
News & Events
알고리즘 in 디즈니랜드: 지도학습 프로그램


디즈니랜드에서 다음 놀이기구를 고르는 방법을 기계에게 가르쳐보자.
도입:
디즈니 랜드에서는 30가지의 다양한 놀이기구를 탈 수 있어 여러분의 하루는 끝도 없는 가능성을 가질 수 있다. 사실 끝이 없는 건 아니지만 꽤 가깝다. 당일 12개의 놀이기구(30개 중 12개)만 탈 경우 86,493개의 가능성이 정확히 파악된다. 이로 인해 디즈니랜드 방문객 또는 데이터 사이언스에 관심이 있는 개인에게 다음과 같은 흥미로운 질문을 남긴다. 디즈니랜드에서 가장 이상적인 날은 언제일까?
작동방식:
이 질문에 답하기 위해, 필자는 이전 포스팅(인구 시뮬레이션:디즈니랜드의 대기 시간 예측)에서 필자의 MATLAB 시뮬레이션에 신경망을 적용했다. 저 포스팅은 시뮬레이션이 어떻게 작동하는지에 대해 심도 있게 다루지만, 기본적으로 디즈니 랜드의 놀이기구를 선택하는 그룹을 따라다니며 하루의 점수를 기록한다. 점수가 더 높으면 더 좋은 하루를 보냈다는 뜻이다.
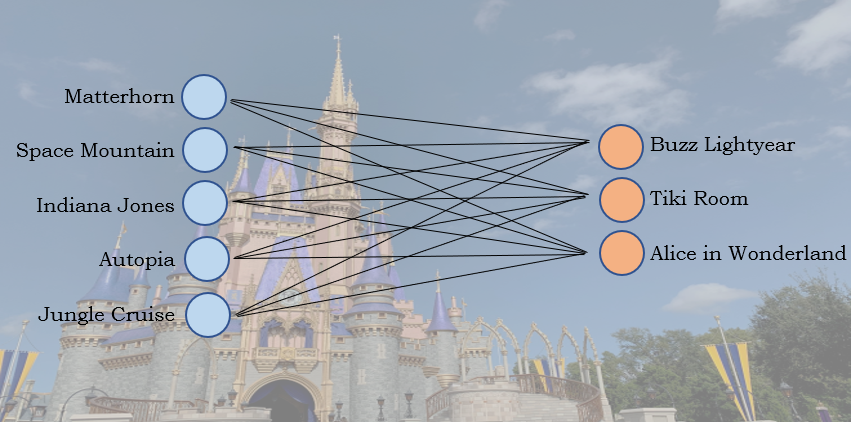
이 데이터에 신경망을 적용하기 위해 출력과 입력 계층이 있는 하나의 계층만 사용하도록 설계했다. 입력 계층은 60개의 노드로 구성되며, 30개는 그룹의 승차 기록을 위한 것이고, 30개는 그룹의 승차감을 위한 것이다. 30개 노드로 구성된 출력 계층이 다음 주행 가능한 모든 노드가 될 것이다. 당신이 이미 탔던 것과 방금 탔던 것을 감안할 때, 기계가 당신의 다음 놀이기구를 골라준다는 아이디어이다.
훈련 데이터를 선택하기 위해 디즈니 랜드에서 시뮬레이션한 날의 상위 10% 점수를 보자. 이 그룹들은 분명히 더 나은 결과를 초래한 결정을 내렸다. 그래서 우리는 신경망을 훈련시켜 같은 결정을 내리길 원한다.
상위 10%에 드는 이 그룹들 각각의 승차 순서에서 5개의 샘플을 채취할 것이다. 각 샘플에서 필자는 올바른 출력으로 선택된 놀이기구와 그 이전에 탔던 놀이기구를 모든 승차 기록과 함께 입력으로 가져갈 것이다. 이렇게 하면 신경망에 대해 약 2,750개의 서로 다른 훈련 데이터 세트(약 5,500개 그룹의 10%, 각각 5개의 샘플)가 생성된다. 다음은 시뮬레이션 데이터 매트릭스에서 개별 훈련 데이터를 수집하는 방법에 대한 예이다.
training_data = zeros(num_groups * 5 * 0.1, 60); % initializes the training matrix
correct_output = zeros(num_groups * 5 * 0.1, 30); % initializes the output matrix
index2 = 0; % initializes an index
index3 = 0; % initializes an index
ridebefore = 0; % establishes a variable
output_ride = 0; % establishes a variable
rides_before = []; % establishes an array
top10 = prctile(group_data(:,43),90);
for a2 = 1:num_groups % for all groups in park
if group_data(a2,43) >= top10 % if score is in top 10%
for a1 = 1:5 % collects 5 samples
index3 = 0; % resets an index
rides_before = []; % clears the ride history array
index2 = index2 + 1; % up one increment for data matrix
for a3 = 1:40 % for up to 40 rides in one day
if ride_history(a2,a3) ~= 0 % counts how many rides the group has been on
index3 = index3 + 1;
end
end
random_num3 = randi(index3); % picks a random number from that count
output_ride = ride_history(a2,random_num3); % finds corresponding ride for that random number
if random_num3 ~= 1 % if it’s not the first ride of the day
ridebefore = ride_history(a2, random_num3 – 1); % sets this variable to the ride before the next choice
for a4 = 1:(random_num3 – 1)
rides_before(length(rides_before) + 1) = ride_history(a2,a4); % sets ride history to all rides before next choice
end
else
ridebefore = 0; % resets value
rides_before = []; % resets array
end
for a5 = 1:30 % turns previous ride number into binary string from 1-30
if a5 == ridebefore
training_data(index2,a5) = 1; % all 0’s except for previous ride
end
end
for a6 = 1:length(rides_before) % turns ride history numbers into binary string from 1-30
for a7 = 1:30
if rides_before(a6) == a7
training_data(index2,a7 + 30) = 1; % all 0’s except for rides previously ridden
end
end
end
for a8 = 1:30 % turns chosen ride into binary string from 1-30
if a8 == output_ride
correct_output(index2,a8) = 1; % all 0’s except for group’s chosen ride
end
end
end
end
end
이제 입력 노드 값 60개와 그에 해당하는 출력 값 30개를 확보했다. 이제 학습률이 0.05로 설정된 지도학습 알고리즘을 사용할 수 있다. 시그모이드 활성화 기능을 사용하여 모든 출력 값을 0과 1 사이로 유지할 것이다. 아래는 이 지도 학습 알고리즘에 대한 코드이다.
dweights = rand(60,30); % assigns random weights to a 60×30 matrix
alpha = 0.05; % learning rate set to 0.05
epochs = 5000; % repeats for training data
for ii = 1:epochs % loop for each epoch
approx_output = 1./(1 + exp(-1 * training_data * dweights)); % finds approximate output
error = correct_output – approx_output; % finds error
delta = (approx_output .*(1-approx_output)).* error; % applies activation function (sigmoid)
ad = alpha .* delta; % extra step for alpha times delta
trans_training = transpose(training_data); % transposes training data matrix
dweights = dweights + (trans_training * ad); % updates weights
end
save(‘Weights.mat’,’dweights’); % saves new weights after all epochs
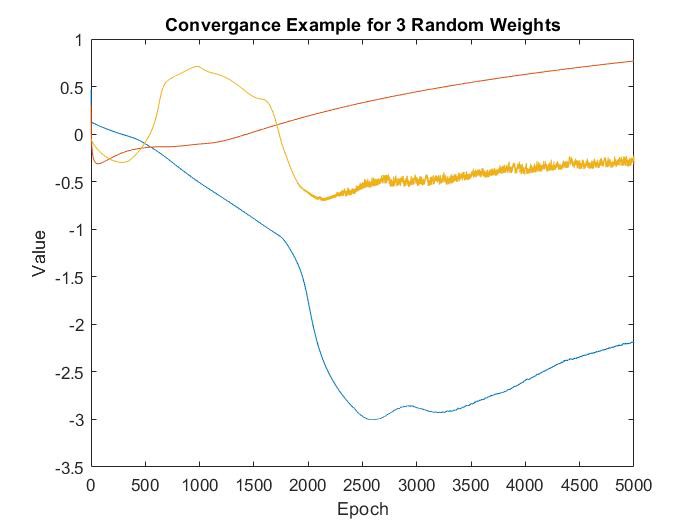
이 코드는 가중 행렬 전체에 걸쳐 좋은 결정을 강화한다. 가중치는 기계가 결정을 내리는 데 도움이 되는 특정 값으로 수렴되기 시작할 것이다. 다음은 시간이 지남에 따라 특정 값으로 수렴되는 세 가지 가중치의 예이다.
알고리즘에 방금 탔던 놀이기구를 알려주면, 이전의 모든 놀이기구들과 함께 상위 3개 놀이기구 중에서 선택할 수 있다. 이상적인 디즈니랜드 데이가 어떤 모습일지 보자.
이상적인 디즈니랜드 데이:
이전 포스팅인 “디즈니랜드 예측: 더 나은 디즈니 데이를 위한 전략“을 통해 알 수 있다. 다음은 고려해야 할 몇 가지 팁이다.
- 일찍 도착 – 공원 개장 전에 도착한 그룹은 평균적으로 하루에 더 많은 놀이기구를 탄다.
- 첫 번째 놀이기구로 스페이스 마운틴, 마터호른, 그리고 인디아나 존스를 골랐을 때 하루에 더 많은 놀이기구를 타는 결과를 낳았다.
- 더 가까운 놀이기구를 선택하는 것 – 다른 놀이기구를 타러 가면서 덜 걸은 그룹은 더 높은 점수를 받을 수 있는 기회가 있었다.
오늘의 첫 놀이기구로 스페이스 마운틴을 선택했다고 가정해 보자. 입구에서 가장 가까운 대형 놀이기구 중 하나이기 때문에, 일찍 도착하면 언제나 바로 선택하는 것이 좋다. 스페이스 마운틴에서 내린 후 방금 탔던 놀이기구 [24]와 탑승 기록을 위한 [24]가 프로그램에 들어간다(시뮬레이션에서 스페이스 마운틴은 24번 승차). 알고리즘은 다음을 선택한다. 마테호른. 말이 된다. 다음으로 가까운 대형 놀이기구이며, 대기 시간은 아직 길지 않을 가능성이 높다. 마터호른 다음에 방금 탄 놀이기구는 [16], 승차 기록은 [24, 16]을 입력한다. 마터호른 다음으로는 캐리비안의 해적입니다. 이 사이클은 하루 종일 계속될 수 있으며, 알고리즘은 당신에게 선택할 수 있는 최고의 3개의 놀이기구를 끊임없이 제공한다.
디즈니 랜드 놀이기구 선택 알고리즘에 따르면 하루 예상 총 탑승 측면에서 처음으로 탑승 하기 가장 좋은 5가지 놀이기구는 아래의 11가지 놀이기구이다.
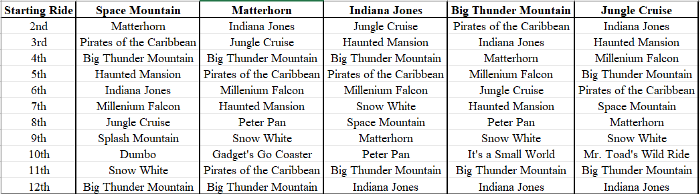
상위 그룹 사이에서 알고리즘이 발견한 일반적인 패턴이 있다. 상위 5개 놀이기구 중 2개를 바로 탑승한다면 디즈니랜드에서 좋은 하루를 보낼 수 있다. 또한 방금 탔던 것과 더 가까운 놀이기구를 선택하는 것이 시간을 절약해 점수를 높일 수 있다는 것을 알고리즘이 알아냈다. 마터호른이 어떻게 항상 스페이스 마운틴을 따라다니는지, 캐리비안의 해적과 빅 썬더 마운틴이 어떻게 항상 옆에 있는지 보자.
현실적으로 이상적인 디즈니 랜드의 날을 계획하고 구현하는 것은 거의 불가능하다. 놀이기구 고장, 화장실, 휴식, 레스토랑에서의 긴 기다림은 디즈니랜드 알고리즘을 따라가는 것을 어렵게 만들 수 있다. 하지만 상위 10% 그룹들이 스스로 결정을 내리는 것을 고려해야 하는 결정들이 있다.
상위 10%의 놀이기구 선택 결정:
아래는 득점일수가 가장 높은 그룹이 선택한 놀이기구를 보여준다.
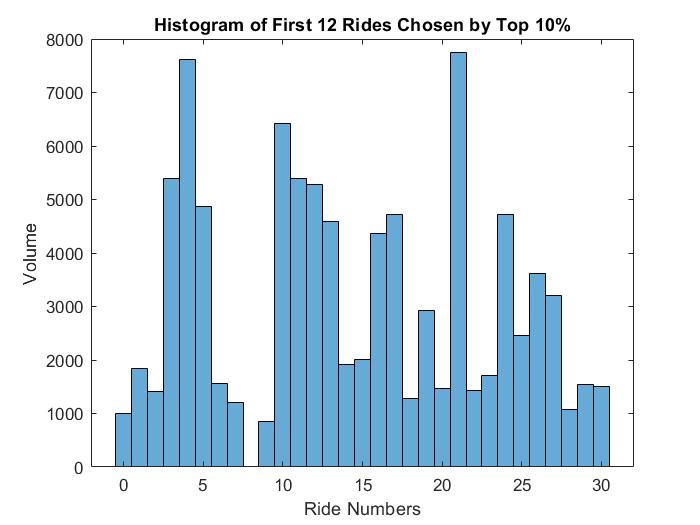
상위 그룹들은 빅 썬더마운틴(4), 캐리비안의 해적(21), 유령의 저택(10)을 많이 탔다. 이 모든 놀이기구들은 서로 가깝고, 스릴 있으면서도 하루 종일 적당한 대기 시간을 갖는 경향이 있다.
상위 10% 그룹은 먼저 인디애나 존스, 스페이스 마운틴, 마터호른에 탑승한 다음 위에서 언급한 적당한 대기 시간의 놀이기구를 타고 점수를 올리는 경향이 있다. 보통 하루에 여러 번 하는 놀이기구들이다.
중요한 놀이기구부터 시작해서 중요한 놀이기구까지. 한낮에 적당한 대기 시간의 놀이기구를 여러 번 타보자. 하루 중 가장 더운 시간대에는 실내형 놀이기구를 타보자. 이 모든 것들은 시뮬레이션에서 상위 그룹들에 의해 이루어졌다.
결론:
디즈니랜드 알고리즘은 디즈니랜드 데이터 분석에 대한 필자의 3부작 시리즈를 끝낼 수 있는 좋은 방법이다. 시뮬레이션에 신경망을 적용하는 것은 도전적이면서도 보람 있는 일이었음이 증명되었다. 시뮬레이션에서 획득한 수천 개의 원시 데이터 포인트 내에 다음 디즈니 여행 시 구현할 수 있는 몇 가지 중요한 패턴이 있다는 것을 보여주었다.
번역 – 핀인사이트 인턴연구원 강지윤(shety0427@gmail.com)
