
News & Events
시계열 예측: LSTM 모델로 주가 예측하기


해당 포스팅에서는 LSTM 예측 모델을 사용하여 주가를 예측하는 방법을 제시한다.

1. 도입
1.1. 시계열 & 예측모델
전통적으로 대부분의 머신러닝(ML) 모델은 일부 관찰(샘플/예제)을 입력 피쳐로 사용하지만 데이터에 시간 차원은 없다.
시계열 예측 모형은 이전에 관측된 값을 기반으로 미래의 값을 예측할 수 있는 모형이다.
시계열 예측은 비정형 데이터에서 널리 사용된다. 평균 및 표준 편차와 같은 통계적 특성이 시간이 지남에 따라 일정하지 않은 데이터를 비정형 데이터라고 한다.
이러한 비정형 입력 데이터(해당 모델에 대한 입력으로 사용)를 일반적으로 시계열이라고 한다. 시계열의 예로는 시간 경과에 따른 온도, 주가, 주택 가격 등이 있다. 따라서 입력은 시간에 따라 연속적으로 나타나는 신호(시계열)이다.
시계열은 시간에 따라 순차적으로 취하는 일련의 관측치이다.

관측: 시계열 데이터는 개별 시간 척도로 기록된다.
주의: 시계열 분석 알고리즘을 사용하여 주가를 예측하려는 시도가 있었지만, 실제 시장에서 베팅을 하기는 힘들다. 이 포스팅은 단지 사람들에게 주식을 사도록 “지시”하려는 의도가 전혀 없는 튜토리얼일 뿐이다.
2. LSTM 모델
LSTM은 딥러닝 분야에 사용되는 순환신경망(RNN) 아키텍처이다. 표준 피드포워드 신경망과 달리 LSTM은 피드백 연결이 있다. 단일 데이터 포인트(예: 이미지)뿐만 아니라 전체 데이터 시퀀스(예: 음성 또는 비디오 입력)도 처리할 수 있다.
LSTM 모델은 일정 기간 동안 정보를 저장할 수 있다.
한마디로 기억력을 가지고 있다는 것이다. LSTM은 장기 메모리 모델을 의미한다.
이 특성은 시계열 또는 시퀀스 데이터를 처리할 때 매우 유용하다. LSTM 모델을 사용할 때 우리는 어떤 정보를 저장하고 어떤 정보를 버릴지 결정할 수 있다. 우리는 “게이트”를 사용한다. LSTM에 대한 깊은 이해는 이 포스팅의 범위 밖이지만, 더 많은 것을 알고 싶다면 이 게시물 끝에 있는 참고 자료를 살펴보자.
3. 주가 기록 데이터 가져오기
야후 파이낸스 덕분에 우리는 무료로 데이터를 얻을 수 있다. 다음 링크를 사용하여 테슬라의 주가 기록을 확인해보자.
다음 사항을 확인해야 한다:
다운로드를 클릭하고 .csv 파일을 컴퓨터에 로컬로 저장한다.
데이터는 2015년부터 현재까지(2020년)이다!
4. 파이썬 작업 예제
필요한 모듈: Keras, Tensorflow, Pandas, Scikit-Learn & Numpy
우리는 이 예에서 테슬라 주가를 예측하기 위해 다층 LSTM 순환 신경망을 구축할 것이다.
데이터를 로드하고 검사해 보자.
import math
import matplotlib.pyplot as plt
import keras
import pandas as pd
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
from keras.layers import *
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
from keras.callbacks import EarlyStopping
df=pd.read_csv(“TSLA.csv”)
print(‘Number of rows and columns:’, df.shape)
df.head(5)

Output of the above code
다음 단계는 데이터를 훈련 세트와 테스트 세트로 분할하여 과적합을 피하고 모델의 일반화 능력을 조사할 수 있도록 하는 것이다. 과적합에 대해 자세히 알아보려면 이 포스팅을 참고하자.
예측될 목표값은 주가에 ‘가까운’ 값이 될 것이다.
training_set = df.iloc[:800, 1:2].values
test_set = df.iloc[800:, 1:2].values
모델 적합 전에 데이터를 정규화하는 것이 좋다. 이렇게 하면 성능이 향상된다. Min-Max Scaler에 대한 자세한 내용은 여기에서 확인할 수 있다.
시차가 1일(lag 1)인 입력 피쳐를 구축해 보자.
# Feature Scaling
sc = MinMaxScaler(feature_range = (0, 1))
training_set_scaled = sc.fit_transform(training_set)
# Creating a data structure with 60 time-steps and 1 output
X_train = []
y_train = []
for i in range(60, 800):
X_train.append(training_set_scaled[i-60:i, 0])
y_train.append(training_set_scaled[i, 0])
X_train, y_train = np.array(X_train), np.array(y_train)
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
#(740, 60, 1)
다음, 데이터를 다음과 같은 형식(#값, #타임스텝, #1차원 출력)으로 재배열한다.
자, 이제 모델을 만들 시간이다. 우리는 50개의 뉴런과 4개의 숨겨진 층으로 LSTM을 만들 것이다. 마지막으로, 우리는 정규화된 주가를 예측하기 위해 출력층에 1개의 뉴런을 할당할 것이다. MSE 손실 함수와 Adam stochastic gradient decent optimizer를 사용할 것이다.
참고: 다음은 어느정도 시간이 소요된다(~5분).
model = Sequential()
#Adding the first LSTM layer and some Dropout regularisation
model.add(LSTM(units = 50, return_sequences = True, input_shape = (X_train.shape[1], 1)))
model.add(Dropout(0.2))
# Adding a second LSTM layer and some Dropout regularisation
model.add(LSTM(units = 50, return_sequences = True))
model.add(Dropout(0.2))
# Adding a third LSTM layer and some Dropout regularisation
model.add(LSTM(units = 50, return_sequences = True))
model.add(Dropout(0.2))
# Adding a fourth LSTM layer and some Dropout regularisation
model.add(LSTM(units = 50))
model.add(Dropout(0.2))
# Adding the output layer
model.add(Dense(units = 1))
# Compiling the RNN
model.compile(optimizer = ‘adam’, loss = ‘mean_squared_error’)
# Fitting the RNN to the Training set
model.fit(X_train, y_train, epochs = 100, batch_size = 32)
피팅이 완료되면 다음과 같은 내용을 볼 수 있다.
테스트 데이터 준비(재배열):
# Getting the predicted stock price of 2017
dataset_train = df.iloc[:800, 1:2]
dataset_test = df.iloc[800:, 1:2]
dataset_total = pd.concat((dataset_train, dataset_test), axis = 0)
inputs = dataset_total[len(dataset_total) – len(dataset_test) – 60:].values
inputs = inputs.reshape(-1,1)
inputs = sc.transform(inputs)
X_test = []
for i in range(60, 519):
X_test.append(inputs[i-60:i, 0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
print(X_test.shape)
# (459, 60, 1)
테스트 세트를 사용하여 예측하기
predicted_stock_price = model.predict(X_test)
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
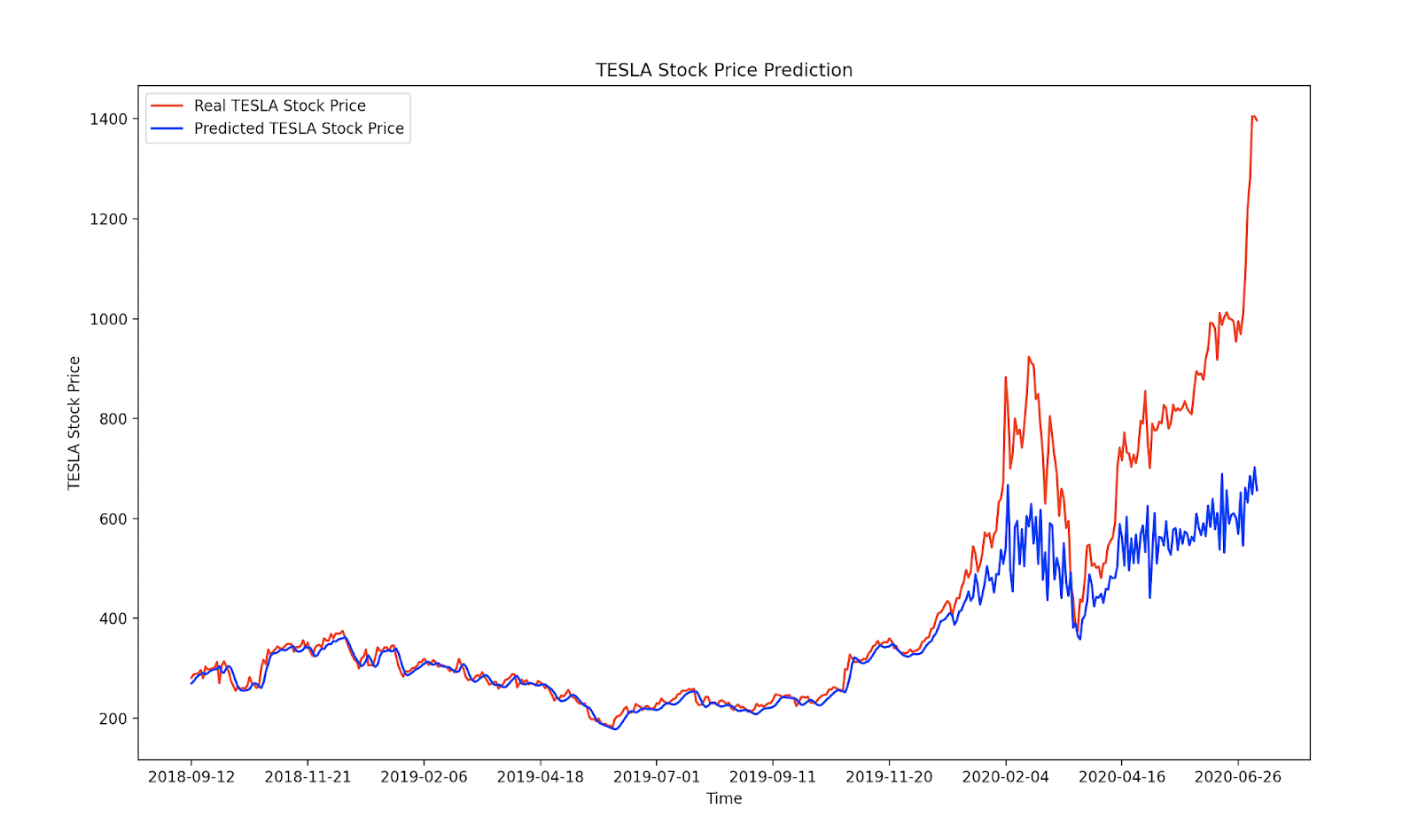
이제 결과를 시각화해 보자:
# Visualising the results
plt.plot(df.loc[800:, ‘Date’],dataset_test.values, color = ‘red’, label = ‘Real TESLA Stock Price’)
plt.plot(df.loc[800:, ‘Date’],predicted_stock_price, color = ‘blue’, label = ‘Predicted TESLA Stock Price’)
plt.xticks(np.arange(0,459,50))
plt.title(‘TESLA Stock Price Prediction’)
plt.xlabel(‘Time’)
plt.ylabel(‘TESLA Stock Price’)
plt.legend()
plt.show()
5. 결과
1의 시차 (하루):

관측: COVID-19 봉쇄로 인한 2020년 3월 큰 하락!
우리는 우리의 모델이 매우 잘 수행되었다는 것을 분명히 알 수 있다.그러나 가장 최근의 날짜 스탬프에 대해서는 모델이 주가의 실제 가치에 비해 낮은 값을 예상(예측)했음을 알 수 있다.
lag에 대한 참고 사항
이 포스팅에서 처음 선택한 lag는 1일, 즉 1일의 단계를 사용한 것이다. 이는 3D 입력을 작성하는 코드를 변경하여 쉽게 변경할 수 있다.
예: One can change the following 2 blocks of code:
X_train = []
y_train = []
for i in range(60, 800):
X_train.append(training_set_scaled[i-60:i, 0])
y_train.append(training_set_scaled[i, 0])
그리고
X_test = []
y_test = []
for i in range(60, 519):
X_test.append(inputs[i-60:i, 0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
다음과 같은 새 코드를 사용한다.
X_train = []
y_train = []
for i in range(60, 800):
X_train.append(training_set_scaled[i-50:i, 0])
y_train.append(training_set_scaled[i, 0])
그리고
X_test = []
y_test = []
for i in range(60, 519):
X_test.append(inputs[i-50:i, 0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
이 경우 결과는 다음과 같다.
이상이다! 이번 포스팅이 마음에 들었길 바라!
아래는 구글 주가를 예측하기 위해 사용했던 페이스북 Prophet 모델을 다룬 포스팅이다.
ARIMA 모델을 사용하여 최근에 작성한 포스팅도 확인해보자.
레퍼런스
[1] https://colah.github.io/posts/2015-08-Understanding-LSTMs/
[2] https://en.wikipedia.org/wiki/Long_short-term_memory
번역 – 핀인사이트 인턴연구원 강지윤(shety0427@gmail.com)
원문 보러가기>
