
News & Events
Keras(머신러닝)를 이용한 주식 거래

* 이 글은 medium에작성된 Yacoub John Oh의 글을 번역하였습니다.
LDR: 주식 시장에서, 과거 실적이 항상 미래 수익률을 예측하기 좋은 것은 아니다. 그리고 이는 머신러닝을 이용한 주가 예측을 어렵게 만든다. 그럼에도 불구하고, 필자의 시도는 여기서 찾을 수 있다.
*사전 요구 사항: Python
머신러닝(ML)은 관련된 전문 용어와 수학 때문에 이해하기 어려울 수 있다. 이 포스팅에서는 기존 리소스를 다시 작성하지 않고 해당되는 곳이면 언제든지 참조할 수 있도록 최대한 단순하고 DRY한 상태를 유지하려고 한다.필자는 이 주제를 공부할 때 생각했던 질문들을 통합했다. 이 포스팅에서 당신이 가질 수 있는 몇 가지 의문을 해결할 수 있길 바란다. 이번 포스팅을 통해 (1) ML의 작동 방식에 대한 일반적인 이해와 (2) 간단한 주식 거래 ML 알고리즘을 구축할 수 있기를 바란다. 현재로서는 수익을 내는 것이 우리의 목표가 아니라는 점에 유의하자. 우리의 첫 번째 단계는 주가 예측에 ML을 적용하는 것이다. 하지만, 필자는 이 하나의 포스팅에 처음부터 끝까지 거래 알고리즘을 구축하는 데 필요한 거의 모든 것을 정리했다. 이게 도움이 되길 바란다!
기계 학습 알고리즘의 전형적인 구조를 살펴보자. 아래는 머신 러닝 알고리즘의 작동 방식에 대한 간단한 설명이다.

이제 데이터 준비부터 시작하여 현재 어떤 상황이 벌어지고 있는지 자세히 살펴보자. 우리는 당신이 케라스를 사용하고 있다고 가정하고 있다.
1단계. input이란?
데이터 준비. 주식 데이터를 분석하는 경우, LSTM(Long Short-Term Memory) 레이어를 통합하는 것이 가장 합리적인데, 이는 이전 시계열 데이터의 메모리를 유지하는 반면 밀집 층만 갖는 것은 그것의 즉각적인 과거로부터만 통찰력을 얻을 수 있기 때문이다.
이 단계에서 알아야 할 것은 어떤 모델(예: dense, LSTM 등)을 선택하느냐에 따라 입력을 3차원으로 다시 조정해야 할 수 있다는 것이다. 2D 데이터가 있는 경우 아래 코드를 수행하여 3D로 변경할 수 있다.
2D_train_data = np.reshape(2D_train_data, (2D_train_data.shape[0], 2D_train_data.shape[1], 1))
예를 들어 1열은 기업별 주가를, 2열은 분당 주가를, 3열은 일별 데이터를 나타내는 시시각각 주식 데이터를 3D로 나타낼 수 있다.

데이터를 준비하는 마법은 없다. Keras 설명서는 훌륭하며, 입력/출력 사양을 명확하게 설명한다. Scikit-Learn은 입력 데이터를 표준화하는 데 유용한 Python 모듈이며, 필요한 경우 야후 파이낸스나 Quandl과 같은 데이터 공급자를 사용하여 주가 데이터를 수집하여 모델을 교육할 수 있다.
데이터 준비가 완료되면 (1) 사용할 레이어, (2) 사용할 레이어 수, (3) 사용할 손실 함수와 최적화 도구 세 가지 질문에 답해야 한다.
Related resources: Scale, Standardize, or Normalize with Scikit-Learn; Udacity — Intro to data science course
2단계. input의 이동 경로
이 부분은 마법이 일어나는 곳이다! 바로 살펴보자.
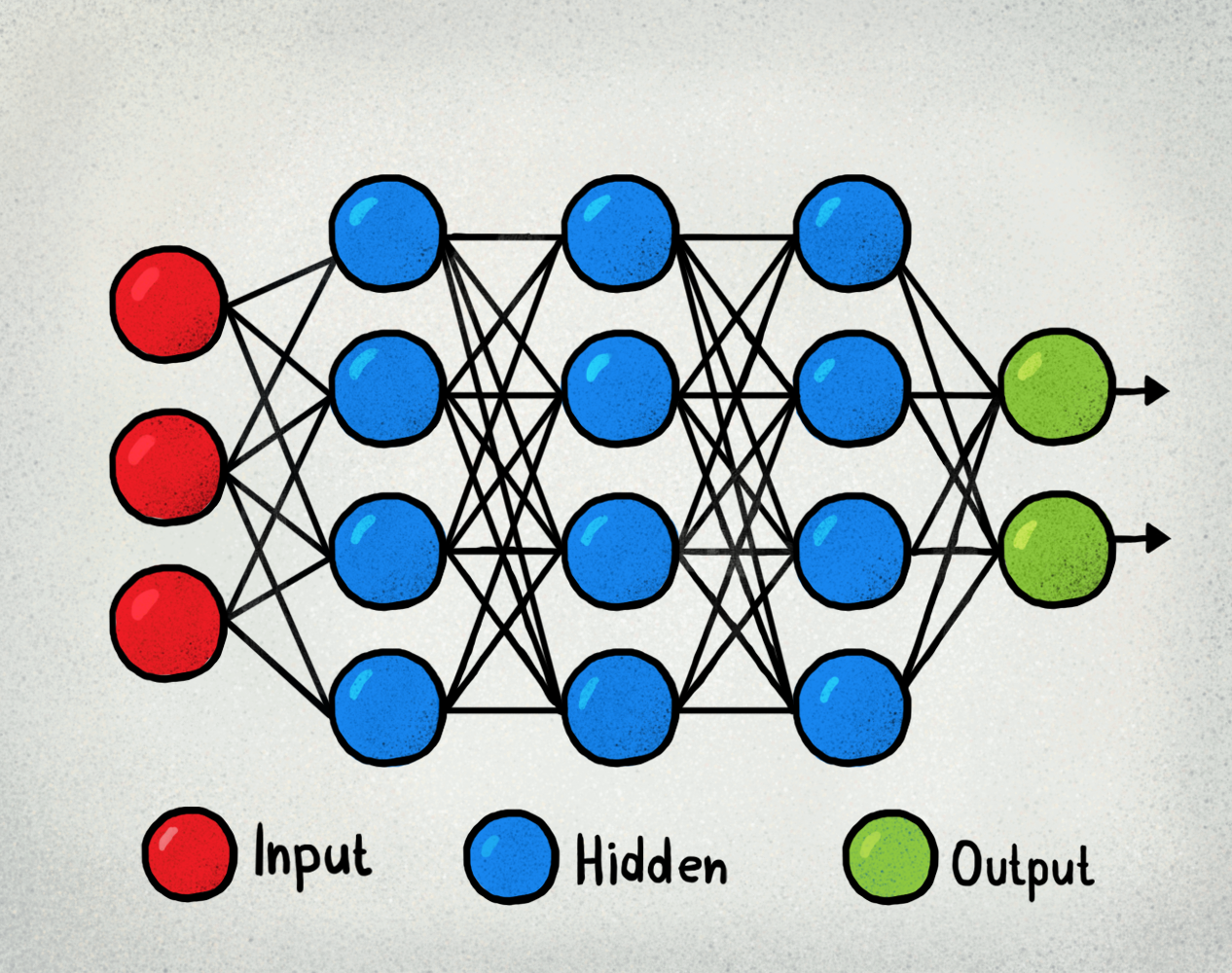
레이어. 이것이 신경망의 핵심 구성 요소이다. 데이터가 보다 정교해지기 위해 거쳐야 하는 필터라고 생각할 수 있다. 당신은 이런 종류의 그래프를 봤을지도 모른다. 누군가가 머신러닝이나 신경망을 설명하려고 할 때 말이다. 각 원의 클러스터가 레이어을 나타낸다는 점에 유의하자.
질문> 밀집 층이란?
자세한 설명은 여기에서 확인할 수 있다. TLDR: 코어 층, 합성곱 층, 순환 층 등 다양한 유형의 레이어가 있다. 각 범주에는 여러 레이어도 있다. 예를 들어 LSTM, GRU 등이 순환 층 아래에 있다. 밀집 층은 코어 층 아래에 있다. 이러한 레이어들은 입력과 출력 사이에 위치하며, 각 레이어에는 선택된 손실 함수의 로스 값을 최소화하기 위해 최적화 함수가 업데이트하는 “가중치”가 있다. 우리는 곧 손실 함수와 옵티마이저를 다시 살펴볼 것이다.
질문> 더 많은 레이어가 더 나은 결과로 이어질까?
꼭 그렇다 할 수는 없다. 더 많은 레이어를 구현하면 과적합이 발생할 수 있으며, 이는 본질적으로 모델이 훈련 데이터를 기억할 것이고, 테스트 데이터를 사용할 때 잘 예측하지 못할 것이라는 것을 의미한다(즉, 잘 일반화되지 않을 것이다). 주가를 정확히 예측하지 못할 것이란 얘기다. 몇 개의 레이어를 사용할지에 대한 자세한 내용은 “인공 신경망에서 몇 개의 히든 레이어/뉴런을 사용할 것인가?“을 참고하자.
손실함수. 어떤 손실 함수를 선택하든, 그것의 기본 업무는 훈련 데이터의 예상 결과와 레이어로부터의 출력을 비교하고 오류를 알아내는 것인데, 이것은 모델의 출력이 예상 결과로부터 얼마나 떨어져 있는지를 나타낸다. 평균 제곱 오차(MSE), 평균 절대 오차(MAE), 범주형 교차 엔트로피, 이진 교차 엔트로피 등과 같은 많은 손실함수가 있다. 사용할 손실 함수를 결정할 때는 설명서를 참조하자.
수행하는 작업에 따라 적은 양으로 떨어져 있는 것은 문제가 되지 않을 수 있지만, 많은 양으로 떨어져 있는 것은 매우 비용이 많이 든다. 오류가 증가함에 따라 오류의 제곱이 기하급수적으로 증가하기 때문에 MSE를 사용하는 것이 합리적이다. 주식을 거래할 때, 5달러씩 하락하는 것은 정확히 1달러를 잃는 것보다 5배 더 나쁘다. 따라서 MAE를 사용하는 것이 타당하다. 그러나 결론에서 참조한 연구 논문에서 보듯이 다른 손실 함수를 구현할 수 있다.
모델을 교육하는 동안 손실은 처음에는 랜덤에 가까울 것이다. 예를 들어, 모델이 주가 상승 또는 하락 여부를 예측하려고 하면 데이터나 컨텍스트가 없기 때문에 처음에는 추정해야 하며, 그 결과 정확도가 50% 이상, 부정확도가 50%에 이를 가능성이 높다. 그러나 모델은 많은 반복, 즉 “epochs”에 대해 훈련할 때, 잘못된 추측의 수인 손실을 최적화(이 경우, 최소화)하려고 할 때, 훈련 데이터를 사용하여 미래의 결과를 더 잘 예측하는 방법을 “학습”한다. 여기서 옵티마이저가 등장한다.
옵티마이저. 경사 하강법을 사용하여 다음 시기의 가중치(커널 속성)와 편향을 업데이트하여 이전보다 더 낮은 손실을 초래한다. 이게 무슨 뜻일까?
당신은 어떤 것의 최소치를 어떻게 찾나? 기초 미적분학을 기억하고 있다면 그래프를 만들어서 로컬 최소값을 찾을 수 있다. 여기서 파생된 값이 0이 되는 곳을 찾아보자. 로컬 최소값이 글로벌 최소값이 아닐 때처럼 복잡한 경우가 더 있지만, 일단은 무시하고 기본 개념을 이해하는 데 집중하자.
예를 들어 이 그래프에서 모형을 처음 실행한 후 초기 손실 값이 빨간색 점일 수 있다. 옵티마이저는 파란색 점을 살펴보고 파생값이 음수임을 확인할 수 있다. 따라서 녹색 점 쪽으로 오른쪽으로 이동하면 손실이 줄어든다. 따라서 옵티마이저는 손실 값이 오른쪽으로 한 단계 이동하도록 층의 가중치를 조정한다. 취한 단계의 크기를 “학습 속도”라고도 한다.

각 에포크마다 이렇게 하면 훈련 오류가 낮아진다! 하지만 한가지 주의사항이 있다:
그것은 과적합으로 이어질 수 있다. 이는 다음 단계의 주제이다.
3단계. 그래서?
평가. History 객체를 사용하여 서로 다른 개수의 에포크에 대한 손실을 평가할 수 있다. 여기에는 훈련 중 발생한 일에 대한 데이터가 들어 있는 “History” 딕셔너리가 들어 있다. 우리는 히스토리 손실을 그래프로 나타낼 수 있고 얼마나 많은 에포크가 과적합을 최소화하는지 알 수 있다. 과적합에 대한 자세한 내용은 여기에서 확인할 수 있다.

이 때 현재 보유하고 있는 코드를 수정하여 자유롭게 실험하고 새로운 모델과 다른 에포크 및 배치 크기를 시도해야 한다! 아이러니하게 들릴지 모르지만, 이 비과학적인 과정 때문에 이 분야의 일부 전문가들은 기계 학습이 현재 과학보다 더 예술적이라고 말한다.
Robinhood를 사용한 구현. 로빈후드 모듈을 사용한 코드 예는 로빈후드: 자동화된 거래 시스템 구축을 참조하자. 이 단계를 완료하려면 로빈후드 계정을 만들어야 한다.
Conclusion
필자는 이 포스팅이 (케라스를 사용하는) 머신러닝 알고리즘의 전형적인 구조에 대한 이해를 굳히는 데 도움이 되었기를 바란다. 관심 있으면 케라스의 소스 코드를 확인해 보자. 기계 학습을 사용하여 Keras와 주식 거래에 대해 자세히 알고 싶다면 Francois Chollet의 “Deep Learning with Python”과 “Deep Convolutional Neural Network를 사용한 알고리즘 금융 거래: Omer Berat Sezer와 Ahmet Murat Ozbayoglu의 영상 시리즈 변환 접근법”을 추천한다.
오늘 배운 딥러닝은 5월 29일(토)에 개설되는
[실시간 온라인] 파이썬과 케라스를 이용한 딥러닝/강화학습 주식투자
강의를 통해 심화하여 학습할 수 있습니다.
번역 – 핀인사이트 인턴연구원 강지윤(shety0427@gmail.com)
원문 보러가기>

{kind=link}