
News & Events
KeyBERT로 관련 키워드 추출하기



키워드 추출을 수행하는 많은 강력한 기술들이(예: Rake, YAKE!, TF-IDF)이 있다. 그러나, 주로 텍스트의 통계적 특성에 기초하며 전체 문서의 의미적 측면을 반드시 고려하는 것은 아니다.
KeyBERT는 이 문제를 해결하기 위한 사용하기 쉬운 키워드 추출 기법이다. BERT 언어 모델을 활용하고 트랜스포머 라이브러리를 사용한다.

KeyBERT는 Maarten Grootendors에 의해 개발되고 유지된다. 그러니 레포에 대해 알고 싶다면 그의 레포에 가서 확인해 보고 따라해보자. 이 포스트에서는 KeyBERT에 대해 간략하게 설명할 것이다. : 작동 방식과 사용 방법
PS: KeyBERT 사용 방법과 이를 Streamlight 앱에 내장하는 방법에 대한 비디오 튜토리얼을 보려면 아래 영상을 살펴보자.
KeyBERT: BERT로 구현되는 키워드 추출
pip을 사용하여 KeyBERT를 설치할 수 있다.
pip install keybert
트랜스포머 이외의 다른 소스에서 임베딩이 필요한 경우 다음과 같이 설치할 수도 있다.
pip install keybert[flair]
pip install keybert[gensim]
pip install keybert[spacy]
pip install keybert[use]
KeyBERT를 호출하는 것은 간단하다. 트랜스포머 모델을 기반으로 키워드 추출 모델을 초기화하고 extract_keywords 메서드를 적용한다.

KeyBERT는 어떻게 키워드를 추출할까?
KeyBERT는 다음 단계를 수행하여 키워드를 추출한다.
1 — 입력 문서는 사전 교육된 BERT 모델을 사용하여 내장된다. 트랜스포머에서 원하는 BERT 모델을 선택할 수 있다. 이는 텍스트 청크를 문서의 의미적 측면을 나타내는 고정 크기 벡터로 변환한다.
2 — 키워드 및 식(n-gram)은 TfidfVectorizer 또는 CountVectorizer 와 같은 Bag Of Words 기법을 사용하여 동일한 문서에서 추출된다. 이 단계는 과거에 키워드 추출을 수행한 적이 있는 경우 익숙할 수 있다.

3 — 각 키워드는 문서를 포함시키는 데 사용된 모델과 동일한 고정 크기 벡터에 내장된다.

4 — 이제 키워드와 문서가 동일한 공간에 표시되므로, KeyBERT는 키워드 임베딩과 문서 임베딩 사이의 코사인 유사성을 계산한다. 그런 다음 가장 유사한 키워드(코사인 유사성 점수가 가장 높음)를 추출한다.
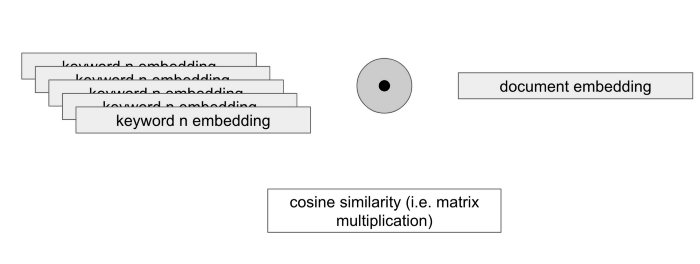
아이디어는 매우 간단하다: BERT 언어 모델이 의미 기능을 추가하기 위해 나오는 고전 키워드 추출 기술의 향상된 버전으로 생각할 수 있다.
여기서 멈추지 않는다: KeyBERT는 결과 키워드에 다양성을 도입하는 두 가지 방법을 포함한다.
1 — MSS
이 메서드를 사용하려면 top_n 인수를 20과 같은 값으로 설정한다. 그런 다음 문서에서 top_n 키워드 2개를 추출한다. 이러한 키워드 사이에 페어와이즈 유사성이 계산된다. 마지막으로, 이 방법은 서로 가장 덜 유사한 관련 키워드를 추출한다.
다음은 KeyBERT의의 예이다. 저장소:

2 —(MMR)이 메서드는 이전 방법과 유사하다. 다양성 인수를 추가한다.
MMR은 텍스트 요약 작업에서 중복성을 최소화하고 결과의 다양성을 극대화하기 위해 노력한다.
문서와 가장 유사한 키워드를 선택하는 것으로 시작한다. 그런 다음 문서와 비슷하면서도 이미 선택한 키워드와 비슷하지 않은 새 후보를 반복적으로 선택한다.
다음과 같이 낮은 다양성 임계값을 선택할 수 있다.

또는 높은 값:

지금까지는 좋았지만…
그러나 KeyBERT가 겪을 수 있는 한 가지 제한 사항은 실행 시간이다. 대용량 문서가 있고 실시간 결과가 필요한 경우 KeyBERT가 최상의 솔루션이 아닐 수 있다(운영 환경에 전용 GPU가 없는 경우). 그 이유는 BERT 모델이 특히 대용량 문서를 처리해야 할 때 거대하고 많은 리소스를 사용하기 때문이다.
소형 모델(DistilBERT)을 선택하거나, 혼합 정밀도를 사용하거나, 모델을 ONNX 형식으로 변환하여 추론 시간을 단축할 수 있는 몇 가지 해킹을 발견할 수 있다.
그래도 문제가 해결되지 않으면 다른 기존 방법을 확인해보자. 비교적 단순함에도 불구하고 그 효율성에 놀랄 것이다.
키워드 추출을 수행하는 경우 이 방법을 NLP 프로젝트에 유용하게 사용할 수 있기를 바란다.
아래에서 KeyBERT에 대해 자세히 알아볼 수 있다.
https://github.com/MaartenGr/KeyBERT
https://towardsdatascience.com/keyword-extraction-with-bert-724efca412ea
https://www.preprints.org/manuscript/201908.0073/v1
번역 – 핀인사이트 인턴연구원 강지윤(shety0427@gmail.com)
원문 보러가기>
https://towardsdatascience.com/how-to-extract-relevant-keywords-with-keybert-6e7b3cf889ae
