
News & Events
시계열 예측을 위한 딥러닝


RNN & DeepAR 모델을 사용해보자
시계열 예측은 모든 업종과 다양한 맥락에서 찾아볼 수 있기 때문에 가장 일반적인 시계열 활용 사례이다. 재고 최적화를 위한 매출 예측이든, 생산 수준 적응을 위한 에너지 소비 예측이든, 고품질의 서비스를 보장하기 위한 항공사 승객 수 추정이든 시간이 핵심 변수이다.
그럼에도 불구하고 시계열을 다루는 것은 어려울 수 있다. 일정한 시간 간격으로 기록된 관측치의 시퀀스로 구성된 데이터는 상황에 따라 노이즈를 포함하거나, 덩어리가 크거나, 간헐적일 수 있다.
기존의 접근 방식은 지나치게 단순할 수 있으며, 만족스러운 성능 결과를 보장하기 위해 시간이 많이 걸리는 사전 및 사후 처리 단계가 필요한 경향이 있다.
- 실제로 고전적인 시계열 모델은 대개 과거의 관측으로부터 학습하므로 최근의 히스토리만을 사용하여 미래의 가치를 예측한다. 이러한 모형에는 자기 회귀(AR), 이동 평균(MA), 자기 회귀 누적 이동 평균(ARIMA) 및 단순 지수 평활(SES)이 포함된다.
- 또한 매개 변수는 교차 학습의 잠재적인 긍정적 효과를 이용하지 않고 각 시계열에 대해 독립적으로 추정된다.
- 마지막으로, 자기 상관 구조, 추세, 계절성 및 기타 설명 변수와 같은 일부 결정 요인을 설명하기 위해 접근 방식은 각 시계열 또는 시계열 그룹에 대해 최상의 모델을 선택하는 것으로 구성되며 휴리스틱, 수동 개입 및 미세 조정 단계를 정의해야 한다.
이러한 한계는 접근방식을 광범위하게 채택하는 데 주요 장애물이 된다.
한편, 지난 수십 년 동안 딥러닝 모델은 큰 성공을 거두었다. NLP(Natural Language Processing), 이미지 분류 또는 오디오 모델링과 관련된 사용 사례에 대한 응용 프로그램은 기존 접근 방식을 지속적으로 능가하고 비즈니스 습관을 변화시켰다. 시계열 예측에는 딥러닝 방식을 성공적으로 적용한 연구 논문이 많다. 통계적 접근법과 마주하는 문제를 극복할 수 있을 뿐만 아니라 시계열 예측의 복잡성을 더 잘 처리하여 상당히 개선된 결과를 얻을 수 있는 모델을 제안했다.
한편, 지난 수십 년 동안 딥러닝 모델은 큰 성공을 거두었다. NLP(Natural Language Processing), 이미지 분류 또는 오디오 모델링과 관련된 사용 사례에 대한 응용 프로그램은 기존 접근 방식을 지속적으로 능가하고 비즈니스 습관을 변화시켰다. 시계열 예측에는 딥러닝 방식을 성공적으로 적용한 연구 논문이 많다. 통계적 접근법과 마주하는 문제를 극복할 수 있을 뿐만 아니라 시계열 예측의 복잡성을 더 잘 처리하여 상당히 개선된 결과를 얻을 수 있는 모델을 제안했다.
이 포스팅은 시계열 예측에 성공적인 것으로 입증된 최첨단 딥러닝 모델에 대한 포괄적인 개요를 제공하는 것을 목표로 하는 2부 시리즈 중 첫 번째이다.
첫 번째 포스팅에서는 RNN 기반 모델과 DeepAR에 초점을 맞추고, 두 번째 포스팅에서는 시계열을 위한 트랜스포머 기반 모델을 살펴볼 것이다. 각 포스팅은 이러한 모델을 표준 예측 접근법과 비교한다.
이 시리즈를 읽고 나면 다음과 같은 내용을 이해할 수 있다.
- 시계열 예측에 사용되는 딥러닝 모델의 주요 공통 개념
- 해당 모델들의 차이점
- 예측 정확도와 계산 시간 측면에서 제공하는 향상된 결과
예시 사례로 30일 동안 업종별 여러 회사의 일일 주가 예측 사례를 참고할 것이다. 이러한 접근방식으로 성과를 평가하고 다른 기준에 기초한 구체적인 사용 사례와 비교할 수 있는 기회를 제공할 것이다.
1. 딥러닝 모델: RNN의 어깨 위에 서다
1.1. 순환 신경망에 대한 리프레시
순환 신경망(RNN)은 시계열 모델의 딥러닝 프레임 워크의 구성 요소로 자주 사용되거나 포함된다. 주로 시계열의 순차적 특성을 명시적으로 고려하여 더 효율적으로 학습할 수 있는 능력 때문이다. 왜일까?
RNN은 어느 정도까지 시계열에 적용될 수 있는가?
- 첫째, 정의상 RNN은 그림 1에서와 같이 뉴런이 히든 스테이트를 통해 서로 피드백 신호를 보내는 신경망의 종류를 의미한다.
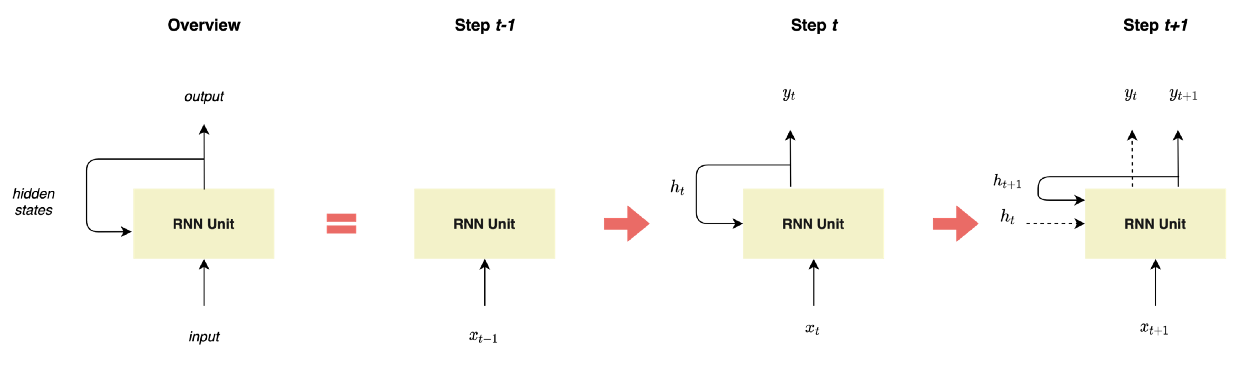
그림 1 — RNN 표현 by Lina Faik
- 입력과 출력을 서로 독립적이라고 간주하는 순방향 신경망과 달리 RNN은 현재 입력과 출력을 예측하면서 이전 입력을 “메모리”에 유지할 수 있게 한다.
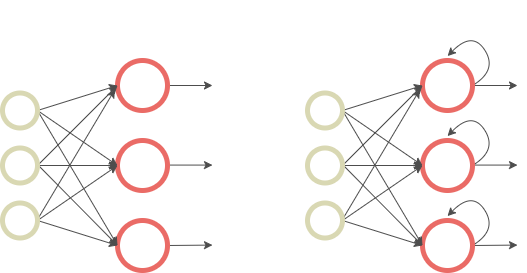
그림 2 — 순방향 신경망(왼쪽)과 RNN(오른쪽)의 비교, by Lina Faik
- 둘째, RNN은 학습해야 할 매개 변수의 수 측면에서 기존 신경망과 다르다. 순방향 신경망은 각 노드에 걸쳐 서로 다른 가중치를 갖는 반면, RNN은 네트워크의 각 계층 내에서 동일한 매개 변수를 공유한다. 이 방법은 시퀀스 데이터에 더 적합하며 적합해야 하는 매개변수의 수가 더 적다.
실제로 RNN은 시퀀스를 어떻게 처리할까?
그림 2에서 볼 수 있듯이, 각 단계 t에서 RNN 유닛은 이전의 히든 스테이트를 수신한다.
예를 들어, 간단한 RNN으로 전 주 y(-6:0)를 사용하여 다음 주 y(1:7)일 동안의 특정 회사의 일일 주가를 예측하려고 한다.
먼저 RNN은 입력 시퀀스에서 X(0) = y(t=-6)를 취한 다음 X(1) = y(-5)로 다음 단계를 위한 입력이 되는 h(0)를 출력한다. 그리고 이 단계의 h(1)와 X(2) = y(-5)는 다음 단계의 입력을 위한 것이다.
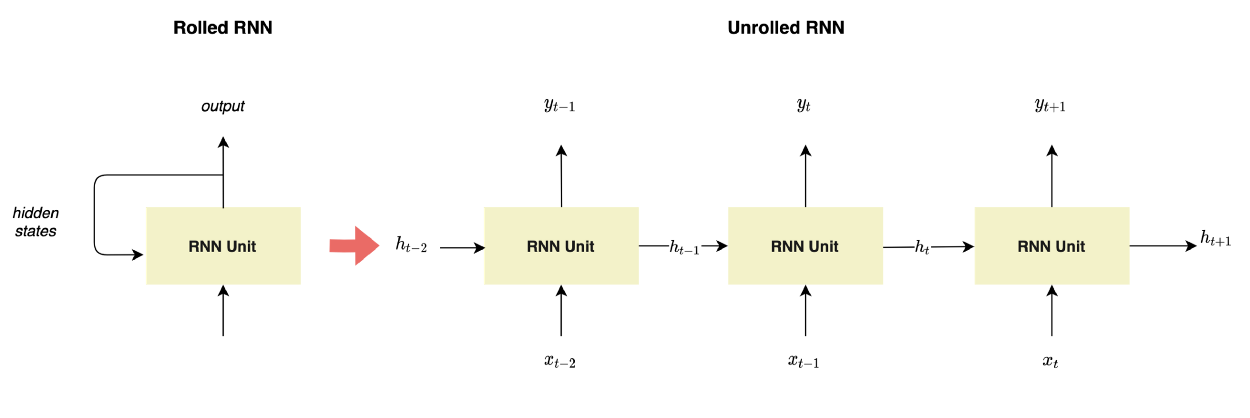
그림 3 — RNN의 전개 by Lina Faik
RNN 블록 아래에 숨어 있는 것은 무엇일까?
이 포스팅의 목적에 필수적이지는 않지만, RNN 셀의 기본 아키텍처를 먼저 검토한 다음 일부 변형 사례를 살펴보는 것이 RNN이 어떻게 구성되는지 이해하는 데 유용할 수 있다.
그림 4에서 설명하는 것과 같이 표준 RNN은 간단한 방정식에 의존한다.
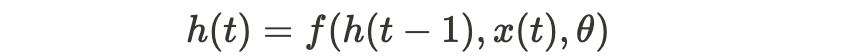
여기서 h(t)는 단계 t에서 셀의 히든 스테이트이고 θ는 전달 함수 f의 매개 변수이다.
그러나 재귀적인 특성 때문에, 이렇게 정의된 RNN은 그래디언트 기반 최적화 접근 방식을 사용하여 훈련할 때 기술적 문제를 겪는다. 훈련 중에 역전파되는 그래디언트는 0으로 향하는 경향이 있고 따라서 사라지거나 무한대로 가는 경향이 있어서 폭발할 수 있다.
이러한 맥락에서 RNN의 변형이 이러한 문제를 극복하기 위해 도입되었고 결국 다른 특성을 추가했다. 이러한 모델에는 LSTM(Long Short-Term Memory)과 GRU(Gated Recursive Unit)가 해당된다.
자세한 내용은 이 포스팅이나 이 포스팅을 참고하길 바란다.
1.2. DeepAR
대량의 데이터가 사용 가능해짐에 따라 수천 또는 수백만 개의 관련 시계열을 예측해야 한다. 예를 들어, 소매업자들은 각 제품에 대한 수요를 예측하려고 한다. 증권가에서는 브로커가 재무 포트폴리오 관리를 위해 여러 기업의 향후 주가를 예측해야 한다.
또한 예측은 과거 값뿐만 아니라 동적인 역사적 특징, 각 시리즈에 대한 정적 속성 및 알려진 미래 사건과 같은 다른 공변량에 따라 달라진다. 그러나 고전적인 접근방식은 각 시계열을 독립적으로 학습하고 예측하기 때문에 교차 학습 가능성 또는 사용 사례를 고려할 때 가치가 있을 수 있는 정보를 완전히 활용하지 못한다.
이러한 맥락에서 DeepAR은 가장 효율적인 최첨단 예측 모델 중 하나임이 입증되었다.
DeepAR은 다른 모델들과 어떻게 다를까?
아마존이 출시해 ML 플랫폼 SageMaker에 통합된 DeepAR은 여러 공변량을 활용해 ‘스케일’로 학습할 수 있는 능력이 돋보인다.
데이터 세트에 있는 모든 시계열의 과거 데이터에서 글로벌 모델을 학습하고 정확한 확률적 예측을 생성하는 AR RNN을 기반으로 한 예측 방법론으로 구성된다.
모델의 작동 방식을 살펴보기 전에 모델의 주요 이점은 다음과 같다.
- 확률론적 예측. DeepAR은 시계열의 미래 값이 아니라 미래 확률 분포를 추정한다. 이를 통해 실무자는 수치 추정치를 계산할 수 있으므로 비즈니스 프로세스의 최적화가 향상된다. 예를 들어, 소매업자는 재고를 더 잘 추정할 수 있고 중개업자는 포트폴리오의 위험 노출도를 더 잘 평가할 수 있다.
- 공변량. DeepAR은 공변량을 사용하여 복잡하고 그룹 의존적인 관계를 포착할 수 있다. 이는 일반적으로 고전적인 예측 모델에서 사용되는 공변량 및 단면 휴리스틱을 선택하고 준비하는 데 필요한 노력과 시간을 줄여준다.
- 콜드 스타트 문제. 한 번에 하나의 시계열만 예측하는 기존 방법은 사용 가능한 이력이 거의 없거나 없는 항목에 대한 예측을 제공하지 못하지만 DeepAR은 이를 달성하기 위해 유사한 항목의 학습을 사용할 수 있다.
DeepAR은 실제로 어떻게 작동할까?
DeepAR은 다음과 같은 한 가지 기본 아이디어에 의존한다. 각 시계열에 대해 별도의 모델을 맞추는 대신 데이터 세트의 모든 시계열을 사용하여 학습하는 글로벌 모델을 만드는 것을 목표로 한다.
DeepAR의 아키텍처
전체적으로, 모델은 각각 주어진 항목 i, y_i의 시계열과 관련된 신경망 모델의 스택으로 구성된다.
그림 4에서 볼 수 있듯이, 이 모델들은 Θ_i에 의해 매개 변수화된 RNN과 가능성 모델 p(y_i|θ_i)로 구성되어 있다.
가능성 모형은 데이터의 통계적 특성에 따라 선택해야 한다. 원본 논문에서 두 가지 가능성 모델이 고려된다.
![Figure 4- DeepAR framework, adapted from [1], illustration by the author](https://lh6.googleusercontent.com/8jySoDdt6VyxtplrC91f6ZfvD6JPNukeTgGH0yDSoapcthlp3Ray1jB8GA1ihydqEspWrUVOcOUyXmZF7PRrwNSPvHz3o_xIZ_HueS-eq4Bwx_GwAa0gPLxKB-oc1BA0u5Noyzi4)
그림 4 – DeepAR 프레임워크 by Lina Faik
다른 단계는 어떤 것과 관련있을까?
그림 4에 설명된 것처럼 각 타임 스텝 t에서 모형은 다음 타임 스텝 t+1(horizon=1)을 예측한다.
네트워크는 마지막 관찰 y_{i,t-1}, 이전 네트워크 출력 h_{i,t-1} 및 공변량 집합 x_{i,t}을 입력으로 수신한다. 은닉층으로 전파되는 다음 은닉 스테이트 h_{i,t}을(를) 계산한다.
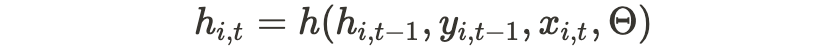
θ는 네트워크의 매개 변수를 나타낸다.
은닉 스테이트는 매개변수가 네트워크 출력 ((h_{i,t}, θ)에 의해 결정되는 우도 p(y_{i,t} |θ(h_{i,t}, θ)) 를 계산하는 데도 사용된다.
예를 들어, 가우스 우도가 선택된 경우, 평균 μ는 네트워크 출력의 아핀 함수를 사용하여 계산되고 표준 편차 σ는 아핀 함수와 softplus 활성화(양수 값을 얻기 위해)를 결합하여 구한다.
이 모델은 교차 학습 효과를 활용하기 위해 모든 시계열에서 동시에 학습하는 것을 목표로 하기 때문에 RNN h(.)와 θ(.)로 구성된 매개 변수 θ는 모든 항목과 전체 시간 범위에 대한 로그 가능성을 최대화하여 학습한다.
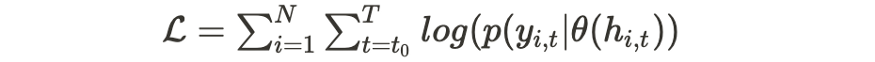
로그 우도의 최대화는 θ에 대한 경사를 계산함으로써 확률적 경사 하강을 통해 달성될 수 있다.
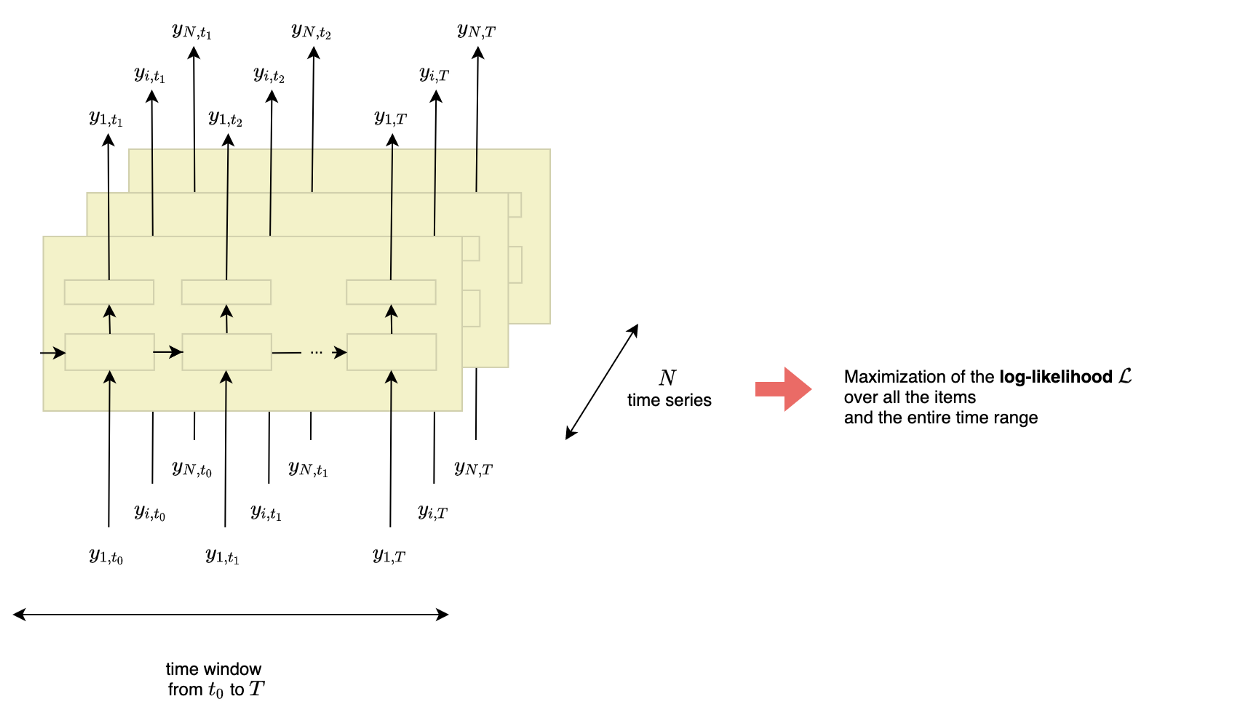
Figure 5— DeepAR framework, illustration by Lina Faik
DeepAR은 어떻게 훈련되고 예측에 활용되는가?
모델이 예측을 하는 방법의 차이는 훈련 단계와 예측 단계 사이에 이루어져야 한다. 훈련 단계에서는 y_{i,t}의 값을 알 수 있지만 예측 단계에서는 t ≤ t0에 대해 알 수 없다. 따라서 h_{i,t}를 계산할 때 사용할 수 없다. 이 문제를 해결하기 위해 모형 분포의 표본이 대신 사용된다.
![Figure 6- Forecasting strategy for DeepAR models, adapted from [1], illustration by the author](https://lh6.googleusercontent.com/6mU51MGO43qr_-lIrRgvimsBsNJdo0_uQWq7GKUxHEPM5U4DSIZWYBcUkJSwV2o9nExmLFhWsj1CJVi70zGqPk32FL_Rq6p2MkKjXPKkNX66VaLY_gc2sEPir9EXfyOCkSqe-Lod)
Figure 6— Forecasting strategy for DeepAR models, adapted from [1], illustration by Lina Faik
이러한 학습 전략은 RNN을 다룰 때 일반적으로 사용되는 티처 포싱과 밀접한 관련이 있다. 이것은 모델의 마지막 예측 결과 대신 훈련의 각 새로운 단계에서 참 값을 사용하는 아이디어를 말한다.
이 전략의 관련성을 설명하기 위해, 시험을 준비하는 학생의 비유를 들어보자. 학생은 여러 번의 연습에 걸쳐 오류를 축적하고 마지막에 수정만 받는 것보다 선생님이 어깨 너머로 보고 즉시 고쳐주면(필요하다면) 더 효율적이고 빠르게 자신의 실수를 배울 것이다.
그러나 이 접근법에 단점이 없는 것은 아니다. 실제로 훈련 중에는 모델이 다음 단계에서 참 값을 받기 때문에 작은 실수가 손실에 크게 기여하지 않는다. 결과적으로 모델은 한 단계만 미리 예측하는 방법을 배운다. 그러나 예측 중에는 모형이 더 이상 수정에 의존할 수 없으므로 더 긴 시퀀스를 예측해야 한다. 그 결과, 훈련 중에 중요하지 않았던 작은 실수가 이제는 예측 단계에서 긴 시퀀스에 걸쳐 증폭된다.
요약하자면, 티처 포싱은 모델이 더 빠르고 효율적으로 학습할 수 있게 할 수 있지만, 훈련과 예측이 다른 과제가 되면서 더 나쁜 결과로 이어질 수도 있다.
이러한 한계를 해결하기 위한 여러 접근법이 제안되었다. 그 중 하나가 커리큘럼 학습이나 예정된 표본 추출이다. 실제 값이 아닌 훈련 중 자체 예측 출력으로 모델을 무작위로 또는 점진적으로 공급한다.
DeepAR은 이종 시계열을 어떻게 처리할까?
여러 시계열에서 학습하려는 모델은 종종 두 가지 문제에 직면한다.
- 스케일. 시계열은 스케일의 큰 차이를 나타낼 수 있다. 이 문제를 해결하기 위해 DeepAR은 항목 종속적 스케일 팩터 ν_i를 계산하고 이를 사용하여 자동 회귀 입력 y_{i,t}의 스케일을 재조정한다. 또한 척도 의존적 우도 매개 변수에 동일한 요인을 곱한다.
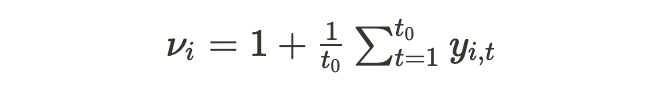
- 불균형 데이터. 데이터 세트에서 일부 항목이 제대로 표현되지 않았을 수 있다. 일반적으로 적은 수의 항목이 높은 척도를 표시한다. 따라서 랜덤 표본을 균일하게 선택하는 최적화 절차를 수행하면 모형이 이러한 항목을 제대로 적합시키지 못한다. 이 문제는 ν_i에 종속된 가중 샘플링 전략을 사용하여 극복된다.
DeepAR이 외부 정보를 활용하는 방법
여러 시계열을 동시에 학습함으로써 모델은 공변량 x_{i,t}의 정보를 사용할 수 있으므로 교차 학습을 효과적으로 활용할 수 있다.
공변량은 다음과 같을 수 있다.
- 항목 종속: 항목 i의 범주화
- 시간 의존성: 시점에 대한 정보
- 둘 다: 시간 t에 항목 i에 대한 가격 또는 프로모션 상태
2. 주식예측에의 적용
2.1. 범위
주식시장이 매우 예측 불가능한 경향이 있다는 것은 놀라운 일이 아니다. 중대한 정치적 반전이든, 소셜 네트워크 플랫폼을 통해 공개된 단순한 트윗이든 어떤 변화가든 주식 동향에 큰 영향을 미칠 수 있다.
이런 맥락에서 재무 분석에만 의존하는 것은 시간이 많이 걸리고 비효율적일 수 있다. 대신 머신 러닝을 사용하면 더 나은 의사 결정 지원을 제공할 수 있다. 많은 양의 데이터를 처리하고, 중요한 패턴을 학습하며, 주목할 만한 기회를 포착할 수 있다.
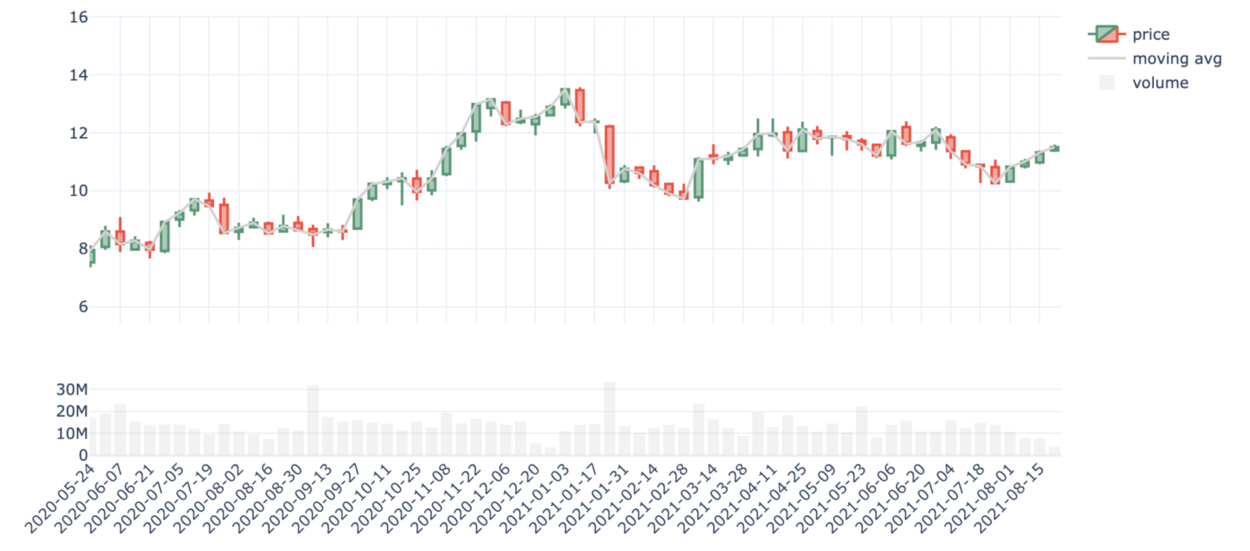
Figure 7— Evolution of the stock price and trade volumes of EDF
이 파트의 목적은 시계열 예측에 대한 딥러닝 모델의 성능을 더 고전적인 모델과 비교하는 것이다.
과제: 향후 30일 동안 대기업의 일일 주가를 예측한다.
데이터 세트 정보
데이터 세트에는 10년 동안 S&P 지수에서 무작위로 선정된 100개 기업의 일일 주가 히스토리가 담겨 있다.
또한 각 회사별로 다음에 대한 정보도 포함되어 있다.
- 산업: ‘의료’, ‘소비자 재량’, ‘유틸리티’, ‘금융’, ‘정보 기술’, ‘없음’, ‘산업’, ‘에너지’, ‘부동산’, ‘재료’, ‘소비재’
- 재무 데이터 ‘시총’, ‘EBITDA’와 같다.
- 주식 실적: ‘P/E’, ‘배당 수익률’, ‘EPS’, ’52주 최저’, ’52주 최고’, ‘P/S’, ‘P/B’
또한 주간, 월간, 연간, 계절을 고려하여 날짜 관련 기능도 포함되어있다. 자세한 내용은 이러한 특징을 계산할 수 있는 방법에 대한 글을 참조하자.
모델 벤치마크
이전 모델의 성능은 다음 방법에 따라 테스트된다.
- 개인 식별 정보. 예측을 하기 위해 최근 히스토리에 의존한다. 최근 30일 동안의 관측치를 향후 30일 동안의 주가 전망치로 활용한다는 의미다. 자세한 내용은 여기를 참조하자.
- 계절 단순 기법. 트리비얼 정체성 접근과 비슷하게, 예측하기 위해 최근의 히스토리를 사용하지만 계절성을 고려한다. 더 정확히 말하면, 계절성 길이 h를 가정했을 때, 각 단계 t에서의 예측은 다음과 같다.
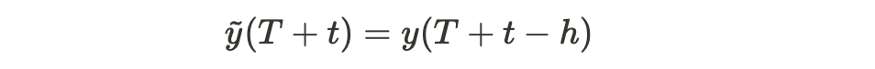
여기서 T는 예측 시간이다. 자세한 내용은 여기를 참조하자.
- 오토 ARIMA. 이 알고리즘은 ARIMA 모델에 가장 적합한 파라미터를 식별한다. 먼저 미분화 테스트를 수행하여 미분화 d의 순서를 정의한다. 그런 다음 Canova-Hansen을 사용하여 계절성 P 및 Q와 관련된 모수를 결정하여 계절성 차이 D의 최적 순서를 구한다. 최상의 모델은 AIC(Akaike Information Criteria), BIC(Basian Information Criteria) 등과 같은 메트릭스를 기반으로 선택된다. 모델에 대한 자세한 내용은 여기 및 패키지 설명서에서 확인할 수 있다.
- NPTS 모델이다. 이 모델의 목적은 과거 관측치에서 표본을 추출하여 미래 가치 분포를 예측하는 것이다. 이 모델은 지수 커널을 사용하여 예측이 필요한 현재 시간 단계로부터 얼마나 떨어져 있는지에 따라 기하급수적으로 붕괴하는 과거 관측치 각각에 가중치를 할당한다. 따라서 최근 관측치가 더 높은 확률로 표본 추출된다. 모델에 대한 자세한 내용은 여기에서 확인할 수 있다.
- 순방향 네트워크. 이전 단계에서 다음 목표 시간 단계를 예측하는 간단한 MLP(Multilayer Perceptron) 모델을 훈련한다. 자세한 내용은 여기를 참조하자.
학습 프레임워크
- 교육 및 검증 세트. 데이터 세트는 지난 30일과 관련된 데이터를 제외한 모든 데이터를 포함하는 교육 데이터 세트와 지난 30일의 가격을 포함하는 검증 데이터 세트로 나뉜다.
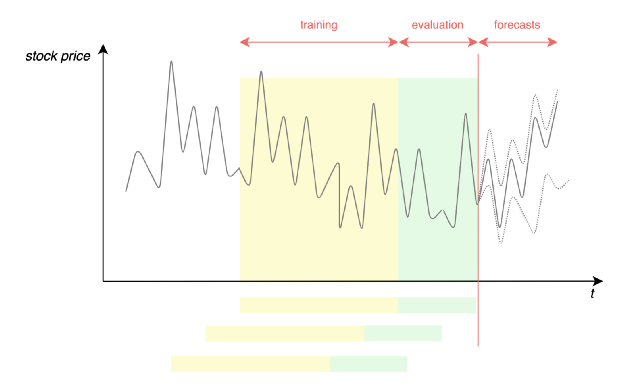
Figure 8— Learning Framework
- 시나리오. 이 실험에는 모델에 사용되는 기능에 기반한 세 가지 시나리오가 포함된다.
시나리오 1. 기준선: 모델에 가격만 주어진다.
시나리오 2. 날짜 특징: 가격 외에도 모델은 주간, 월간 및 연간 계절성 효과를 고려하여 날짜와 관련된 피쳐를 수신한다.
시나리오 3. 날짜 특성 및 공변량: 모형은 가격 및 날짜 특성 외에도 위에서 설명한 공변량을 사용하여 학습된다. - 측정 기준. 여러 접근 방식의 성능을 비교하기 위해 다음 두 가지 측정 기준을 사용한다. 평균 제곱근 편차(RMSE) 및 평균 절대비 오차(MAPE)뿐만 아니라 모델이 학습하는 데 사용되는 계산 시간이다.
2.2. 결과: 정확한 예측 및 높은 확장 가능성
전체적으로 딥러닝 모델은 AutoArima를 제외하고 다른 모델보다 성능이 우수했다. 후자는 비슷한 예측 정확도를 제공하지만 훨씬 더 긴 학습 시간이 필요하기 때문에 실제로는 수정할 수 없다.
표 1은 세 가지 시나리오의 모든 모델에 대한 성능 지표를 모든 시계열의 평균으로 보여준다.
이러한 수치는 주의하여 해석해야 한다. 평균을 나타내는 것으로 실제 기업에 따라 결과 차이가 크다(업종이나 최근 사건에 따라 결과가 크게 달라진다).

Table 1 — Results (expressed as an average over all time series)
이 섹션의 나머지 부분에서는 보다 자세히 살펴본 결과를 확인할 수 있다.
1. 확률론적 모델은 사업적인 관점에서 더 흥미롭다. 예측뿐만 아니라 이와 관련된 불확실성까지 제시하기 때문에 얼마나 확신하고 있는지 짐작하게 한다. 어떤 상황에서는 이것이 매우 중요할 수 있다.
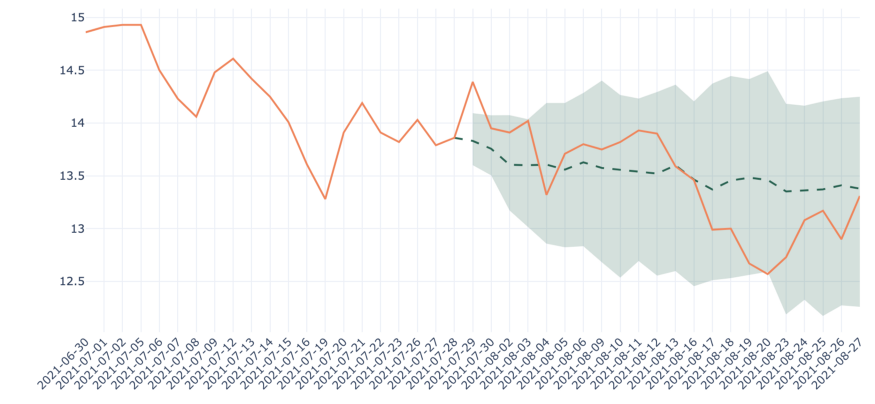
Figure 9— Forecasts for Ford Motor using DeepAR (baseline), RMSE: 0.17
2. 기능을 추가한다고 해서 항상 결과가 개선되는 것은 아니다. 그림 10은 공변량으로 훈련했을 때 모델의 결과가 저하되는 회사의 예를 보여준다.
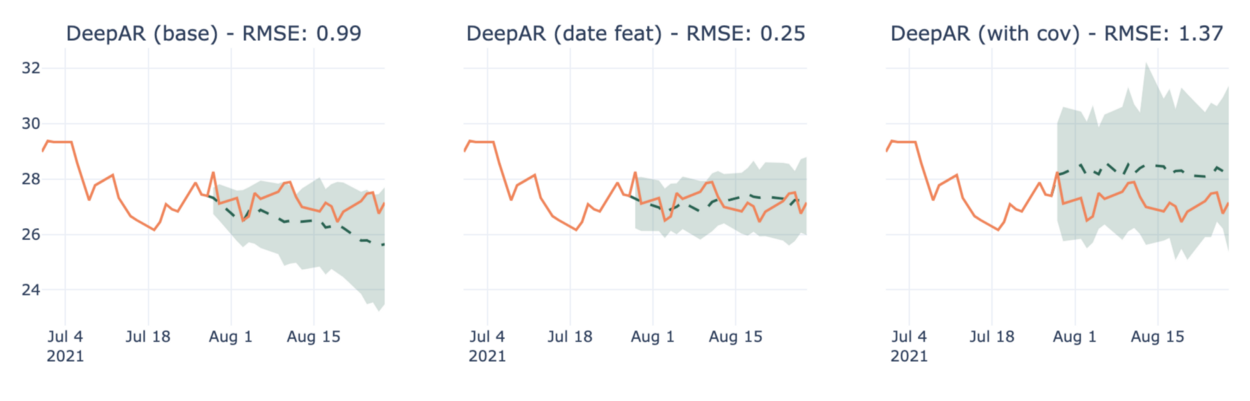
Figure 10— Forecasts for Discovery Communications-C using DeepAR in multiple scenarios
3. DeepAR의 사용은 평균적으로 결과를 개선하지만, 항상 그렇지는 않고 회사에 따라 크게 달라진다.
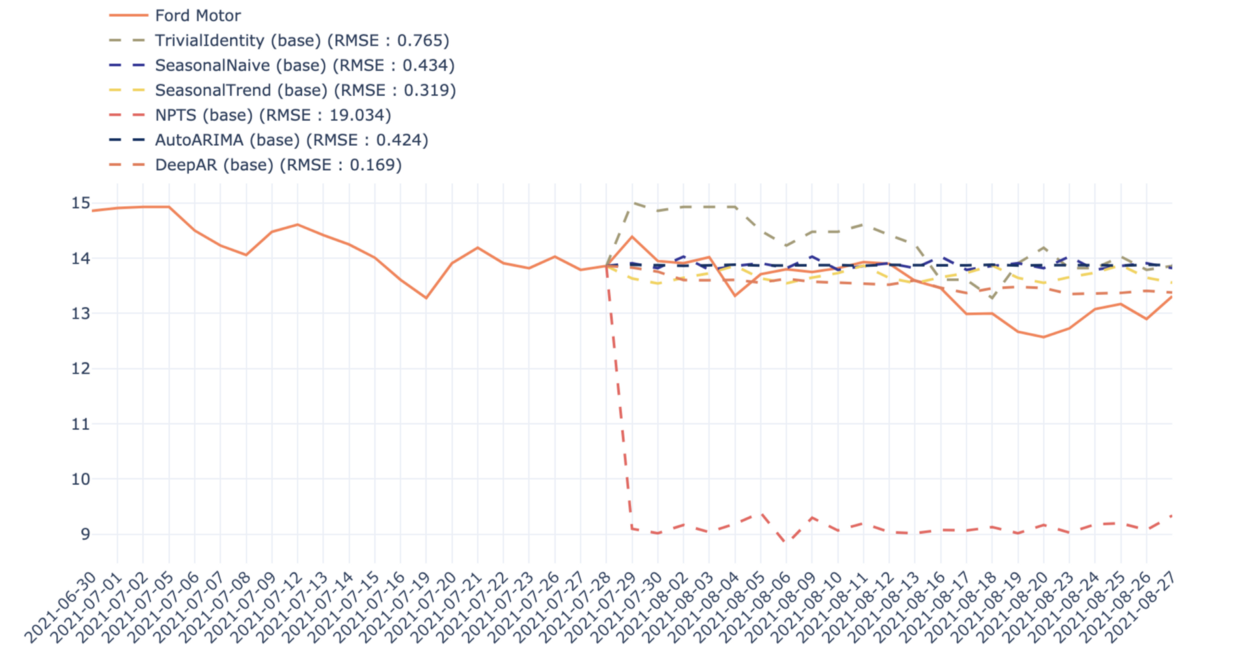
Figure 11 — Comparison between different models for the prediction of Ford Motor stock price in the first scenario
주식시장에서 30일이 긴 기간이라는 점도 언급할 만하다.
결론
이번 포스팅에서, 시계열 예측의 맥락에서우리는 Seq2Seq와 DeepAR 모델의 이론적 원리에 대해 알아 보았다. 다음 포스팅에서는 NLP 분야에서 매우 인기 있는 모델을 살펴볼 것이다. Seq2Seq, DeepAR과 어떻게 다른지 알아보고 모델을 사용하여 시계열 활용이 더 나은 결과를 얻을 수 있는지 탐구한다.
참조
위에 제시된 실험은 Python 코드 외에 플러그인 시계열 준비 및 시계열 예측을 사용하여 Dataiku에서 수행되었다. 훈련된 모델은 파이썬 라이브러리 pyramid를 기반으로하는 AutoArima를 제외하고 GluonTS 라이브러리를 기반으로한다.
[1] D. Salinas, V. Flunkert, J. Gasthaus, DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks, April 2017
[2] Z. Tang, P.A. Fishwik, Feedforward Neural Nets as Models for Time Series Forecasting, November 1993
[3] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning: adaptive computation and machine learning. MIT Press, 2016
[4] A. Amidi, S. Amidi, Stanford CS 230, Deep Learning
[5] J. Brownlee, Multi-Step LSTM Time Series Forecasting Models for Power Usage, October 2018
[6] Tensorflow Tutorials, Time series forecasting
번역 – 핀인사이트 인턴연구원 강지윤(shety0427@gmail.com)
원문 보러가기>
