인 무역 계획 및 뉴스 트렌드와 함께 작용해 왔다. 데이터 사이언스 및 머신 러닝의 등장으로, 다양한 연구 접근 방식이 이 수동 프로세스를 자동화하도록 설계되고 있다. 이 자동화된 거래 프로세스는 더 나은 계산을 통해 적시에 어드바이스를 제공하는 데 도움이 될 것이다. 뮤추얼 펀드와 헤지펀드는 최대 이익을 주는 자동화된 거래 전략이 매우 바람직하다. 예상되는 수익의 종류에는 어느 정도의 잠재적 위험이 따를 것이다. 수익성이 높은 자동화된 거래 전략을 설계하는 것은 복잡한 작업이다.
모든 사람은 주식 시장에서 최대한의 잠재력을 얻고 싶어한다. 대부분의 사람들에게 혜택을 줄 수 있는 균형 잡힌 저위험 전략을 설계하는 것 역시 매우 중요하다. 그러한 접근 방식 중 하나는 과거 데이터에 기반한 자동화된 거래 전략을 제공하기 위해 강화 학습 에이전트를 사용하는 것에 대해 말한다.
강화학습
강화 학습은 환경과 에이전트가 있는 머신 러닝의 일종이다. 이러한 에이전트는 보상을 최대화하기 위한 조치를 취한다. 강화 학습은 AI 모델 훈련을 위한 시뮬레이션에 사용될 때 매우 큰 잠재력을 가지고 있다. 데이터와 관련된 레이블은 없으며, 강화 학습은 매우 적은 데이터 포인트로 더 잘 학습할 수 있다. 이 경우 모든 결정은 순차적으로 내려진다. 가장 좋은 예는 로봇공학 및 게임학에서 찾을 수 있다.
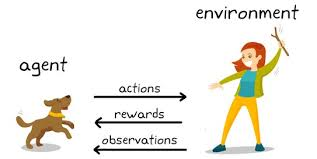
Q – 러닝
Q-러닝은 모델이 없는 강화 학습 알고리즘이다. 그것은 에이전트에게 상황에 따라 어떤 조치를 취해야 하는지 알려준다. 임박한 액션에 대한 정보를 에이전트에 제공하는 데 사용되는 값 기반 방법이다. q-러닝 함수가 임의의 작업을 수행하는 것과 같이 현재 정책 외부에 있는 동작에서 학습하므로 정책이 필요하지 않기 때문에 정책 외 알고리즘으로 간주된다.
Q 여기서 Q는 Quality를 나타낸다. 퀄리티는 조치된 보상이 얼마나 유익한지에 대한 행동 품질을 나타낸다. Q-테이블은 [state,action] 차원으로 작성된다. 에이전트는 exploit과 explore이라는 두 가지 방법으로 환경과 상호 작용한다. exploit 옵션은 모든 작업이 고려되고 환경에 최대값을 제공하는 작업이 수행됨을 나타낸다. explore 옵션은 미래의 최대 보상을 고려하지 않고 무작위 조치를 고려하는 옵션이다.
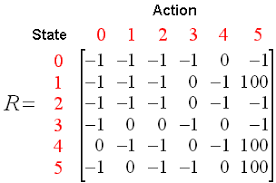

Q의 st과 at는 상태 s에서 수행되었을 때 최대 할인된 미래 보상을 계산하는 공식으로 표현된다.
정의된 함수는 훈련 주기 또는 반복 횟수가 끝날 때 최대 보상을 제공한다.
거래는 다음과 같은 콜을 할 수 있다. – 매수, 매도, 홀드
Q-러닝은 각 동작에 대한 등급을 매기고 최대값을 가진 동작을 추가로 선택한다. Q-Learning은 Q-table의 값을 학습하는 것을 기반으로 한다. 보상 함수와 상태 전이 확률 없이 잘 작동한다.
주식거래 강화학습
강화 학습은 다양한 유형의 문제를 해결할 수 있다. 거래는 엔드 포인트가 없는 지속적인 작업이다. 거래 또한 부분적으로 관찰 가능한 마르코프 결정 과정이다. 왜냐하면 우리는 시장에서 거래자에 대한 완전한 정보를 가지고 있지 않기 때문이다. 보상 함수와 전이 확률을 모르기 때문에 모델 없는 강화 학습인 Q-Learning을 사용한다.
RL 에이전트를 실행하는 단계:
- 라이브러리 설치
- 데이터 가져오기
- Q-Learning 에이전트 정의
- 에이전트 훈련
- 에이전트 테스트
- 콜 플롯
라이브러리 설치
필요한 NumPy, Panda, Matplotlib, Seaborn 및 Yahoo finance 라이브러리를 설치하고 가져온다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
!pip install yfinance –upgrade –no-cache-dir
from pandas_datareader import data as pdr
import fix_yahoo_finance as yf
from collections import deque
import random
Import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
데이터 가져오기
야후 파이낸스 라이브러리를 사용하여 특정 주식에 대한 데이터를 가져온다. 우리의 분석에 사용되는 주식은 인포시스 주식이다.
yf.pdr_override()
df_full = pdr.get_data_yahoo(“INFY”, start=”2018-01-01″).reset_index()
df_full.to_csv(‘INFY.csv’,index=False)
df_full.head()
이 코드는 2년 동안의 INFY의 주가를 포함하는 df_full이라는 데이터 프레임을 생성한다.
Q-Learning 에이전트 정의
첫 번째 함수는 에이전트 클래스로 상태 사이즈, 윈도우 사이즈, 배치 사이즈, 사용된 메모리, 인벤토리를 리스트로 정의한다. 또한 epsilon, decay, gamma 등과 같은 일부 정적 변수를 정의한다. 두 개의 신경망 레이어는 매수, 홀드 및 매도 콜에 대해 정의된다. GradientDescent Optimizer도 사용된다.
에이전트에는 매수 및 매도 옵션에 대해 정의된 기능이 있다. get_state 및 act 함수는 신경망의 다음 상태를 생성하기 위해 신경망을 사용한다. 이후 콜 옵션을 실행함으로써 생성된 값을 더하거나 빼서 보상을 계산한다. 다음 상태에서 수행되는 작업은 이전 상태에서 수행된 작업의 영향을 받는다. 1은 매수 통화를 의미하고 2는 매도 통화를 의미한다. 모든 반복에서, 상태는 일부 주식을 매수하거나 매도하는 조치를 취하는 것에 기초하여 결정된다. 전체 보상은 총 이익 변수에 저장된다.
df= df_full.copy()
name = ‘Q-learning agent’
class Agent:
def __init__(self, state_size, window_size, trend, skip, batch_size):
self.state_size = state_size
self.window_size = window_size
self.half_window = window_size // 2
self.trend = trend
self.skip = skip
self.action_size = 3
self.batch_size = batch_size
self.memory = deque(maxlen = 1000)
self.inventory = []
self.gamma = 0.95
self.epsilon = 0.5
self.epsilon_min = 0.01
self.epsilon_decay = 0.999
tf.reset_default_graph()
self.sess = tf.InteractiveSession()
self.X = tf.placeholder(tf.float32, [None, self.state_size])
self.Y = tf.placeholder(tf.float32, [None, self.action_size])
feed = tf.layers.dense(self.X, 256, activation = tf.nn.relu)
self.logits = tf.layers.dense(feed, self.action_size)
self.cost = tf.reduce_mean(tf.square(self.Y – self.logits))
self.optimizer = tf.train.GradientDescentOptimizer(1e-5).minimize(
self.cost
)
self.sess.run(tf.global_variables_initializer())
def act(self, state):
if random.random() <= self.epsilon:
return random.randrange(self.action_size)
return np.argmax(
self.sess.run(self.logits, feed_dict = {self.X: state})[0]
)
def get_state(self, t):
window_size = self.window_size + 1
d = t – window_size + 1
block = self.trend[d : t + 1] if d >= 0 else -d * [self.trend[0]] + self.trend[0 : t + 1]
res = []
for i in range(window_size – 1):
res.append(block[i + 1] – block[i])
return np.array([res])
def replay(self, batch_size):
mini_batch = []
l = len(self.memory)
for i in range(l – batch_size, l):
mini_batch.append(self.memory[i])
replay_size = len(mini_batch)
X = np.empty((replay_size, self.state_size))
Y = np.empty((replay_size, self.action_size))
states = np.array([a[0][0] for a in mini_batch])
new_states = np.array([a[3][0] for a in mini_batch])
Q = self.sess.run(self.logits, feed_dict = {self.X: states})
Q_new = self.sess.run(self.logits, feed_dict = {self.X: new_states})
for i in range(len(mini_batch)):
state, action, reward, next_state, done = mini_batch[i]
target = Q[i]
target[action] = reward
if not done:
target[action] += self.gamma * np.amax(Q_new[i])
X[i] = state
Y[i] = target
cost, _ = self.sess.run(
[self.cost, self.optimizer], feed_dict = {self.X: X, self.Y: Y}
)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
return cost
def buy(self, initial_money):
starting_money = initial_money
states_sell = []
states_buy = []
inventory = []
state = self.get_state(0)
for t in range(0, len(self.trend) – 1, self.skip):
action = self.act(state)
next_state = self.get_state(t + 1)
if action == 1 and initial_money >= self.trend[t] and t < (len(self.trend) – self.half_window):
inventory.append(self.trend[t])
initial_money -= self.trend[t]
states_buy.append(t)
print(‘day %d: buy 1 unit at price %f, total balance %f’% (t, self.trend[t], initial_money))
elif action == 2 and len(inventory):
bought_price = inventory.pop(0)
initial_money += self.trend[t]
states_sell.append(t)
try:
invest = ((close[t] – bought_price) / bought_price) * 100
except:
invest = 0
print(
‘day %d, sell 1 unit at price %f, investment %f %%, total balance %f,’
% (t, close[t], invest, initial_money)
)
state = next_state
invest = ((initial_money – starting_money) / starting_money) * 100
total_gains = initial_money – starting_money
return states_buy, states_sell, total_gains, invest
def train(self, iterations, checkpoint, initial_money):
for i in range(iterations):
total_profit = 0
inventory = []
state = self.get_state(0)
starting_money = initial_money
for t in range(0, len(self.trend) – 1, self.skip):
action = self.act(state)
next_state = self.get_state(t + 1)
if action == 1 and starting_money >= self.trend[t] and t < (len(self.trend) – self.half_window):
inventory.append(self.trend[t])
starting_money -= self.trend[t]
elif action == 2 and len(inventory) > 0:
bought_price = inventory.pop(0)
total_profit += self.trend[t] – bought_price
starting_money += self.trend[t]
invest = ((starting_money – initial_money) / initial_money)
self.memory.append((state, action, invest,
next_state, starting_money < initial_money))
state = next_state
batch_size = min(self.batch_size, len(self.memory))
cost = self.replay(batch_size)
if (i+1) % checkpoint == 0:
print(‘epoch: %d, total rewards: %f.3, cost: %f, total money: %f’%(i + 1, total_profit, cost,
starting_money))
에이전트 훈련
에이전트가 정의되면 에이전트를 초기화한다. 에이전트가 매수 또는 매도 옵션을 결정하도록 훈련할 반복 횟수, 초기 비용 등을 지정한다.
close = df.Close.values.tolist()
initial_money = 10000
window_size = 30
skip = 1
batch_size = 32
agent = Agent(state_size = window_size,
window_size = window_size,
trend = close,
skip = skip,
batch_size = batch_size)
agent.train(iterations = 200, checkpoint = 10, initial_money = initial_money)
결과–

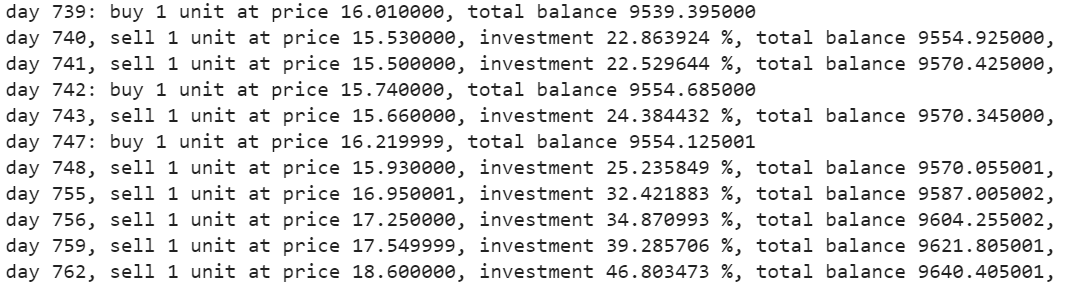
에이전트 테스트
매수 함수는 매수, 매도, 이익, 투자 수치를 반환한다.
states_buy, states_sell, total_gains, invest = agent.buy(initial_money = initial_money)
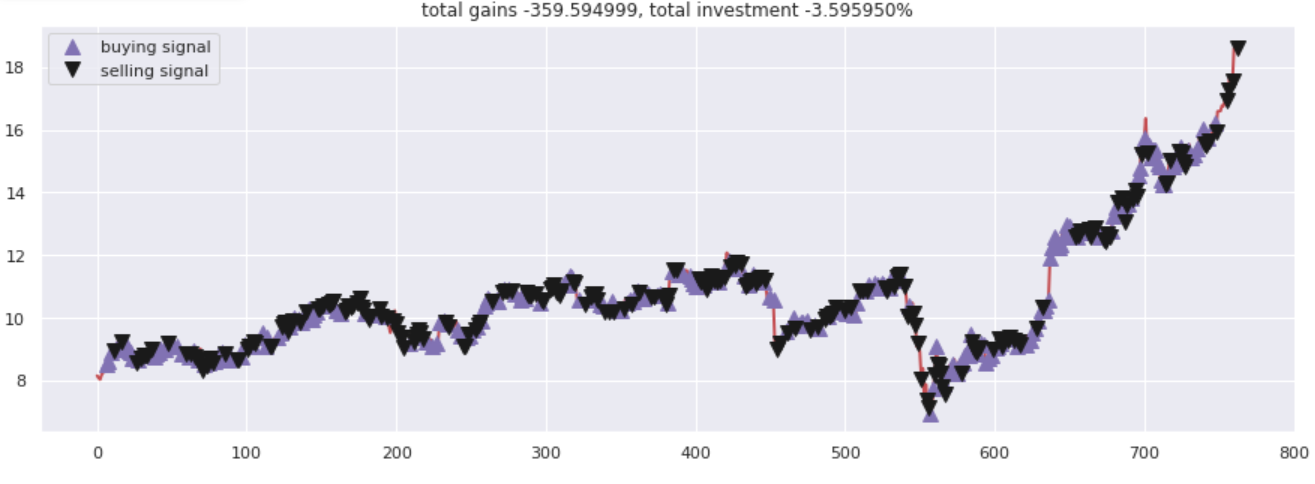
콜 플롯
총 이득 대비 투자된 수치를 표시한다. 모든 매수 및 매도 콜은 신경망에서 제안하는 매수/매도 옵션에 따라 적절히 표시되었다.
fig = plt.figure(figsize = (15,5))
plt.plot(close, color=’r’, lw=2.)
plt.plot(close, ‘^’, markersize=10, color=’m’, label = ‘buying signal’, markevery = states_buy)
plt.plot(close, ‘v’, markersize=10, color=’k’, label = ‘selling signal’, markevery = states_sell)
plt.title(‘total gains %f, total investment %f%%’%(total_gains, invest))
plt.legend()
plt.savefig(name+’.png’)
plt.show()
결과–
마무리
Q-러닝은 자동화된 거래 전략을 개발하는 데 도움이 되는 기술이다. 매수 또는 매도 옵션을 실험하는 데 사용할 수 있다. 실험할 수 있는 강화학습 거래 대행사가 많이 있다. 다른 종류의 RL 에이전트와 다른 주식으로 시도해보자.
오늘 배운 블록체인은 5월 29일(토)에 개설되는
[실시간 온라인/저자직강] 파이썬과 케라스를 이용한 딥러닝/강화학습 주식투자
강의를 통해 심화하여 학습할 수 있습니다.
번역 – 핀인사이트 인턴연구원 강지윤(shety0427@gmail.com)
원문 보러가기>
