
News & Events
[Machine Learning] 14. [실습] Linear Regression 구현해보기 (Octave)

이제 그동안 배웠던 Linear regression를 이용한 머신러닝을 실제 구현을 해보겠습니다.
Octave를 이용해서 간단하게 해볼 수 있습니다.
실습을 하기 이전에 벡터화를 하는 방법에 대해서 잠시 살펴보고 하겠습니다.
Vectorization
우리가 배웠던 h함수를 아래 그림과 같이 공식으로 나타낼 수 있었습니다.
왼쪽편 아래에 표기된 방법으로 구현을 하게 되면 이것은 벡터로 처리하는 것이 아닙니다.
반복문을 돌면서 각각의 변수들을 개별적으로 처리하는 방법이기 때문에 복잡하게 보입니다.
하지만, 오른쪽 아래에 표기된 방법으로 각 변수들을 matrix로 생성하면 공식이 상당히 심플해 지면서 한번 연산으로 처리가 가능해집니다.
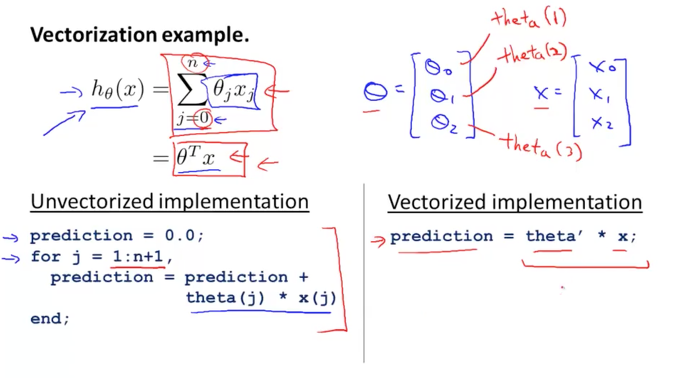
벡터화를 하는 방법에 대해서 알아보겠습니다.
우리가 배운 Gradient Descent 알고리즘에서 각 parameter에 대한 공식이 아래 그림의 공식과 같았습니다. J함수를 계산하기 위해서 각각의 parameters이 동시에 변경되고 동시에 업데이트가 되어 계산이 되어야 한다는 것을 이미 알고 있습니다.

개별적으로 변수를 처리하고 반복문을 사용하면 동시 업데이트가 되도록 신경을 쓰면서 구현을 해줘야 하겠지만, matrix를 이용하면 연산이 한번에 되므로 자연적으로 동시 처리가 되는 이점도 있습니다.
세타 함수를 항목별로 나누어서 살펴보면, [세타 = 세타 – 알파 * 델타] 로 볼수 있습니다.
알파는 learning rate이였고, 델타라고 표현한 부분이 미분하는 부분입니다. 그러면 세타도 Vector가 되고 알파는 Scalar값이 되고 델타는 features로 구성된 Matrix가 되어 연산이 한번에 가능해집니다.
델타는 다시 1/m * ( h – y) * X 로 표현이 되며 m은 dataset의 갯수, h는 h함수로 생성이 되는 Vector, y는 결과값의 Vector, X는 features Matrix가 됩니다.
각각의 연산하는 변수들을 Vector 혹은 Matrix로 구성을 하여 한번 연산에 동시에 처리하는 것이 핵심입니다.

간단한 실습
자 이제 Octave를 이용해서 직접 구현해보면서 실제로 어떻게 동작이 되는지 알아보면 이해하기가 더욱 쉽습니다.
데이터가 없으니 랜덤으로 100개씩 생성해서 만들어 보겠습니다.
X는 하나의 feature를 갖는 데이터가 되고(집의 사이즈), y는 결과값의 데이터(집의 매매가격)가 됩니다.
X = rand(100,1);
y = rand(100,1);
임의로 만들었기 때문에 정상적인 데이터는 아닙니다.
m은 dataset의 갯수임으로 아래와 같이 생성이 가능합니다.
m = length(y);
세타는 세타zero와 세타one으로 두개의 parameters가 되고 이 값들이 h함수를 일차방정식으로 표현하는데 사용이 되었었습니다.
세타를 0의 값으로 초기화하여 2개 요소를 갖는 Vector로 생성합니다.
theta = zeros(2, 1);
h 함수는 세타zero의 상수가 있었고 세타one과 X의 곱하기로 나타냈었습니다. 그리고 이 공식에서 Xzero = 1로 생성하여 변수들의 갯수를 통일시켜주었습니다. 결국 X matrix는 다음과 같이 되어야겠습니다.
X = [ones(100,1) rand(100,1)];
이제 각각의 항목들을 matrix로 표현하였으니 곱하기만 하면 될것 같습니다.
곱하기 연산을 하기 위해서는 두 항목의 Vector의 크기를 맞춰줘야 했었죠? 그래서 다음과 같이 곱해줍니다.
h = X * theta;
h Vector는 현재 파라미터들이 모두 0으로 초기화된 상태이기 때문에 모든 값이 0이 될 겁니다.
자 이번에는 Cost함수인 J함수를 만들어보겠습니다.
h의 결과값과 실제 결과 값인 y의 차이가 cost였으므로 h-y가 됩니다.
또 이 값에 제곱을 해줘야 하는데 각 요소들의 제곱이 되어야 하니 (h-y) .^2와 같이 될 것입니다.
이것을 모두 더해야하니 sum( (h-y) .^2 )가 되고 앞에 상수들을 그대로 적용해주면 다음과 같이 J함수가 생성이 됩니다.
J = 1/(2 * m) * sum((h – y) .^ 2);
그럼 마지막으로 Gradient Descent Algorithm을 구현하면 되겠습니다.
각각의 parameters(세타)들을 변화시키면서 동시에 업데이트가 되도록 하면 됬었습니다.
앞에서 알아본 바와 같이 세타 함수를 만들면 세타 = 세타 – 알파 * 델타로 구성이 되었었고
델타는 각각의 파라미터에 대한 편미분이였으니 델타 = 1/m * (h-y) * X가 됩니다. 여기서 X와의 곱하기 연산을 수행하기 위해서 transpose를 해주면 1/m * (h-y)’ * X가 되겠습니다.
그리고 알파 값을 0.01로 시작 해보겠습니다.
최종적으로 세타와 뒤에 델타가 마이너스 연산이 될 수 있도록 Vector 크기를 맞춰주기 위해서 델타를 transpose 해주었습니다.
alpha = 0.01;
delta = 1/m * ( h – y )’ * X;
theta = theta – alpha * delta’;
여기까지 모든 식이 만들어졌으니 세타를 변경하면서 반복적으로 학습을 할 수 있도록 반복문을 사용해서 실제 학습이 되도록 하면 됩니다. 그리고 cost 값의 변화를 보기 위해 화면에 출력하도록 하였습니다.
h = X * theta;
for i=1:1000
delta = 1/m * ( h – y )’ * X;
theta = theta – alpha * delta’;
h = X * theta;
fprintf(‘cost %f \n’, 1/(2 * m) * sum((h – y) .^ 2));
end
이것을 test,m 파일로 만들어서 실행하면 결과를 볼 수 있습니다.
최종적으로 파일의 내용은 아래와 같이 됩니다.
test.m
clear;clf;
X = [ones(100,1) rand(100,1)];
y = rand(100,1);
m = length(y);
theta = zeros(2, 1);
alpha = 0.01;
h = X * theta;
for i=1:1000
delta = 1/m * ( h – y )’ * X;
theta = theta – alpha * delta’;
h = X * theta;
fprintf(‘cost %f \n’, 1/(2 * m) * sum((h – y) .^ 2));
end
test 파일을 실행 한 결과입니다.
cost 값이 줄어들면서 잘 수행되는 것을 볼 수 있습니다.
>> test
cost 0.156588
cost 0.153812
cost 0.151105
cost 0.148467
cost 0.145894
cost 0.143386
cost 0.140941
cost 0.138557
cost 0.136233
cost 0.133967
cost 0.131758
cost 0.129604
cost 0.127505
cost 0.125458
cost 0.123462
cost 0.121516
cost 0.119619
cost 0.117770
cost 0.115967
cost 0.114209
cost 0.112496
cost 0.110825
cost 0.109196
cost 0.107608
cost 0.106060
cost 0.104550
cost 0.103078
cost 0.101643
cost 0.100245
cost 0.098881
cost 0.097551
…..
이제 여러분은 linear regression의 단일 feature의 dataset으로 머신이 학습할 수 있는 기본을 배우셨습니다.
여기서는 Gradient Descent Algorithm을 이용해서 학습하였습니다.
수고하셨습니다.
