
News & Events
머신 러닝이 주식 시장에 이용되는 방법

* 이 글은 medium에 작성된 MarcoSantos의 글을 번역하였습니다.
주식시장에서 머신러닝을 사용할 경우, ML 모델을 활용하기 위해 거래자가 할 수 있는 방법은 여러 가지가 있다. 미래의 위험을 결정하는 것에서부터 주가를 예측하는 것까지, 머신 러닝은 사실상 모든 종류의 금융 모델링에 사용될 수 있다.
이전 포스팅에서는 두 가지 시계열 모델인 SARIMAX와 Facebook Prophet에 대해 자세히 알아보았다. 우리는 비트코인의 잠재적 미래 가격을 예측하기 위해 이 두 가지 모델을 모두 활용했다. 관심이 있는 경우 다음 기사를 참고해보자.
https://towardsdatascience.com/predicting-prices-of-bitcoin-with-machine-learning-3e83bb4dd35f
또 다른 포스팅에서는 분류 모델을 사용하여 분기 보고서에서의 실적을 기준으로 주식을 분류했다. 아래 포스팅에서는 이러한 보고서와 다른 피쳐를 설계하고 분류 모델을 훈련하여 투자 결정을 내리는 방법에 대한 전체 프로세스를 읽어볼 수 있다.
https://medium.com/swlh/teaching-a-machine-to-trade-stocks-like-warren-buffett-part-i-445849b208c6
이것은 우리가 금융 시장에 머신 러닝 모델을 활용할 수 있는 방법의 몇 가지 예에 불과하다.
이 포스팅에서는 모델을 사용하여 미래의 가격을 예측했지만, 이는 절반에 불과하다. 다음 단계는 이러한 모델을 거래 중에 실제로 사용할 경우 어떻게 평가할 것인가? 그 질문에 대한 대답은 백테스트라고 불린다.
Backtesting
백테스트란 무엇일까? 백 테스팅(Back Testing)은 과거 데이터에 거래 전략, 예측 모델 또는 분석 방법을 적용하여 정확성과 성능을 평가하는 프로세스이다.
백테스팅이 100% 정확한 것은 아니며, 과거의 실시간 거래를 대표한다는 점을 유념해야 한다. 하지만 여러분은 전략을 생중계하기로 결정했는지 아닌지를 알리기 위해 그것을 사용해야 한다. 그렇더라도 실제 돈으로 거래하기 전에 전략을 미리 테스트하는 것이 더 실용적일 수 있다.
우리가 머신 러닝 모델을 만들 때, 우리는 과거 데이터를 공급함으로써 과거에 얼마나 잘 수행되었는지를 결정하기 위해 모델을 백테스트할 필요가 있다. 백테스팅에는 이벤트 기반 백테스트와 벡터화된 백테스트의 두 가지 접근 방식이 있다.
벡터화된 백테스트
오늘은 머신 러닝 모델의 성능을 평가하기 위해 벡터화된 백테스팅을 사용할 것이다. 이 접근 방식을 사용하면 과거에 ML 모델이 어떻게 수행되었는지를 신속하게 관찰할 수 있다.
벡터화된 백테스팅에 대해 자세히 알아보려면 현재 프로젝트의 결과에 기여한 머신 러닝 연구원의 다음 포스팅을 읽어보자.
Coding Our Machine Learning Model
머신 러닝 모델의 성능을 평가하기 위해서는 우선 파이썬으로 모델을 구성해야 한다. 우리가 사용할 모델은 pmdarima Python 라이브러리의 AutoARIMA 시계열 모델이다. 이 모델은 최적의
매개 변수를 신속하게 찾을 수 있으므로 모델링 매개 변수를 조정할 필요가 없다.
매개 변수에 대해 자세히 알고 싶다면 위에서 언급한 비트코인 가격을 예측하는 시계열 모델링을 사용하는 이전 포스팅을 확인해보자.
Step 1.필요한 라이브러리 임포트하기
import pandas as pd
import numpy as np
from pmdarima.arima import AutoARIMA
import plotly.express as px
import plotly.graph_objects as go
from tqdm.notebook import tqdm
from sklearn.metrics import mean_squared_error
from datetime import date, timedelta
import yfinance as yf
여기 있는 각 라이브러리는 ML 모델을 구축하고 다시 테스트하는 데 중요한 함수를 제공한다.
Step 2. 데이터 얻기
# Getting the date five years ago to download the current timeframe
years = (date.today() – timedelta(weeks=260)).strftime(“%Y-%m-%d”)
# Stocks to analyze
stocks = [‘GE’, ‘GPRO’, ‘FIT’, ‘F’]
# Getting the data for multiple stocks
df = yf.download(stocks, start=years).dropna()
# Storing the dataframes in a dictionary
stock_df = {}
for col in set(df.columns.get_level_values(0)):
# Assigning the data for each stock in the dictionary
stock_df[col] = df[col]
우리가 사용하게 될 자료는 약 260주간의 역사적 자료가 있는 주식 컬렉션이다. 우리는 우리 모델의 성능에 훨씬 덜 치우치기 위해 지난 몇 년 동안 가치가 떨어진 주식을 사용했다.
Step 3. 데이터 전처리
# Finding the log returns
stock_df[‘LogReturns’] = stock_df[‘Adj Close’].apply(np.log).diff().dropna()
# Using Moving averages
stock_df[‘MovAvg’] = stock_df[‘Adj Close’].rolling(10).mean().dropna()
# Logarithmic scaling of the data and rounding the result
stock_df[‘Log’] = stock_df[‘MovAvg’].apply(np.log).apply(lambda x: round(x, 2))
먼저 전체 수익률을 결정하기 위해 사용한 주식의 로그 수익률을 확인할 것이다. 다음으로, 데이터 세트에 10일 이동 평균이 적용되어 종가 노이즈를 완화하고 감소시켰다. 마지막으로, 우리는 소수점 2자리 반올림한 로그 척도를 사용하여 이동 평균을 스케일링했다.

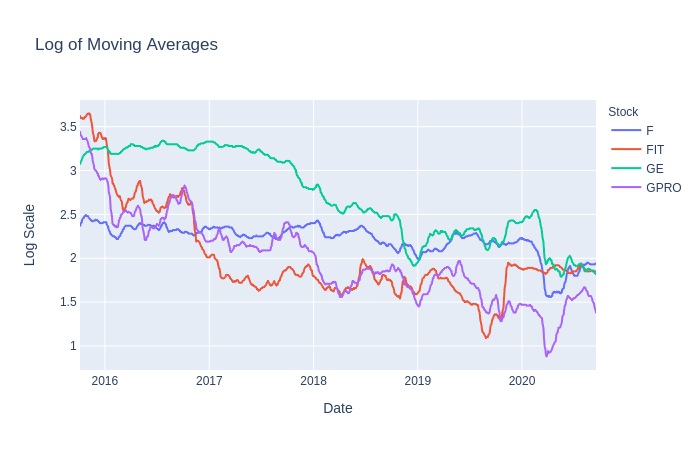
이동 평균과 로그 스케일링을 사용한 이유는 이러한 값이 우리의 모델에 더 적합하여 가격을 훨씬 더 정확하게 예측할 수 있기를 바라기 때문이다.우리의 모델에 공급할 데이터를 전처리하거나 변환하는 데는 정답이 없으므로 다른 스케일, 이동 평균 윈도우, 시가 등을 자유롭게 실험해 보자.
Step 4. AutoARIMA를 통한 훈련 및 예측
AutoARIMA로 예측하기 위해 모델을 실행하기 전 모델에서 원하는 모든 요구사항과 이를 달성하는 방법을 배치한다. 이러한 것들은 다음과 같다.
- 훈련 기간(일)—과거 종가 기준으로 약 반 년 분량의 데이터를 사용할 것이다.
- 예상 일수 – 향후 5일을 예상 금액으로 예측한 후 마지막 날을 거래 전략의 가격 목표로 사용할 것이다.
- 모델의 실행 시기와 실행 빈도 — 이틀에 한 번 또는 현재 가격이 목표가에 도달하거나 통과할 때마다 모델을 실행할 것이다.
- 평가하려는 날짜 범위—ML 모델을 백테스트 할 범위를 설정할 수 있다. 원하는 범위를 자유롭게 사용하되 범위가 클수록 훈련이 더 오래 걸릴 수 있다는 점에 유의하자.
모든 값들은 팅커링될 수 있다. 이 거래 전략에 가장 적합한 금액을 찾기 위해 다른 값을 얼마든지 사용해 보자.
위의 코드를 실행한 후에, 우리는 포트폴리오의 모든 주식에 대한 예측 DF를 받게 될 것이다. 이러한 예측은 백테스트에 사용하겠지만 먼저 시각화해 보자.
모형의 예측 시각화
# Shift ahead by 1 to compare the actual values to the predictions
pred_df = stock_df[‘Predictions’].shift(1).astype(float).dropna()
예측을 위한 새로운 DataFrame을 몇 가지 수정하여 생성해 보자. 우리는 예측을 하루 앞당겨서 우리의 예측이 전망 편향을 겪지 않기를 원한다.

우리는 우리의 모델이 충분히 잘 되는 것 같다는 것을 알 수 있지만, 그 예측은 마지막 예측일을 기준으로 한 것이며 우리의 거래 전략에서 가격 목표의 역할을 한다는 것을 기억하자.
예측 평가
이제 실제 값과 예측 값 간의 차이를 확인했으므로 루트 평균 제곱 오차를 사용하여 예측에서 얼마나 멀리 떨어져 있는지 확인함으로써 품질을 신속하게 평가할 수 있다.
for stock in stocks:
# Finding the root mean squared error
rmse = mean_squared_error(stock_df[‘MovAvg’][stock].loc[pred_df.index], pred_df[stock], squared=False)
print(f”On average, the model is off by {rmse} for {stock}\n”)
모형의 거래전략
우리의 모델에 대한 전략은 간단하다.
- Buy — 예측 가격 목표가 현재 가격보다 크게 상승하는 것을 나타내는 경우.
- Sell — 예측된 가격 목표가 현재 가격보다 현저한 감소를 보이는 경우.
- Hold (or Do Nothing)— 가격 목표가 현재 가격보다 크게 상승하거나 감소하지 않는 경우.
예시: 만약 우리가 모델을 10일 전에 예측하도록 설정한다면, 마지막 날의 예상 금액이 목표 가격이다. 만약 목표가가 103달러이고 현재 종가가 100달러라면, 그 주식은 향후 10일 이내에 가격이 3% 상승할 것으로 예상되기 때문에 우리는 그 주식을 살 것이다.
그러나 현재 가격이 예상보다 빨리 예상 가격 목표를 초과한다면 새로운 가격 목표를 위해 모델을 다시 실행할 수 있다.
위의 전략에 따라 백테스트에서 위치를 설정하는 기능을 만들어 보자.
def get_positions(difference, thres=3, short=True):
“””
Compares the percentage difference between actual
values and the respective predictions.
Returns the decision or positions to long or short
based on the difference.
Optional: shorting in addition to buying
“””
if difference > thres/100:
return 1
elif short and difference < -thres/100:
return -1
else:
return 0
모형 예측을 기반으로 하는 포지션
이제 우리의 함수를 사용하여 포지션을 확립하고, 우리는 모델 및 거래 전략의 백테스트 부분을 시작할 수 있다. 사용할 로그 리턴과 예측 값과 실제 값 사이의 백분율 차이를 포함하는 다른 데이터 프레임을 생성해야 한다.
“Positions” DF에서 발견한 경우, 우리는 일련의 위치를 2일씩 이동했다. 이것은 우리가 전날의 예측에 근거하여 거래일 말에 가까운 거래를 시작하기로 결정할 수 있는 상황뿐만 아니라 전망 편향을 감안하기 위해 행해진다. 만약 우리가 거래일 초에 거래를 시작하기로 결정한다면, 대신 하루만 자리를 옮기는 것이 괜찮을지도 모른다.
포지션 플로팅
백테스트에서 포지션을 확정하면 포지션 수, 포지션 유형, 소속 종목 등을 셀 수 있다. 이것은 우리의 전략이 각 포지션을 얼마나 자주 결정하는지 더 분석하기 위해 행해진다.
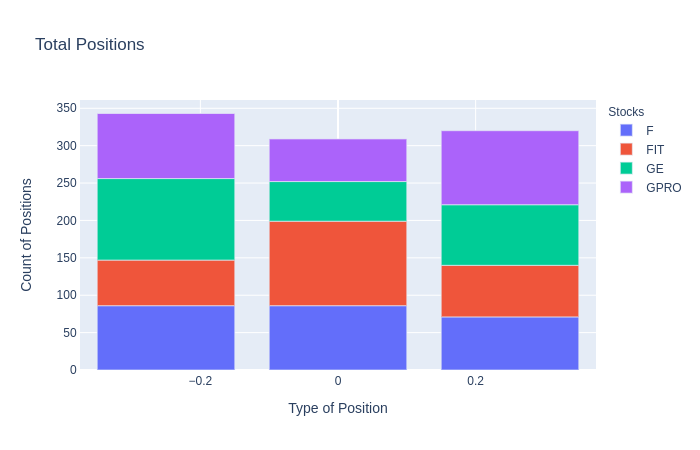
벡터화된 모형 백테스트
거래 데이터 프레임이 준비되면 벡터화된 백테스팅을 사용하여 각 개별 주식의 수익률과 전체 포트폴리오의 수익률을 신속하게 시각화할 수 있다.
각 주식에 대한 수익률
# Calculating Returns by multiplying the
# positions by the log returns
returns = trade_df[‘Positions’] * trade_df[‘LogReturns’]
# Calculating the performance as we take the cumulative
# sum of the returns and transform the values back to normal
performance = returns.cumsum().apply(np.exp)
# Plotting the performance per stock
px.line(performance,
x=performance.index,
y=performance.columns,
title=’Returns Per Stock Using ARIMA Forecast’,
labels={‘variable’:’Stocks’,
‘value’:’Returns’})
이 코드는 벡터화된 백테스트에 대해 다음과 같은 출력을 산출한다.

이 시각화를 통해, 우리는 ARIMA 모델 전략이 다른 주식에 비해 일부 주식에서 더 나은 성능을 보인다는 것을 알 수 있다. 대부분의 종목이 있는 상황에서 코로나바이러스가 시장에 미치는 영향으로 바로 3월경 큰 폭의 상승을 볼 수 있다.
포트폴리오 수익률
포트폴리오 수익률을 제대로 평가하기 위해서는 SPY와 결과를 비교해야 한다. 만약 우리가 SPY 수익률을 능가할 수 있다면, 우리의 모델은 가능성을 보여주며 전진 테스트나 실거래를 위해 고려될 수 있다. 결과는 다음과 같다.

보이는 것처럼 모델 초반에는 SPY에 비해 수익률이 떨어진다. 다만 코로나로 인한 주가 폭락이 시작되면서 SPY를 제치기 시작한다. 다른 결과를 얻고자 하는 경우 모델 내부와 전략 내에서 여러 가지 값을 얼마든지 변경할 수 있다.
맺음말
이 AutoARIMA 모델을 간단한 주식 거래 전략과 함께 사용했을 때, 우리는 SPY에 투자했을 때보다 더 나은 수익률을 달성할 수 있었다. 하지만 갑작스러운 주가 폭락으로 인해 결국엔 좋은 실적을 낼 수 있었다.
만약 우리가 다른 기간이나 다른 주식으로 다시 테스트했다면,
유사한 결과를 얻지 못했을 가능성이 매우 높다. 이 시점에서 모델의 실제 성능을 더 잘 이해하기 위해 이 전략을 향후 테스트하기 시작하는 것이 현명한 조치이다.
번역 – 핀인사이트 인턴연구원 강지윤(shety0427@gmail.com)
원문 보러가기>
https://medium.com/swlh/how-does-machine-learning-perform-in-the-stock-market-33bf214b67cf
