
News & Events
LSTM과 로지스틱 회귀 분석을 사용한 가짜 뉴스 분류



Tensorflow, Keras, DataSpell, Scikit-Learn, PyCharm
가짜뉴스는 지난 몇 년간 언론에서 논의의 초점이 되었다. 따라서 가짜 뉴스와 진짜 뉴스를 정확하게 분류하는 자동화된 방법이 필요하다.
이 게시물은 루머와 가짜 뉴스의 확산을 방지하고, 사람들이 JetBrains의 최신 데이터 사이언스 IDE인 DataSpell을 사용하여 뉴스를 자동으로 분류하여 신뢰할 수 있는 뉴스인지 아닌지를 확인하는 데 도움을 줄 것이다.
데이터
데이터 세트는 44,919개의 뉴스 기사로 구성되며 실제 뉴스와 가짜 뉴스는 거의 동일하게 구성된다.
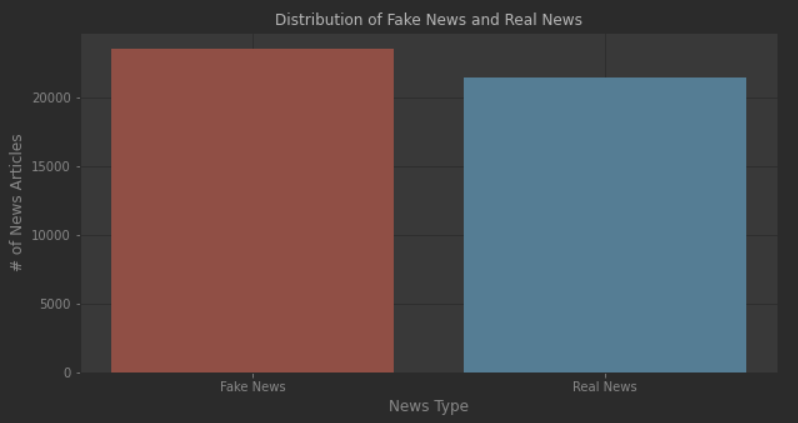
실제 기사들은 로이터 웹사이트에서 수집되었고, 다양한 출처의 가짜 기사들은 위키피디아와 폴리텍트에 의해 가짜 출처로 플래그가 지정되었다. 데이터 세트는 각 기사의 전체 본문, 제목, 날짜 및 주제로 구성된다. 빅토리아 대학교 ISOT 연구소의 도움으로, 데이터 세트는 여기에서 다운로드 할 수 있다. 우리는 LSTM과 같은 최첨단 접근 방식과 로지스틱 회귀 분석을 비교할 것이다.
DataSpell
DataSpell을 다운로드하는 방법은 여러 가지가 있는데, 툴박스에 있는 다른 JetBrains의 도구를 사용하지 않을 계획이라면 가장 간단한 방법은 웹 사이트에서 직접 다운로드하는 것이다.
데이터스펠을 실행하면 다음과 같은 화면이 나타난다. 만약 데이터 스펠을 처음 사용한다면, 환경은 필자보다 훨씬 깨끗해야 한다. 필자는 dsProject_LogReg_DL이라는 프로젝트를 만들었고, 프로젝트 아래에 Fake.csv와 True.csv를 로드한 data 폴더를 만들었다. 또한 동일한 디렉터리에 FakeNew_DL.ipynb 및 FakeNew_LogReg.ipynb를 마우스 오른쪽 버튼으로 클릭하여 두 개의 Jupyter 노트북을 만들었다.
필자는 데이터 사이언티스트로서 주피터 노트북을 많이 사용한다. DataSpell은 JupyterLab과 유사한 인터페이스를 제공하며 데이터 프레임과의 상호 작용, 스마트 코딩 지원 등과 같은 몇 가지 새로운 기능을 제공한다.
딥러닝
이 섹션에서는 전처리 기법의 개요와 분류에 사용되는 딥러닝 모델에 대한 설명을 제공한다.
딥러닝 모델과 로지스틱 회귀 분석 모델을 유의미하게 비교하기 위해 노트북 시작 시간과 노트북 끝의 종료 시간을 추가한 다음 전체 코드를 실행하는 데 걸린 시간을 계산한다.

전처리
다음 단계에서는 데이터 전처리 프로세스의 일부를 시연했다.
- Fake.csv 밑 True.csv를 로드한다.
- 쓸데없는 칼럼은 제거한다, title 과 text만 있으면 된다.
- 가짜 뉴스는 0으로, 진짜 뉴스는 1로 라벨링한다.
- 두 개의 데이터 프레임을 하나로 연결한다.
“새 탭에서 열기”를 클릭하고 데이터 프레임이 크면 스크롤 막대를 사용하여 전체 데이터 프레임을 볼 수 있다.
다음 단계에서, 우리는
- 제목과 텍스트를 하나의 열에 결합한다.
- 소문자와 같은 표준 텍스트 클리닝 프로세스, 공백 및 URL 링크를 제거한다.
- 교육 및 검정 데이터를 분할하는 방법은 딥 러닝 모형과 로지스틱 회귀 분석의 경우와 동일해야 한다.
- 변경과 편집이 쉽도록 위에 파라미터를 이렇게 배치했다.

토큰화
- 토크나이저는 우리를 위해 모든 리프팅을 한다. 토큰화한 기사(제목+텍스트)에서 가장 일반적인 단어 10,000개를 필요로 한다. oov_tok은 보이지 않는 단어가 발견되는 곳에 특별한 값을 넣는 것이다. 즉, 단어 인덱스에 없는 단어에는 괄호 안의 “OOV”를 사용한다. fit_on_text는 모든 텍스트를 검토하여 딕셔너리를 만든다.
- 토큰화 후, 다음 단계는 이러한 토큰을 시퀀스의 리스트로 변환하는 것이다.
- NLP를 위해 신경망을 훈련시킬 때, 우리는 같은 크기의 시퀀스를 필요로 하기 때문에 패딩을 사용한다. 우리의 max_length는 256이므로 pad_sequence를 사용하여 모든 기사(제목 + 텍스트)의 길이를 256으로 동일하게 만든다.
- 또한 padding 유형과 truncating 유형이 있으며, 둘 다 “post”로 설정한다. 예를 들어 길이가 200인 기사 하나가 256으로 패딩되고 끝에 패딩되어 56개의 0이 추가된다.

모델 구축
이제 LSTM을 구현할 수 있다. 필자의 코드는 tf.keras.Sequential 모델이고 임베딩 레이어부터 시작한다.
- 내장 레이어는 단어당 하나의 벡터를 저장한다. 호출되면 단어 인덱스 시퀀스를 벡터 시퀀스로 변환한다. 훈련 후, 비슷한 의미를 가진 단어들은 종종 비슷한 벡터를 가진다.
- 다음은 LSTM을 코드로 구현하는 방법이다. 양방향 래퍼(wrapper)는 LSTM 레이어와 함께 사용되며, LSTM 레이어를 통해 입력을 앞뒤로 전파한 다음 출력을 연결한다. 이를 통해 LSTM은 장기적인 의존성을 학습할 수 있다. 그런 다음 우리는 그것을 밀집된 신경망에 맞춰 분류한다.
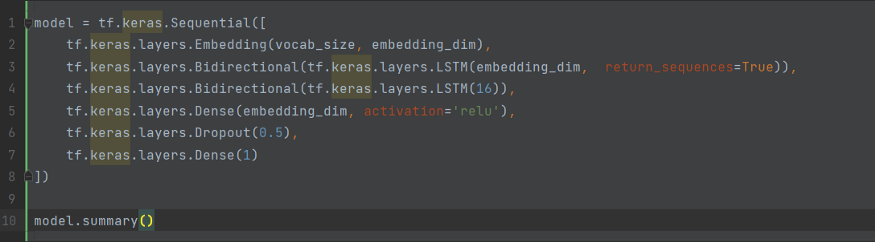
- 모델 요약에는 임베딩이 있고 양방향에는 LSTM이 포함되어 있으며 그 뒤에 두 개의 밀도 높은 레이어가 있다. 양방향의 출력은 128로 LSTM의 두 배이다. 필자는 또한 결과를 개선하기 위해 LSTM 레이어를 쌓았다.
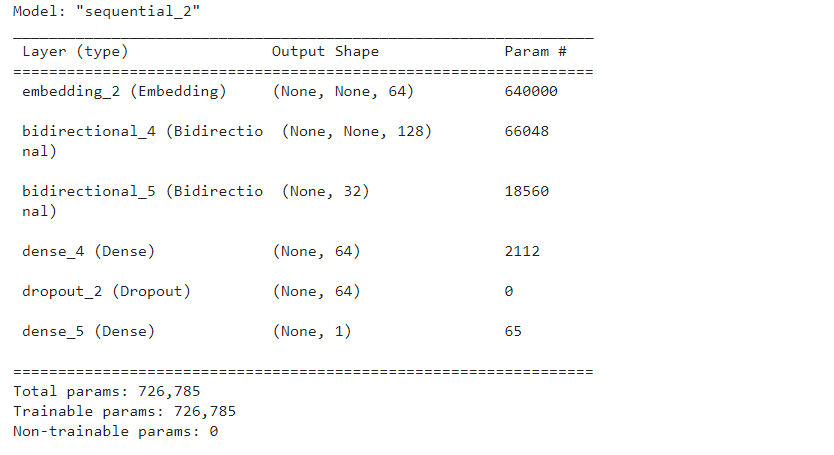
- 우리는 유효성 검사 손실이 더 이상 개선되지 않을 때 멈추는 얼리 스탑을 사용하고 있다.
- 시간 경과에 따른 훈련을 시각화하니 결과가 좋았다.
로지스틱 회귀 분석
이번에는 동일한 데이터 세트, 동일한 텍스트 정리 방법 및 train_test_split 을 사용하여 뉴스를 실제 또는 가짜로 분류하는 간단한 로지스틱 회귀 모델을 만들것이다.
그 과정은 매우 간단하고 쉽다. 텍스트 데이터를 정리 및 전처리하고, NLTK 라이브러리를 사용하여 피쳐 추출을 수행하고, Scikit-Learn 라이브러리를 사용하여 로지스틱 회귀 분류기를 구축 및 배포하고, 마지막에 모델의 정확도를 평가할 것이다.
전처리
- 다음 전처리에서는 html 태그와 구두점을 모두 제거하고 소문자로 만든다.

- 다음 코드는 토큰화와 스테밍 기술을 함께 결합한 다음 “title_text”에 기술을 적용한다.

TF-IDF
여기서 우리는 “title_text” 피쳐를 TF-IDF 벡터로 변환한다.
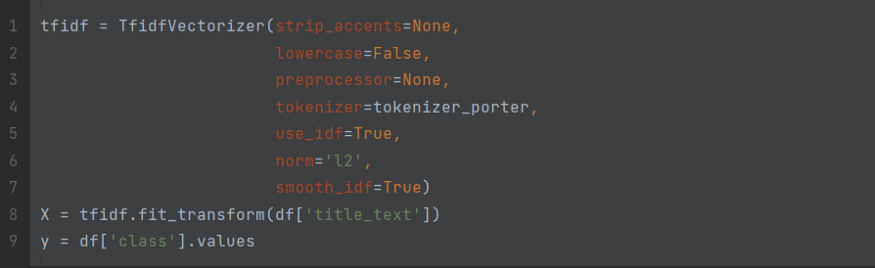
- 수동으로 C 파라미터를 조정하는 대신 LogisticRegressionCV인 추정량을 사용할 수 있다.
- 우리는 이 하이퍼 파라미터를 조정하기 위해 교차 검증 폴드 수 cv=5를 지정한다.
- 모델의 측정은 분류의 정확성이다.
- n_jobs=-1을 설정하여 모든 CPU 코어를 전용으로 사용하여 문제를 해결한다.
- 최적화 알고리즘의 반복 횟수를 최대화한다.

- 성과를 평가한다.
마무리
딥러닝 모델과 로지스틱 회귀 분석에서 유사한 결과가 나왔다. 로지스틱 회귀 분석에 대한 훈련 시간이 딥러닝에서의 훈련 시간의 절반임을 알 수 있었다.
분명한 차이점은 심층 신경망이 로지스틱 회귀 분석보다 훨씬 더 많은 모수와 더 많은 모수의 순열을 추정한다는 것이다. 기본적으로, 우리는 로지스틱 회귀를 하나의 층 신경망으로 생각할 수 있다.
요약하자면 우선 간단한 모형(예: 로지스틱 회귀 분석)으로 분류 문제를 해결하는 것이 좋다. 위의 예에서, 로지스틱 회귀 분석으로 이미 문제를 충분히 잘 해결했을 것이다. 물론 다른 경우에는 단순 모델의 성능이 만족스럽지 않고 충분한 훈련 데이터가 있을 때 보다 복잡한 비선형 함수를 학습할 수 있는 이점을 가진 심층 신경망을 훈련시키려 할 것이다.
프로젝트 저장소는 Github에서 찾을 수 있다.
번역 – 핀인사이트 인턴연구원 강지윤(shety0427@gmail.com)
원문 보러가기>
https://actsusanli.medium.com/fake-news-classification-with-lstm-or-logistic-regression-82a3527aaf13
