
News & Events
[Machine Learning] 28. SVM (Support Vector Machine) – 강력한 classification

지금까지 우리는 Supervised learning algorithms 에 대해서 알아보았습니다. 여러가지 알고리즘이 있었고 성능상에도 알고리즘들간에 큰 차이가 없다는 것을 알았습니다.
이번에는 조금 다른 알고리즘에 대해서 알아보려고 합니다. 현재 널리 이용되고 있으면서 강력한 알고리즘으로 유명한 Support Vector Machine 혹은 Large Margin Classification 이라고 불리우는 알고리즘 입니다. 이 알고리즘은 logistic regression이나 neural network과 비교해서도 보다 복잡한 non-linear functions을 처리하는데 유용합니다.
SVM을 설명하기 위해서 logistic regression에서 시작하여 어떻게 변하여 만들어지는지 하나씩 살펴보겠습니다.
아래와 같이 logistic regression에서의 h(x) 함수가 있었습니다. 이때 y=1 이면 h 함수의 결과값도 1에 가까워지고 결국 이때의 세타 trans * x는 0보다 크게 될 것입니다. 반대의 경우로 y=0이면 세타 trans * x는 0보다 작은 값이 되겠습니다. 여기서 세타 trans * x 를 편의상 z라고 하겠습니다.
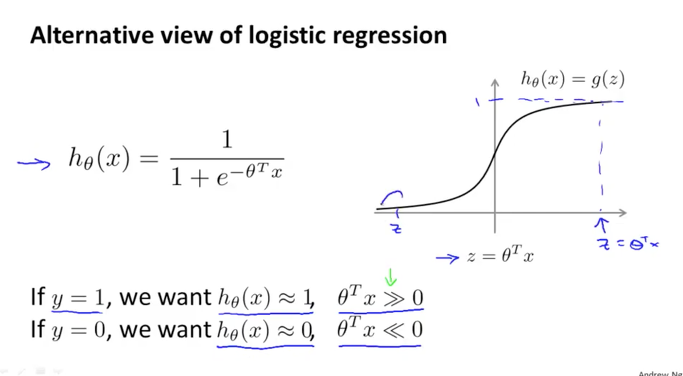
자 이번에는 cost 함수를 살펴보겠습니다.
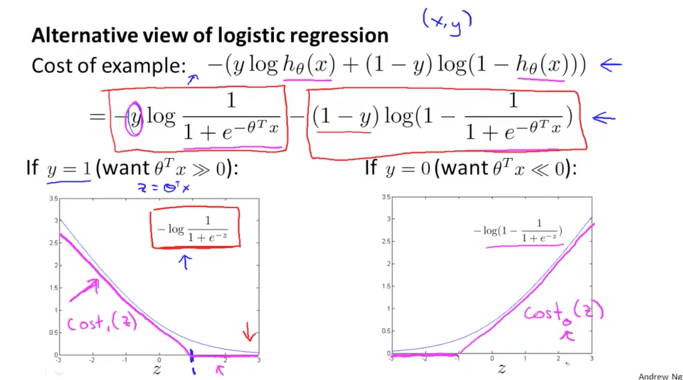
아래 그림의 상단에서와 같이 logistic regression 의 cost 함수는 log와 h(x)로 구성이 되어 있습니다. 여기에서 h(x)를 위의 sigmoid 함수로 대체를 하면 바로 아래와 같은 공식이 됩니다. 이 공식의 앞부분과 뒷부분으로 나누어서 생각을 해보게습니다.
앞부분은 y=1 일때만 값을 가지므로 왼쪽의 그래프에서 파란색과 같은 형태로 나타나는 것을 이전에 배웠습니다. 여기서 조금 변형을 해서 빨간색의 두개의 직선으로 나타내보도록 하겠습니다. 즉, z > 1 때는 cost가 0의 값을 나타내는 직선이 되고 z < 1 때는 z 값이 작아짐에 따라서 cost 값이 커지는 직선으로 말입니다. 이것은 기존의 log 함수와 동일한 기능을 하면서 곡선이 아닌 직선으로 좀더 쉬운 연산이 가능할 것 같습니다. 이렇게 새롭게 탄생한 함수를 편의상 cost1(z)라고 하겠습니다.
마찬가지로 뒤부분은 y=0 이때만 값을 가지게 되고 오른쪽 그래프와 같이 됩니다. 그리고 cost0(z)라고 하겠습니다.
자 이것을 대입해서 Support Vector Machine의 공식을 만들어 보면 아래의 공식과 같이 됩니다.
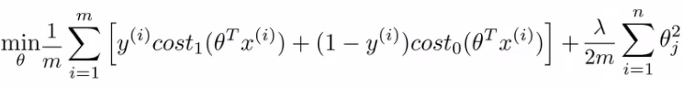
그리고 이 공식에서 1/m 부분을 무시할 수 있습니다. 왜냐하면 우리는 minimize를 할 것인데 상수 값이 크던 작던간에 관계없이 최소값은 항상 동일하게 나타나기 때문에 삭제하도록 할 것입니다.
그리고 또 한가지를 변형합니다. 람다를 조금 바꾸겠습니다.
현재는 A + lambda * B 의 공식인데 이것은 C * A + B의 공식으로 변경하는 것입니다. 이때 새로운 C는 1 / lamdba 와 비슷하다고 생각하면 됩니다.

이렇게 logistic regression의 공식에서 조금 변형을 해서 아래와 같이 SVM에 대한 cost 함수가 정의가 되었습니다. 그리고 여기서 세타trans * x 가 0보다 클때 h(x) 함수의 값이 1이 되고 그렇치 않을때는 0의 값이 된다는 것입니다.
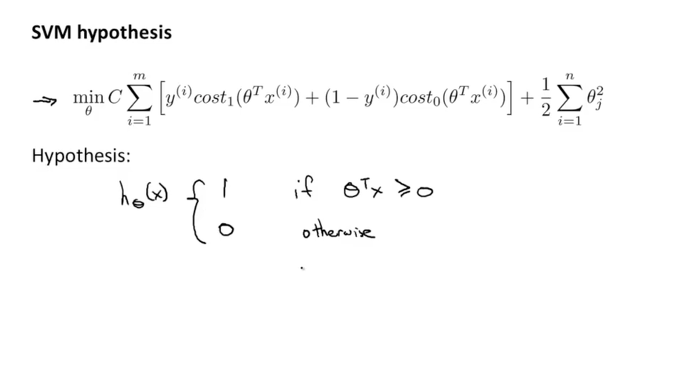
Large Margin Intuition
SVM가 Large Margin Classification 이라고도 불리운다고 했었습니다. 왜 그렇게 되는지 간단하게 개념적으로 이야기를 해보도록 하겠습니다.
아래 그림에서와 같이 SVM의 공식을 다시 그래프로 표현을 해보면, y가 1일 때에 cost1(z)은 z가 1보다 크거나 같은 구간에서 0의 값이 됩니다. 또 y가 0일 때에 cost0(z)은 z가 -1보다 작거나 같을때의 구간에서 0의 값이 되는 것을 볼 수 있습니다. 우리가 앞에서 세타trans * x가 0보다 클때 h(x)가 1이 된다고 했었는데 실제적으로는 1보다 크거나 같을때가 됩니다. 반대로 세타trans * x가 0보다 작을때 h(x)가 0이 된다고 했었는데 실제적으로는 -1보다 작거나 같을때가 됩니다. 이렇게 되면 판단하는 기준값 사이에 어떤 gap이 생긴다는 것을 알 수 있습니다.

C의 값이 상당히 큰 값이라고 가정을 해보겠습니다. minimize가 되어야 하기 때문에 cost1, cost0로 구성되어진 공식의 값이 0이 되어야 할 것입니다. 다시 이 cost1, cost0의 값이 0이 되기 위해서는 세타trans * x 의 값이 y가 1일때는 1보다 크거나 같아야 하고, y가 0일 때는 -1 보다 작거나 같아야 한다는 것을 알 수 있습니다.
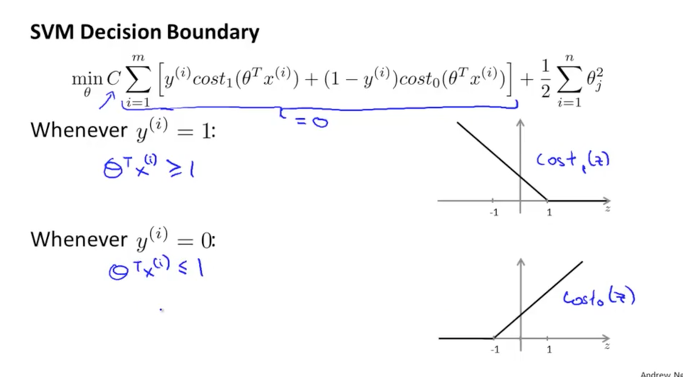
그리하여 위의 조건이 만족되게 되면 결국 C의 값과 곱해지는 cost1, cost0로 구성되는 값이 0이 되어 사라지게 되고 다음과 같이 뒷부분의 공식만 남게 됩니다.
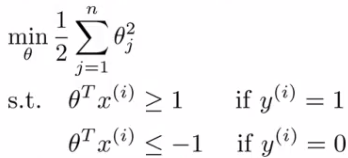

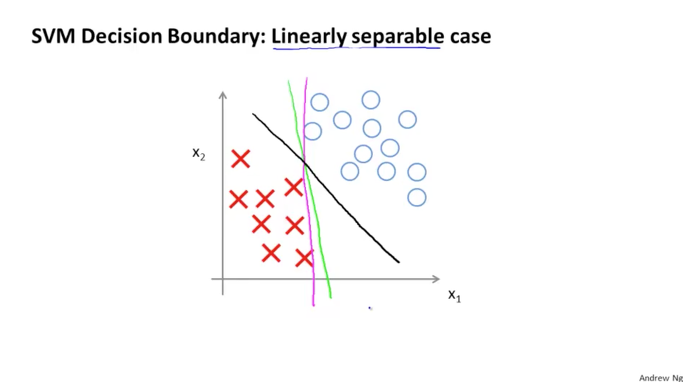
사실상 위에서 살펴본 공식이 SVM의 Decision Boundary를 의미하게 됩니다. 아래 그림과 같은 어떤 dataset이 존재할 경우에 여러가지의 다양한 Decision Boundary가 존재할 수 있습니다. 이 중에서 가장 좋아보이는 것이 바로 검정색 직선으로 구분된 선입니다. 다른 직선들에 비해서 보다 안정적이고 균형적인 것을 알 수 있습니다.
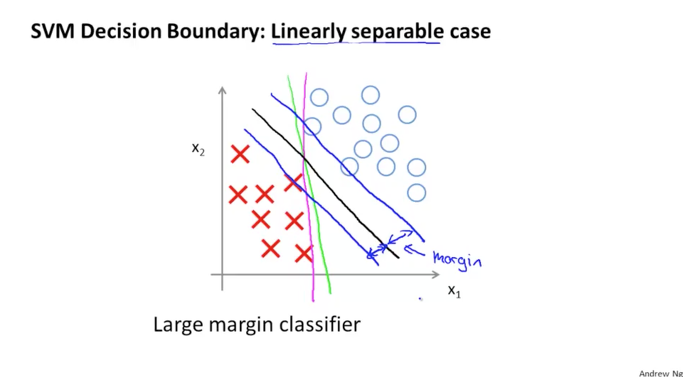
이 검정색의 Decision Boundary가 실제 dataset과의 일정한 거리를 두고 존재하게 되는데 이 간격(Gap)을 margin이라고 합니다. 이로 인해서 SVM이 Large Margin 의 알고리즘이 되는 것입니다.
다시 한번 살펴보면, 왼쪽에는 모두 O의 data가 있고 오른쪽에는 모두 X의 data로만 존재하는 dataset이 있다고 생각해보면 아래의 검정색 직선과 같이 세로의 직선으로 구분이 될 것입니다. 여기에서 만약 새로운 데이터가 추가 되었는데 왼쪽 아래에 X가 생겼다고 해보겠습니다.
이때 만약 C가 상당히 큰 값을 가지고 있다면, 검정색 직선의 Decision Boundary는 빨간색의 직선으로 이동하게 됩니다. 반대로 만약 C가 아주 작은 값을 가지고 있다면, 검정색 직선의 Decision Boundary는 이동하지 않게 될 것입니다.
우리는 C가 1 / lambda와 비슷한 것을 알고 있습니다. 즉 정규화의 개념인 람다의 역수가 된 것이 바로 C가 의미하는 것입니다. 이것은 C를 조절하여 linear 한 decision boundary를 만들수도 있고 또는 dataset에 따라서 non-linear 한 decision boundary를 만들수도 있다는 것을 의미합니다.
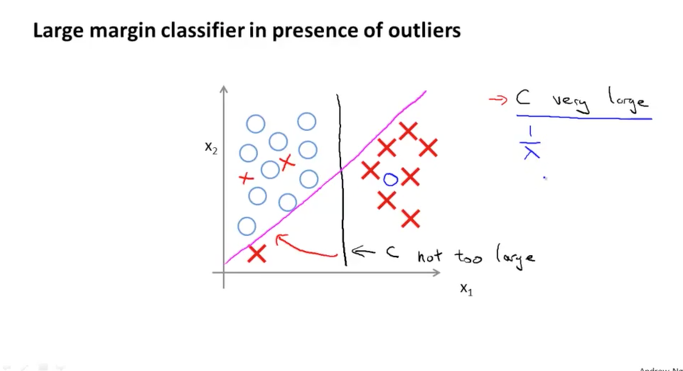
이 개념은 다음에 다루게 될 bias, variance에 대한 내용에서 또 다시 알아보게 될 것입니다. 그리고 그전에 조금 수학적으로 접근하면서 왜 Large Margin 이 가능하게 되는지에 대해서 좀더 알아보고 넘어가도록 하겠습니다.
