
News & Events
Deep Q Network(DQN)

Q-러닝에서 기능적 근사치로 신경망을 적용하는 방법

* 이 글은 medium에 작성된 datasculptor의 글을 번역하였습니다.

Q-러닝의 기초를 이해하려면 이 링크를 참고하자.
Q-테이블을 이용한 Q-러닝의 주요 문제는 상태-액션 쌍[1]이 많을 경우 확장성이 떨어진다. 신경망은 근사 함수이므로 Q 테이블을 대체하는 데 사용할 수 있다. 학습 과정에서 딥러닝(DL)은 가중치를 최적화하여 손실 함수에 의해 추정된 오류를 최소화한다. 이때 오류 또는 손실은 예측 결과와 실제 결과의 차이로 측정된다.
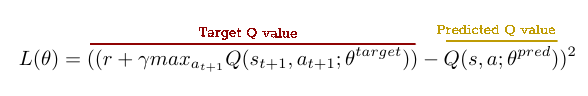
DQN에서, 우리는 우리의 손실 함수를 목표 Q 값과 예측 Q 값의 제곱 오차로 나타낼 수 있다.
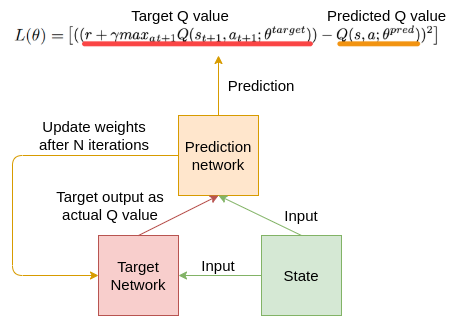
DQN에서는 동일한 아키텍처를 가진 두 개의 개별 신경망을 사용하여 Q-러닝 알고리즘의 안정성을 위한 목표 및 예측 Q 값을 추정한다. 대상 모델의 결과는 예측 신경망의 기본 정보로 처리된다. 예측 신경망의 가중치는 모든 반복에서 업데이트되고 대상 신경망의 가중치는 N번 반복 후 예측 신경망 가중치로 업데이트된다.
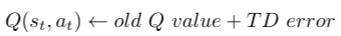
손실 함수는 위와 같이 Q 값의 업데이트 룰에서 파생된다. 기본적으로 손실 함수는 원래 Q-러닝 알고리즘의 TD 오류 계산을 대체한다.

위와 같이 TD 오류를 확장하면 새로운 Q 값이 대상 신경망(Target Q 값)에서 계산한 Q 값과 동일하고 이전 Q 값은 예측 신경망의 Q 값(Predicted Q 값)과 동일하다는 것을 알 수 있다.
DQN[2]의 유사 코드:
- 에피소드가 시작된다.
- 상태 st에서 액션 a_t를 수행하고 다음 상태 s_t+1과 보상 r을 관찰한다. 처음에는 동작이 무작위로 선택된다. 시간이 지남에 따라 예측 신경망의 조치가 입실론 그리디 정책에 따라 사용된다. 입실론 그리디 정책에서는 Q 값이 가장 높은 조치가 고려될 것이다. 일반적인 신경망에서는 확률이 가장 높은 예측이 선택된다.
- 액션에 대한 보상을 계산한다.
- 현재 상태, 액션, 보상 및 다음 상태를 재생 버퍼에 저장한다. NN에서 배치 훈련을 가능하게 한다.
- s_t+1은 새로운 상태 s_t이며 배치 크기가 도달할 때까지 2~4단계를 반복한다.
- 배치 크기에 도달하는 NN에서 배치 교육을 실행한다. 구현 시 손실 함수가 다르게 표현된다는 점에 유의하자. 코드를 이해하려면 [3]을 참조하자.
- N번 반복에 도달하면 예측 신경망의 가중치가 대상 신경망에 복사된다.
- 에피소드가 끝난다.
- 최적의 Q 값에 도달할 때까지 1~6단계를 반복한다.
필자의 글이 마음에 드신다면, Github, Linkedin 또는 Medium 프로필을 방문해주세요.
참조
- Karunakaran, D., Worrall, S. and Nebot, E., 2020. Efficient statistical validation with edge cases to evaluate Highly Automated Vehicles. arXiv preprint arXiv:2003.01886.
- https://www.analyticsvidhya.com/blog/2019/04/introduction-deep-q-learning-python/
- https://towardsdatascience.com/reinforcement-learning-w-keras-openai-dqns-1eed3a5338c
번역 – 핀인사이트 인턴연구원 강지윤(shety0427@gmail.com)
원문 보러가기>
