
News & Events


3가지 종목의 최적 포트폴리오 구축을 위한 강화학습 실험 및 포트폴리오 이론 기반 접근법과의 비교
강화 학습은 분명 인공지능 최고의 분야이다. 강화학습은 이미 그 위용을 입증했다. 세계를 놀라게 하고, 체스, 바둑 그리고 심지어 DotA 2 에서도 세계 챔피언을 제쳤다.
주식 거래를 위해 머신러닝을 사용하는 방법에는 여러 가지가 있다. 한 가지 접근 방식은 주가의 움직임을 예측하기 위해 예측 기법을 사용하고, 예측 결과를 사용하여 의사결정을 내리는 휴리스틱 기반 봇을 구축하는 것이다.
또 다른 접근법은 주가의 움직임을 살펴보고 직접 조치를 추천할 수 있는 봇을 구축하는 것이다. (매수/매도/보유) 이는 일반적으로 거래 종료 시에만 누적된 조치 결과를 알 수 있기 때문에 강화 학습을 위한 완벽한 활용 사례가 될 수 있다.
문제 상태
필자는 아래 질문을 포트폴리오 최적화 문제로 공식화할 것이다.
3가지의 서로 다른 주식의 히스토리를 고려할 때, 우리는 어떻게 수익 가능성을 극대화하기 위해 매일 이 주식들 사이에 정해진 양의 돈을 배분할 것인가?
목표는 포트폴리오 구축을 위한 정책(전략)을 개발하는 것이다. 포트폴리오는 기본적으로 다양한 주식에 걸친 가용 자원의 할당이다. 그런 다음 새로운 정보를 사용할 수 있게 되면, 정책은 시간이 지남에 따라 포트폴리오를 재구성해야 한다.

여기서 정책은 최적의 포트폴리오(할당)를 선택할 수 있어야 한다.
우리의 해결책은 강화 학습 모델을 개발하는 것이다. 이때 강화 학습 모델은 각 종목별 지표를 관찰하여 매 단계마다 주식을 할당하는 에이전트이다. 그런 다음 이 RL 정책을 마코위츠의 효율적 프론티어 접근법과 비교한다. 이러한 접근법은 아마도 대부분의 자산 관리자들이 사용하는 접근법일 것이다.
강화 학습에 대한 참고 사항:
강화 학습은 “환경”과 상호 작용하고 체계적인 시행착오를 통해 환경을 “해결”하는 방법을 스스로 학습하는 “에이전트” 설계를 다룬다. 환경은 체스나 경주 같은 게임일 수도 있고, 심지어 미로를 풀거나 목표를 달성하는 것과 같은 작업이 될 수도 있다. 에이전트는 작업을 수행하는 봇이다.
에이전트는 환경과 상호 작용하여 “보상”을 받는다. 에이전트는 환경에서 받는 보상을 최대화하는 데 필요한 “작업”을 수행하는 방법을 배운다. 에이전트가 미리 정의된 보상 임계값을 누적하는 경우 환경은 해결된 것으로 간주된다. 이 과정은 우리가 로봇들에게 초인적인 체스나 두 발로 걷는 법을 가르치는 방법이다.
우리는 포트폴리오의 가치를 극대화하기 위해 거래 환경과 상호 작용하는 전략을 사용하는 에이전트를 설계할 것이다. 여기서, 어떤 포트폴리오(예: 30%의 주식 A, 30%의 주식 B, 30%의 주식 C, 10%의 현금 분할)를 유지할지를 에이전트가 결정한다. 그런 다음 에이전트는 해당 작업(포트폴리오 할당)에 대해 긍정 또는 부정 보상을 받는다. 에이전트는 지정된 환경 상태에 대한 최상의 작업을 결정할 때까지 전략을 반복적으로 수정한다.
실험 설정:
실제 거래 프로세스를 시뮬레이션하기 위한 맞춤형 환경을 설계했다. 에이전트는 다음과 같은 방식으로 환경과 상호 작용할 수 있다.
- 환경은 현재 상태에 대한 관찰을 제공한다 – 3가지 주식에 대한 지표
- 에이전트는 이를 기반으로 행동을 취한다. 여기서 행동(action)은 제안된 포트폴리오 할당이다(예: 총 현금 가치의 10%, 주식 1의 30%, 주식 2의 30%, 주식 3의 30%).
- 환경은 한 단계씩 상태를 변경하고 새로운 상태 및 이전 포트폴리오와 관련된 보상(가치 변화)을 반환한다.
위의 1~3단계는 에피소드가 완료될 때까지 반복된다. 각 단계가 끝날 때 획득한 보상의 합계는 총 보상이다. 목표는 에피소드 마지막에 총 보상을 최대화하는 것이다.
에피소드의 크기는 500개의 시간 스텝으로 설정된다. 이는 65만 개 이상의 시간 스텝으로 구성된 데이터 세트에서 무작위로 잘라낸 것이다. 환경이 초기화될 때마다 전체 데이터 세트의 다른 섹션이 선택된다. 이렇게 하면 에이전트가 환경을 기억할 수 없게 된다. 환경의 모든 운영은 다를 것이다. 또한 에이전트에 대한 훈련 및 평가는 다양한 환경에서 수행된다. 따라서 에이전트는 데이터의 한 슬라이스에서 정책을 학습한다. 그런 다음 정책은 데이터 세트의 다른 슬라이스에서 평가된다.
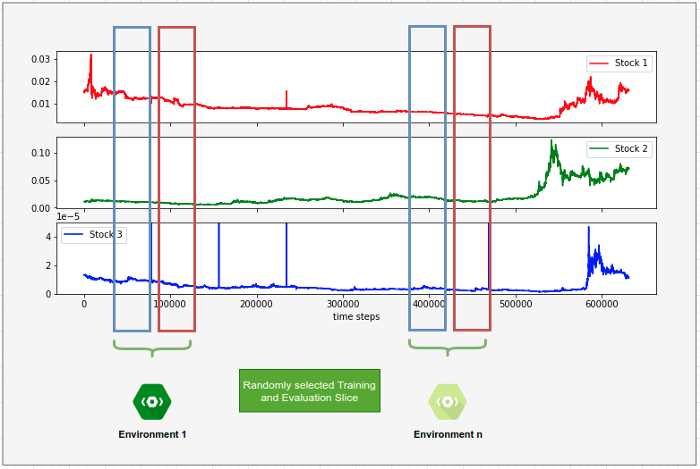
이제 이 설정을 사용하여 RL 알고리즘과 Markowitz의 모델을 평가한다.
결과:
강화 학습
여기서는 off-the-shelf untuned lazy implementation of Actor Critic model을 사용할 것이다. 우리는 이것을 위해 텐서플로우의 tf-에이전트 프레임워크를 사용할 것이다. 전체 코드와 학습에 대한 자세한 내용은 필자의 Github를 확인해보자.

모델평가:
100번 이상의 환경 실행을 평가한다.
평균수익률 : +20%
마코위츠의 효율적 프론티어
이 접근방식은 포트폴리오의 위험과 수익을 평가하기 위한 프레임워크를 제안한다.
포트폴리오의 반환은 해당 포트폴리오에서 기대할 수 있는 평균 시간당 수익이다.
위험은 일일 수익의 표준 편차이다. 이것은 주식 변동성의 척도를 제공한다.
위험과 수익 측면에서 각 포트폴리오를 구성함으로써 자산 관리자는 투자에 대한 정보에 입각한 결정을 내릴 수 있다.

효율적 프런티어는 특정 위험 프로필에 대한 수익이 가장 높은 포트폴리오를 보여준다.
평가를 위해, 이전 30회 단계의 성과를 바탕으로 매 단계마다 계산된 효율적 프런티어 그래프에서 중간 정도의 리스크 높은 보상 포트폴리오를 선택할 수 있는 에이전트를 설계하였다.
평균 수익률: -1%
우리가 고른 주식에는 효율적 프론티어가 효과적이지 않은 것 같다는 것을 여기서 알 수 있다. 아마 우리가 고른 주식의 높은 변동성 때문일 것이다.
비교
아래는 동일한 환경에서 두 정책을 나란히 비교한 것이다.

- RL은 포트폴리오를 160%로, Markowitz는 96%로 축소
- 두 알고리즘 모두 Stock 3에 상당한 양을 할당하고 있다. Stock 3의 가치가 매우 낮고 안정적이기 때문이다. 따라서 약간의 가치 상승은 변동성을 감수하지 않고 큰 수익률(%)로 이어질 수 있다.
- 변동성이 증가하거나 모든 주식이 하락할 때 RL은 공매도 옵션을 활성화하지 않은 경우 매우 현명한 전략으로 주식을 매도하고 현금을 증가시켜 손실을 메우기로 결정한다.
- 일반적으로 RL 전략은 가격 급등의 폭발을 식별하고 즉시 그것을 활용하는 것으로 보인다.
우리는 RL이 위 실험에서 지속적으로 Markowitz의 접근방식을 능가하는 것을 볼 수 있다.
말할 필요도 없이, 이러한 결과는 하나의 예시로 간주되어야 한다. 이러한 실험은 비현실적인 가정과 신중하게 선택된 작은 표본 공간에서 수행되었다. 표본 공간은 실제 세계의 거래와 비슷하지 않다. 거래, 거래원가, 공매도, 위험회피손실 등과 관련된 시간적 지연과 같은 몇 가지 고려사항이 무시되었음을 잊지말자.
번역 – 핀인사이트 인턴연구원 강지윤(shety0427@gmail.com)
원문 보러가기>
https://medium.com/analytics-vidhya/portfolio-optimization-using-reinforcement-learning-1b5eba5db072

555