
News & Events
[Reinforcement Learning] 2. Reinforcement Learning 소개

Deepmind에 David silver 교수님의 강의를 기반으로 하여 강화학습에 대한 이론적인 내용들을 하나씩 살펴 보겠습니다.
강의 영상과 자료들은 아래의 링크에서 볼 수 있습니다.
http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
1. About RL
강화학습(RL)은 1979년도에 처음 시작했다고 서튼 교수님의 책에서 말씀하시고 계십니다. 어떻게 생각하면 오래된 것이고 또 다르게 보면 얼마 안된 분야라고도 할 수 있겠지만, 제 인생만큼 같이 발전되어온 분야라고 하니 더욱 관심이 가네요^^
강화학습은 컴퓨터 사이언스 분야에서 머신러닝의 한 분야에서 사용되기도 하지만, 그 외에 다른 다양한 분양에서도 다른 이름으로 비슷하게 적용이 되고 있습니다. 엔지니어 분야에서 최적의 제어를 위한 방법을 찾을때도 이러한 방식이 사용되고 있으며 인간의 뇌과학 분야에서도 사람이 경험을 통해서 얻게 되는 보상이라는 시스템이 작용되는 방식을 설명하기도 합니다.
컴퓨터 분야에서는 오른쪽 이미지와 같이 대표적인 머신러닝의 3대 축 중에서 하나를 차지할 만큼 대표적인 분야가 됩니다. 시작은 각기 다른 상황에 맞게 연구가 되어오고 있던 내용들이 지금은 점차적으로 융합되어 가고 있기도 합니다.

강화학습이 가지고 있는 특별한 특징들을 위에서 열거를 해놓았습니다.
RL은 supervised learning 의 것과 다르게 누군가가 정답을 알려주지 않습니다. 입력과 결과 데이터 사이의 hidden structure를 찾는 것이 아니라 오로지 reward 라고 하는 보상 시스템에 따라서 학습을 하는 것이 큰 차이점이라고 할 수 있겠습니다.
하지만 이런 보상은 바로 주어지는 경우도 있겠지만, 어떠한 선택을 한 결과가 좋은 결과인지 여부는 이후 다음, 다음, 다음의 먼 미래에 주어질 수도 있게 됩니다. 그렇기 때문에 어느정도 수준의 delay가 존재하게 될 것입니다.
선택과 보상 결과에 대한 행위들이 반복적으로 순차적으로 나타나기 때문에 이러한 것에 있어서 너무 오랜 시간이 소요가 되면 안될 것입니다. 최적의 결과를 위한 선택들도 중요하겠지만 빠른 시간에 최적의 선택들을 찾아내는 것도 중요하겠지요.
Agent 라고 하는 ‘선택를 하고 액션을 취하는 주체’는 자신의 행동에 따라서(외출한다) 그 다음에 어떠한 정보들이 결과로 받게 되어질지가 결정이 되고, 이것은 같은 상황에서 다른 행동을 취했을 때(그냥잔다) 얻게 되는 정보들과는 상이하게 될 것입니다.
https://www.youtube.com/embed/0JL04JJjocc
강화학습을 이용해서 핼리콥터가 스스로 학습하고 다양한 쇼를 보여주는 동영상으로 예제를 대신합니다.^^
2. RL problem

어떤 선택에 대한 결과가 reward(보상)로 주어진다고 했는데 이 값은 숫자 값입니다. 좋은 결과가 나타났다면 양의 수가 될수도 있고 만약 나쁜 결과가 나타났다면 음의 수가 될 수도 있겠습니다.
이를 기호로 다시 표현하면 특정 time step인 step t 에서 어떤 행동을 했는지에 따라서 결과가 달라진다 입니다. 우리의 목표는 최상의 보상을 결과로 하는 행동들을 하는 것이 최종 목표가 됩니다. 기대하는 보상이 큰 쪽으로 행동을 하는 것이 효과적일 것이겠지요. 또는 기대 수익이 높은 상품에 투자를 하는 것이 현명한 선택이 될 것입니다.

좀 더 크게 본다면 지금 당장의 보상보다는 미래의 받게 될 모든 보상의 총 합을 크게 키우는 것이 더 좋을 겁니다. 하나의 선택이 하나의 결과를 만들어 내는 경우가 많치 않기 때문에 다양한 선택과 행동들이 만들어 낼 보상을 크게 보고 생각하는 것입니다. 그래서 현재의 달콤한 보상에 휘둘리는 행동 보다는 장기적인 관점에서 보상이 클 것으로 예상하는 행동을 하는 것이 더 이득입니다.
주식 투자를 하더라도 데일리 트레이딩을 하는 것보다는 장기투자를 하는 것이 더 좋은 이유와 다르지 않는 것 같네요.

행동을 하는 주체(Agent)는 항상 어떠한 환경(Environment) 속에서 존재하고 있습니다. 이 둘 간에 상호작용으로서 Agent는 어떤 행동을 할 지에 대한 선택을 하게 됩니다. 그 행동이 어떠한 보상을 줄 것이라는 기대를 하고 말입니다. 그러한 보상을 주는 주체는 자신이 아니라 환경이 주게 됩니다. 이러한 상호 관계를 잘 표현하는 그림을 한번 보시길 바랍니다.
특정 step t 에서의 Agent 는 주변을 관찰합니다. 내 주위에 어떤 매력적인 이성이 있는지 살펴 봐야겠지요. 매력적인 이성이 발견이 되지 않았다면 다른 장소로 이동을 해야겠다고 생각할 것입니다. 그리고는 이동하는 행동을 취하게 됩니다. 이동하고 다시 주변 환경을 샆펴봅니다. 매력적인 이성이 발견이 되었고 이 정보를 환경이 주게 됩니다. 발견하자마자 Agent 는 생각합니다. 도망가자!! –; 그렇게 행동했을때 얻는 보상은 말 할 필요가 없져… 바보가 됩니다.
각각의 Agent가 무엇을 하고 어떠한 정보를 받는지 환경이 무엇을 받고 어떠한 정보를 주는지 한번 살펴보시길 바랍니다.

Agent가 Environment에서 어떤 행동을 하고 주변 정보를 관찰하고 그에 대한 보상을 받고 나면, 그 다음 또 다른 행동을 하고 다시 관찰하고 보상을 받는 사이클이 계속 돌아갑니다. 이를 히스토리라고 할 수 있겠습니다. 이러한 히스토리들이 다음에 벌어질 일들에 대해서 영향을 주게 될 겁니다.
이러한 히스토리들이 현재의 어떤 상태를 만들게 되고 이 현재 상태는 다음에 별어질 일에 대한 정보를 가지고 있습니다. 이러한 상태를 State 라고 합니다. 수학적으로 표현을 하면 state는 history의 함수라고 표현할 수 있다고 합니다.
과거에 어떤 행동을 했는가에 따라서 히스토리는 변경이 될 것이고 그에 따라서 현재 상태가 또는 미래의 상태가 달라지게 된다는 것입니다.
그리고 이러한 State는 관점에 따라서 크게 3가지로 구분이 되어집니다.
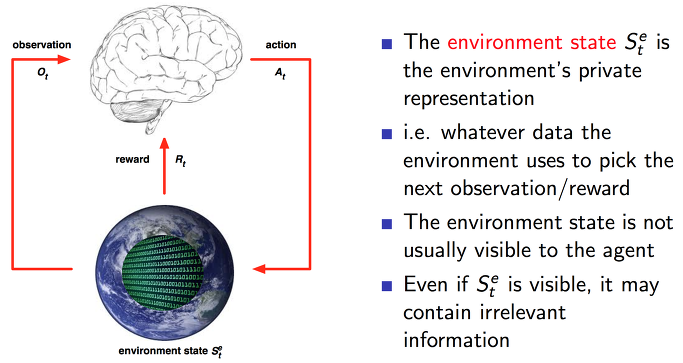
environment state는 환경입장에서의 상태를 말합니다. 환경이 가지고 있는 다양한 정보들이 있을 것인데 이 환경 속에 있는 agent는 모든 환경에 대한 정보들을 볼 수는 없습니다. 우리가 사는 세상에 무수한 일들이 벌어지고 있지만 우리는 모든 정보를 다 알수 없는 것과 동일합니다. 뉴스를 통해 관심있는 소식만 접할 수 있을 뿐입니다.
또는 접하고 있는 모든 뉴스가 우리에게 유용한 정보일리도 없을 것입니다. 정보가 많다고 좋은 선택과 행동을 하는 것과는 관련이 없다는 것을 우리는 어느정도 알고 있기 때문입니다. 이는 강화학습에서도 마찬가지가 됩니다.

agent state는 지구를 살아가고 있는 인간이라고 생각하면 우리 관점에서의 상태를 표현합니다. 우리 주변의 정보나 상태가 아니라 우리 자신에 대한 상태 정보가 됩니다. 우리는 주위에 화장실이 있더라도 몹시 배가 고프면 뭐라도 먹어야 합니다.^^
행동하는 주체자가 되기 때문에 강화학습 알고리즘을 적용하는 핵심 정보가 되기도 합니다. 그리고 우리는 과거의 히스토리에 역시 영향을 받도록 되어 있습니다.

정보 이론 관점에서의 information state 혹은 Markov state 라고 하는 상태가 있습니다. 데이터 관점에서 히스토리의 유용한 정보들을 포함하고 있는 state를 말합니다.
가운데 정의되어 있는 식과 같이 현재 상태의 조건에서 다음 상태가 발생할 확률과 과거의 모든 상태의 조건에서 다음 상태가 발생할 확률이 같을 때, 이 때의 St 는 Markov property라고 할 수 있습니다.
다시 말하면, 현재 주어진 상태는 과거의 모든 히스토리 정보를 포함하고 있기 때문에 현재의 정보가 중요하며, 과거의 정보들은 의미가 없어집니다. 그러므로 미래는 과거와 독립적이다 라고 할 수도 있습니다.
하지만 여기서 미래는 확정이 아니라 가정이기 때문에 확률적으로 접근되어야 합니다.

이번에는 Observation(관찰)에 대해서 살펴봅니다.
환경에서 주는 모든 정보를 Agent가 알수 있는 경우 우리는 Full observability라고 합니다. 즉, 우리가 이 세상에 발생하는 모든 일들을 알고 있는 것과 같습니다. 이 때의 3가지 state는 모두 동일한 정보를 공유하고 있을 것입니다.
이러한 것을 Markov decision process(MDP)라고 하고 이 내용에 대해서는 다음 시간에 다루게 될 것입니다

하지만 일반적으로는 우리는 간접적으로 환경을 접하고 있기에 Partial observability 에 있습니다.
이러한 상태에서는 agent state와 environment state 정보가 동일하지 않게 되는게 맞겠죠. 이를 POMDP라고 합니다.
Agent는 현재 시점의 state를 만들어야 합니다. 그래야 어떤 행동을 할 수 있게 되니까요. 이를 위해서 3가지 방법으로 만들수 있다고 합니다. 히스터리 전체를 사용하는 방법과 과거 상태가 발생한 확률, 즉 통계적인 방식을 사용해서 만들거나 머신러닝의 RNN 과 같은 방식으로 만들수 있습니다.

강화학습에서의 Agent에 대해서 좀더 자세하게 알아보겠습니다.
Agent 는 중요한 3가지 컴포넌트들을 가지고 있습니다.

첫번째는 policy 입니다. 정책은 어떤 상태에서 이 agent가 어떤 행동을 해야하는가에 대한 내용입니다.
이미 규칙 같은것이 정해져 있는 것이죠.
혹은 주어진 환경속에서 어떠한 상호작용을 하면서 행동을 하고 그 행동에 대한 반응을 얻게 되는 것을 말하기도 합니다.
이 policy가 Deterministic 하다면 어떤 상태에는 결과적으로 어떤 행동이 결정이 되어 있을 것입니다. 마치 죄를 지으면 우리나라의 법이라는 정책상에서는 감옥에 가야 한다가 정해져 있는 것과 비슷합니다.
만약 이 policy가 Stochastic 하다면 어떤 상태에서 어떤 행동을 하는 것이 확률적으로 높은지에 따라서 행동이 결정이 될 것입니다. 이것은 교통신호를 위반하는 죄를 지었지만 경찰에게 발견이 될 확률이 얼마나 될지를 생각해보면 비슷하겠습니다. 대부분의 경우 Stochastic 하게 되어집니다.

두번째 중요한 요소는 Value function 입니다. 이것은 미래의 보상을 예측하기 위한 것입니다. 기대되는 미래의 보상, 가치가 됩니다.
이 가치가 높으면 좋은 상태가 될 것이고 만약 좋은 상태가 아니라면 가치는 낮아지게 될 것 입니다. 이를 수학적인 함수로 표현을 하면 위의 공식과 같이 됩니다. 특정 policy 상에서의 value는 다음에 발생할 보상과 그 다음, 다음에서도 발생할 보상들의 합을 기대하게 됩니다. 하지만 현재의 보상이 아닌 미래의 보상에 대해서는 현가를 적용해서 할인율을 적용해줘야 합니다.
이로 인해서 미래에 총 보상에 대해서 인지하고 그 보상이 큰 방향으로 행동을 하도록 선택하게 되겠습니다.
( Reward는 현재 액션에 대한 즉각적인 보상을 말합니다. 이때 보상은 숫자로 주어지게 됩니다. 이 Reward가 크면 당연히 좋은 것이지만 미래에 기대되는 Reward가 크다면, 즉 Value가 크다면 현재의 Reward가 작더라도 큰 Value를 취하는 액션을 하는 것이 더 이득입니다. 그러므로 Reward는 현재가치, Value는 미래가치를 표현하게 됩니다. )

마지막 중요한 요소는 model 입니다. 이것은 현재 상태에서 어떤 행동을 취했을때 환경이 줄 것이라고 예상되는 정보들 (다음 상태정보와 보상) 를 표현합니다. 이는 환경이 행하게 될 행동들을 본따서 만들어진 것이라고도 할 수 있습니다. 또는 환경의 행동들을 추론하는 모델이 될 수도 있겠습니다.
이것은 환경이 가지고 있는 정보와는 별개로 agent 입장에서 보고 있는 또는 느끼고 있는 환경에 대한 정보가 됩니다. 그리고 이러한 모델은 planning 하는데에 사용이 됩니다.
이 모델이 Transition에 대한 것이라고 하면 이것은 다음의 state 정보를 확률적으로 예측하는 모델이고, 또 다른 모델이 Reward에 관한 것이라면 다음에 받게 될 보상의 기대치에 대한 모델이 되겠습니다.

Agent 의 중요한 요소들중에서 어떤 요소들로 우리의 agent를 구성하느냐에 따라서 위와 같이 다양하게 분류가 됩니다.
Policy-Based agent 는 Value function을 사용하지 않고 Policy와 Model만으로 구성된 Agent가 되고,
Value-Based agent 는 Policy를 사용하지 않고 Value function과 Model만으로 구성됩니다.
Policy, Value function, Model을 모두 사용하는 agent 는 Actor Critic이 됩니다.
Model-Free agent 는 Model을 고려하지 않고 Policy and / or Value function을 사용해서 구성이 됩니다.
Model-Based agent 는 Model과 Policy and / or Value function을 사용해서 구성이 됩니다.
4. Problems within RL

두가지 기본적인 문제가 있는데,
RL은 초기에 환경에 대해서 알지 못합니다. 그래서 agent 는 environment와 상호작용을 통해서 경험을 하게 되고 그로 인해서 환경에 대해서 알아가게 됩니다. 어느정도 알게 되면 이를 policy 를 생성하고 개선시켜 나아가면서 목적을 이루기 위한 방법을 찾게 해야 합니다.
Planning은 RL과 완전히 다른 것입니다. 이것은 우리가 환경이 이렇다고 알려주도록 되어 있습니다. 게임이라는 환경을 생각하면 공략집 같은것이 이미 있는것이지요. 그 공략집만 보면서 게임을 하게 되면 최적의 길을 한번에 바로 찾아서 갈 수 있을 겁니다. 이미 다음에 어떤 일이 벌어질지 알고 있기 때문입니다.

또 다른 문제는,
RL은 시행착오를 반복하면서 학습을 하게 됩니다. 그리고 그러한 경험을 토대로 목표를 달성하기 위한 좋은 policy를 발견해야 합니다.
자신이 속한 환경을 알아가는 과정이 되는 것이지요. 그리고 보상을 극대화하기 위한 고려가 필요합니다.

환경에 대해서 아직 잘 모르기 때문에 환경에 대해서 알기 위해서는 Exploration 을 합니다. 그리고 어느정도 알게 되면 보상을 극대화 하기 위하여 알고 있는 정보들을 활용해서 Exploitation 을 합니다. 이 두가지는 학습을 하기 위해서 가장 중요한 것이 됩니다.
이 두가지가 적절하게 혼용이 되어져야 최적의 길을 찾게 되기 때문입니다. 만약 이미 알고 있는 정보만을 이용하게 되면 새로운 좋은 정보를 접할 기회를 놓쳐서 더 좋은 방법을 알지 못하고 기회를 잃어버리게 될 수도 있으니까요.
이를 Exploration–Exploitation dilemma 라고 합니다.

마지막 고려해야할 문제는,
Prediction과 Control 에 대한 것입니다. 이미 정책을 알고 있어서 미래의 결과를 예측하고 행동을 하는 것과 가장 최적의 정책을 찾기 위해서 최적화를 하기 위한 것이 있습니다.
우리는 이런 Control 문제를 위해서 Prediciton 문제를 해결해야 하겠습니다.
