
News & Events
[Machine Learning] 48. 머신러닝 시스템 예제 : Aritificial data synthesis

지금까지 우리가 알고리즘들을 배워오면서 또 바로 앞에 내용에서 학습을 위해서는 다양한 이미지 데이터들이 필요하다는 것을 이해하고 있습니다. 이런 기초 학습을 위한 데이터가 많으면 많을수록 머신러닝의 시스템의 성능에 많은 영향을 준다는 것도 이미 알고 있지요
그러면, 이렇게 많은 데이터들을 어떻게 수집하고 생성해야 할까요?
실제적으로 데이터를 수집하기 위해서 많은 노력을 들여야 하게 되는데 이것을 좀더 유용하게 하는 방법이 있습니다. 그것은 바로 인공적으로 데이터를 만들어내는 것입니다. 이것을 Artificial data synthesis라고 합니다.
데이터를 수집하는 주요 경로는 웹이나 인터넷상에서 수집하는 방법이 있고, 현재 보유하고 있는 작은 데이터셋(small labeled training set)으로 부터 인공적으로 아주 많은 training set을 만들어내는 방법이 있습니다. 이를 통해서 어떻게 하면 인공적으로 데이터를 많이 만들어낼 수 있는지에 대해서 알아보겠습니다.
앞의 photo OCR에서 다루었던 character recognition 에 사용되는 글자 이미지들이 있습니다. 이 이미지들이 학습에 사용될 수 있도록 image patch를 적용하고 색상을 gray-scale로 만들었습니다. 칼라풀한 이미지보다 gray-scale 이미지가 학습하는데 더 쉽고 유용하다고 배웠습니다.
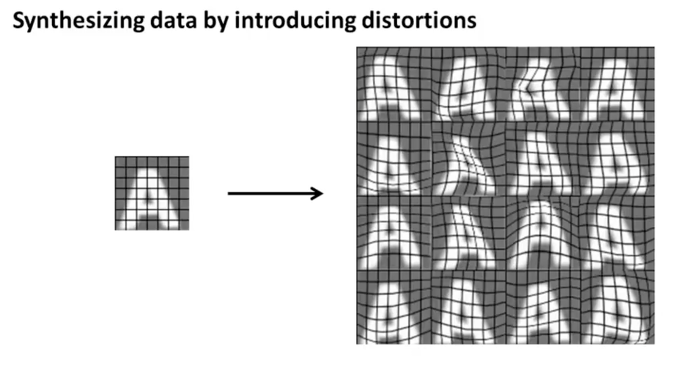
이번에는 인공적으로 이런 글자 이미지들을 만들어보겠습니다. 먼저 웹상에서 널리 사용되고 있는 font 정보를 수집합니다. 다양한 글자 모양에 대한 font 정보들을 무료로 수집할 수 있을 겁니다. 그리고 이 폰트들을 적용하여 글자를 만들고 이 글자 뒷 배경이미지를 랜덤하게 생성해 주면 아래 오른쪽과 같이 다양한 글자 이미지들을 만들어 낼 수 있게 됩니다. 때로는 임의로 blurring이나 distortion filters를 사용해서 이미지에 왜곡이나 번짐 처리를 할 수도 있습니다. 이렇게 하여 다양한 폰트와 배경과 모양의 글자 이미지들을 만들어 내는 것입니다.


정상적인 글자 이미지 한개를 가지고도 distortion을 사용해서 아래 오른쪽과 같이 다양한 왜곡된 모양의 이미지를 16개 이상의 이미지로 만들어 낼 수도 있습니다.
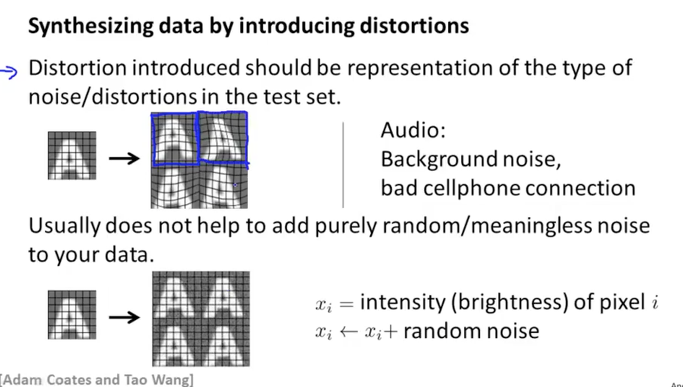
조금 다른 분야이기는 하지만 음성인식에서도 활용될 수 있습니다. 오리지널의 깨끗한 음성 audio를 사용해서 그 뒤에 다양한 noise들을 추가해서 학습에 유용한 새로운 음성 데이터를 만들어낼 수 있습니다.

A 글자 이미지를 distortion등을 사용하여 다시 여러 다른 이미지로 만들었습니다만, 때로는 이러한 왜곡이나 노이즈를 입히는 것이 유용하지 않을 경우도 있습니다. 아래 그림의 하단의 A 글자 이미지들은 눈으로 봐서는 크게 차이가 없지만 각 pixel 마다 다른 밝기의 노이즈를 적용한 것들입니다. 그런데 이러한 이미지는 우리가 하려고 하는 photo OCR에서는 크게 도움이 되지 않을 수도 있습니다. 목적에 맞게 유용한 데이터로 생성하는 것이 중요할 것 같습니다.
많은 데이터를 생성하기 전에 한번 고려해 봐야 할 내용이 있습니다. 우리의 알고리즘으로 만든 시스템이 low bias 인지를 먼저 확인해보는 것입니다. learning curves를 통해서 이를 확인하고 데이터가 더 많아지면 좋은 성능이 나오는 시스템일 경우에 해야지 그렇치 않으면 아무런 도움이 되지 않을 수 있습니다.
만약, low bias classifier가 아니라면 데이터를 늘리는 것보다는 features를 신규로 생성하는 것이 더 도움이 될 것입니다.
또 한가지는 이러한 많은 데이터를 생성하는데 얼마나 작업이 혹은 시간이 들어가는지 확인을 해보는 것이 좋습니다. 현재 가지고 있는 데이터보다 약 10배 더 많은 데이터가 필요하다고 판단이 되면 그리고 이렇게 추가된 데이터를 통해서 머신러닝 시스템이 더 좋은 성능을 낼수 있다면 해야겠지요. 하지만 얼마나 많은 시간을 들이게 될 것인지 한번 비교해보는 것이 좋습니다.
예를들어, 1,000건의 샘플 데이터를 작업해 보니 한 건당 10초 정도 걸리다고 할때, 우리가 총 몇건의 데이터를 생성해야 할 것인지를 계산해보면 대략적으로 추정 시간을 알 수 있을 겁니다.
또 다른 데이터를 수집하는 방법으로는 Crowd sourcing을 활용하는 것입니다. 아마존에서하는 Amazon mechanical turks와 같이 인터넷이나 웹 상에서 불특정 다수의 사람들에게서 데이터를 분류하거나 이미지에서 정보를 얻어내는 것이 가능합니다. 이것은 사람이 작업을 하기 때문에 오류도 발생할 수 있지만 또한 신뢰도를 높일 수도 있는 특징이 있습니다. 그리고 저렴한 비용으로 데이터를 얻을 수 있기도 합니다. 함께 만들어가는 데이터, 서비스가 되는 것이지요

