
News & Events
[Reinforcement Learning] 7. Temporal-Difference Learning


TD 방식도 마찬가지로 직접적인 경험을 하면서 학습을 하는 알고리즘입니다.
DP에서 사용하던 bootstrapping을 사용하고 MD에서 사용하던 Model-free 방식의 장점을 두루 갖추고 있는 것이 특징입니다.

every-visit MC에서는 실제 에피소드가 끝나고 받게되는 보상을 사용해서 value function을 업데이트 하였습니다.
하지만 TD에서는 실제 보상과 다음 step에 대한 미래추정가치를 사용해서 학습을 하게 됩니다.
이때 사용하는 보상과 value function의 합을 TD target이라고합니다.
그리고 이 TD target과 실제 V(S)와의 차이를 TD error 라고 하고 델타라고 표현을 합니다.
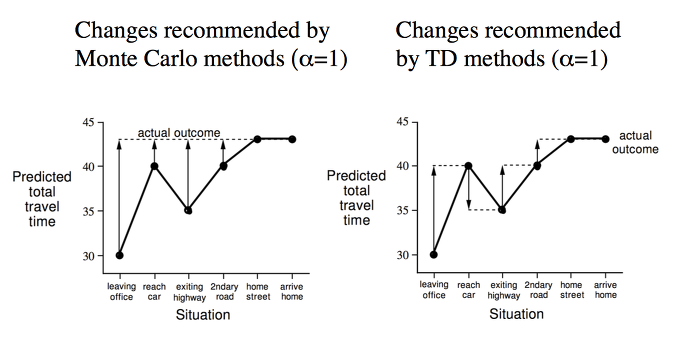
MC에서의 value function이 업데이트 되는 과정을 위 왼쪽의 그림과 같이 설명을 하고 있습니다. 에피소드가 전체적으로 끝나서야 그 보상을 나누어 단계별로 업데이트가 됩니다.
하지만 TD에서는 각 단계별로 업데이트가 되는 과정을 위 오른쪽 그림과 같이 보여주고 있습니다.
특히 각 단계별로 얻게 되는 값들이 2~3번 단계에서 MC와 TD에서 달라지는 것을 알수 있습니다.

TD의 장점은 에피소드 중간에서도 학습을 하게 된다는 것입니다. MC에서는 에피소드가 끝날때까지 기다렸다가 업데이트가 발생하고 학습을 하게 되었었습니다.
TD는 그렇기 때문에 종료가 없는 연속적인 에피소드에 환경에서도 학습을 할 수 있게 되는 것입니다.

V policy가 실제 Gt에 대해서 unbias 라고 할때는 TD target도 V policy를 추종하기에 unbias 입니다.
하지만 TD target에 V policy를 추정하는 V(St+1)을 사용하기에 실제값이 아니라 실제값을 추정하는 값임으로 bias가 발생합니다.
그리고 TD target은 단지 하나의 step에서만 계산을 하기에 noise가 작게 되므로 상대적으로 variance가 낮게 나타납니다.

variance와 bias에 대해서 MC와 TD를 비교하면 위와 같이 나타납니다.
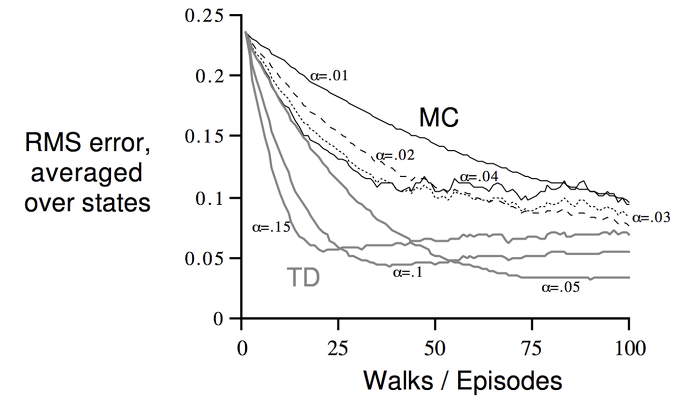
에피소드가 반복이 되면서 에러를 비교해보면 위와 같이 그래프로 나타납니다.
TD 방식이 MC 방식에 비해서 더 빨리 수렴하는 것을 볼 수 있습니다.
또 bootstrapping이 더 학습하는데 효율적이라는 것을 알 수 있습니다.

MC, TD 방식 모두 에피소드를 무한하게 반복하게 되면 결국 실제 value 에 수렴하게 됩니다.
그런데 배치 방식으로 에피소드를 일부만 가지고 계속적으로 학습을 시킨다고 하면 어떻게 될까요?
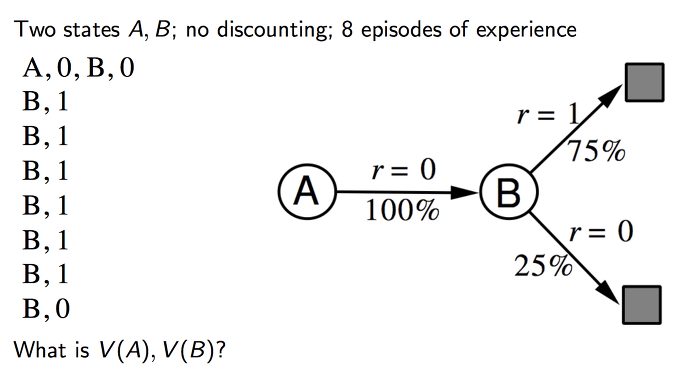
위와 같이 예제를 통해서 알아봅니다.
첫번째 에피소드에서 A가 reward를 0을 받았습니다. B도 0을 받았습니다.
두번째 에피소드에서 B가 1를 받았습니다. 세번째부터 마지막 전까지 같습니다. 그리고 마지막 에피소드에서 B가 0을 받습니다.
이때 A는 100%의 확률로 B로 가게 될 것이고 이때 보상은 0이 될 것입니다.
MC 방식에서는 A가 0의 value를 가지게 될 것입니다. 왜냐하면 A 를 거쳐서 간 에피소드가 하나인데 최종 보상이 0이기 때문입니다
TD 방식에서는 다른 에피소드가 진행이 되면서 B의 value 가 6으로 업데이트가 될 것이기에 A 의 value 도 같이 업데이트가 될 것입니다.
두가지 방식에서 결과적인 차이가 발생하게 됩니다.

MC는 최종적으로 완료한 에피소드의 실젝적인 보상을 사용해서 그 보상에 적합하게 학습을 합니다. 그래서 V(A)가 위에 예제에서 0이 되었습니다.
TD(0) 방식은 max likelihood Markov 방식을 사용하여 수렴하는 알고리즘입니다. MDP 기반으로 실제적인 값을 찾아가게 되기 때문에 V(A)의 값이 6 / 8 로 평균치가 계산이 되어 0.75값으로 업데이트가 됩니다.

TD 는 MDP 특성을 가지는 알고리즘입니다. MDP 환경에서 더 유용하게 동작합니다.
반대로 MC는 MDP 특성을 타지 않습니다. 이는 bootstrapping을 사용한 연속되는 states에 대한 value들을 추정하여 사용하는 거나 업데이트 하는 것이 아니기 때문입니다.
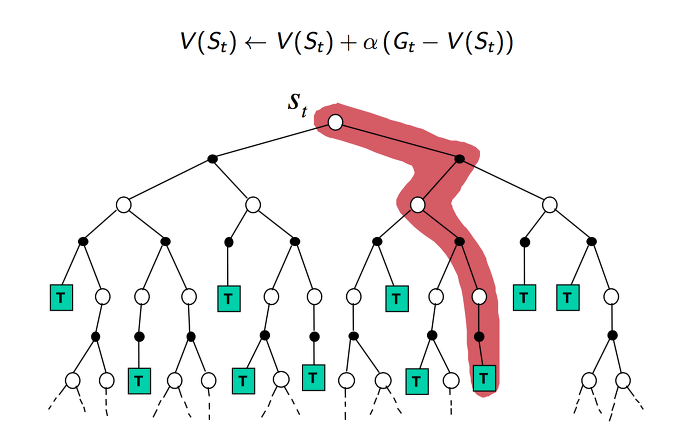
MC 에 대한 backup을 도식화 하면 위와 같이 됩니다. 경험한 에피소드에 대한 업데이트가 일어납니다.
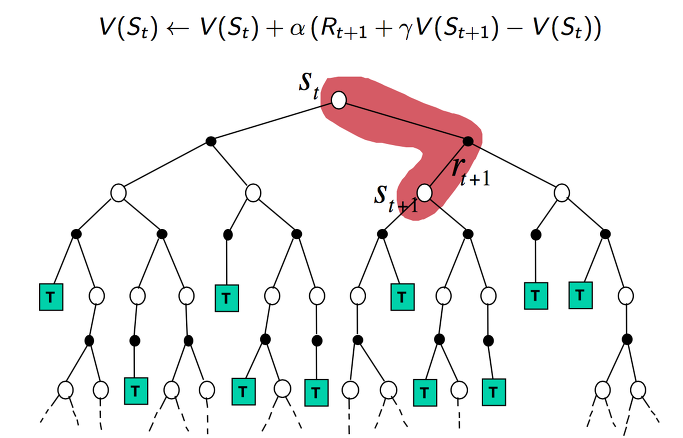
TD 방식에 대한 backup 을 도식화하면 위와 같습니다. 하나의 단계에서 업데이트가 일어납니다.
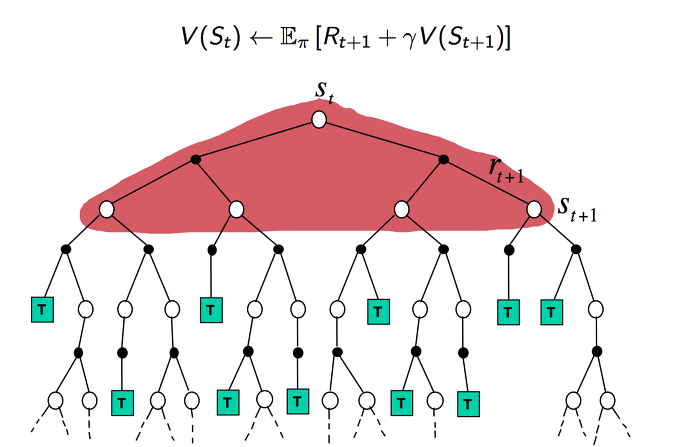
DP 방식에서는 모델을 통해서 이미 모든 MDP를 알고 있고 이에 대한 value와 reward 를 통해서 학습을 하기 때문에 위와 같이 모든 것을 고려하여 학습을 하게 됩니다.

DP와 TD에서 사용하는 Bootstrapping은 추정 값을 기반으로 하여 업데이트가 일어나는 방식입니다.
MC에서 사용하는 샘플링은 expectation을 샘플하여 업데이트 합니다.
TD도 샘플링을 사용한다고 볼수도 있겠습니다. DP 처럼 full backup을 하지 않는다면 말입니다.
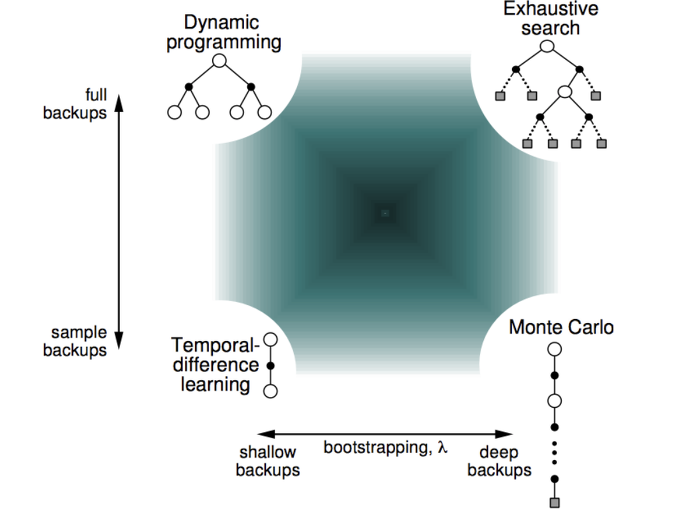
Reinforce Learning의 알고리즘들을 backup의 방식과 bootstrapping 방식의 사용 여부에 따라서 위와 같이 분류할 수 있습니다.
