
News & Events
[알고리즘 트레이딩/시장미시구조] 36. 매수/매도 체결 수량 추정

시장미시구조론 (Market Microstructure) – (36)
매수/매도 체결 수량 추정
그 동안 살펴본 PIN 모형에서 핵심 자료는 매수와 매도의 체결 수량이다. PIN 모형뿐만 아니라 체결 강도 등을 분석할 때에도 매수/매도 체결 수량이 필요하다. 그럼 어떤 거래가 매수 거래이고, 또 어떤 거래가 매도 거래인가? 그리고 매수/매도 체결 수량은 어떻게 추정해야할 것인가? 가 중요한 문제가 된다.
거래는 매수자와 매도자가 서로 사고파는 행위이다. 한 거래에는 매수자도 있고 매도자도 있다. 그럼 어떤 거래가 매수 거래이고, 어떤 거래가 매도 거래인가? 매수자가 Bid 호가창에서 지정가 주문으로 대기 중인데, 매도자가 상대호가로 Bid측 가격에 매도 주문을 냈다면 이 주문은 즉시 체결되고 거래가 발생한다. 이 거래는 매도 거래 (Seller-initiated)로 분류한다. 반대로 매수자가 Ask측에 대기 중인 매도 주문을 체결시켰다면, 이 거래는 매수 거래 (Buyer-initiated)로 분류한다. 호가창에서 대기 중인 주문은 수동적 (방어형) 주문인 반면, 상대호가 주문은 능동적 (공격형) 주문이다. 주가는 능동적 주문에 의해 움직이기 때문에 능동적 주문을 기준으로 매수/매도를 구분한다.
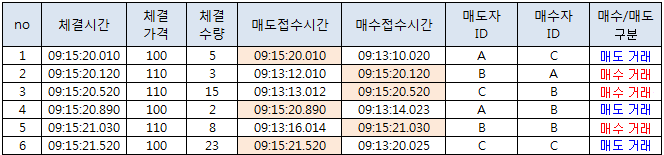
위 그림은 거래소에서 주문이 체결될 때 수집될 수 있는 원초적 거래 데이터를 가상으로 구성해본 것이다. 거래 데이터에는 각 주문의 접수시간과 체결 시간, 그리고 체결 가격 과 체결 수량이 있을 것이다. 1번 데이터를 보면 매수자가 9시 13분 10초부터 대기 중인 상태였는데 (매수접수시간), 매도자가 9시 15분 20초에 상대호가로 주문을 체결시켰음을 알 수 있다 (가격=100, 수량=5). 따라서 1번 거래는 매도 거래로 분류한다. 즉, 접수시간의 순서를 확인하면 이 거래가 매수 거래인지, 매도 거래인지 정확히 알 수 있다 (100% 구분되는 것은 아님).
그러나 위와 같은 데이터는 일반적으로 공개되는 데이터가 아니기 때문에 현실에서는 위와 같이 거래를 (비교적) 정확히 분류할 수 없다. 이러한 데이터는 학술 연구 목적이나 유상으로 제공되기는 하지만 실시간으로 활용할 수는 없다. 따라서 현실에서는 거래소나 증권사에서 제공하는 데이터의 범위 내에서 적절히 추정해서 사용할 수밖에 없다.
1. 호가 데이터와 체결 데이터를 이용하는 방법 (Quote rule)
호가 데이터와 체결 가격을 동시에 이용하는 것으로, 가장 널리 사용되는 방법이다. 체결 가격이 최우선 Ask 가격보다 크거나 같으면, 이 거래는 매수 거래로 분류하고, 체결 가격이 최우선 Bid 가격보다 작거나 같으면, 이 거래는 매도 거래로 분류한다. 만약 체결 가격이 최우선 Ask 가격과 최우선 Bid 가격 사이에 있는 가격이라면, 이 거래는 매수 거래인지 매도 거래인지 구분할 수 없다 (구분 불가).

최우선 Bid/Ask 가격 사이에서 체결되는 경우에는 매수/매도를 100% 정확히 구분할 수는 없다. 만약 아래 그림에서 250.86에 체결된 주문이 있다면 이 주문은 아래 두 경우처럼 구분이 되는 경우도 있고 (a. 경우), 아예 구분이 불가한 경우도 있다 (b. 경우).
a. 매수자가 250.86에 지정가 매수 주문을 접수함. 매도자는 250.86에 잔량이 생긴걸 보고 (증권사 프랍이나, DMA 사용자는 빠르게 볼 수 있음), 상대호가로 매도 주문을 접수함. –> 거래가 체결됨 –> 매도 거래임
b. 매수자가 250.86에 지정가 매수 주문을 접수함. 동시에 매도자도 250.86에 지정가 매도 주문을 접수함. –> 거래가 체결됨 –> 매수 거래인지 매도 거래인지 확정할 수 없음. 두 주문이 모두 수동적 주문이기 때문.
Quote rule은 위의 a, b 경우 모두를 구분 불가로 판정한다. HTS에서는 보통, 매수 거래이면 빨간색으로 표시하고, 매도 거래이면 파란색으로 표시한다. 그리고 구분이 불가한 경우는 노란색으로 표시한다. 그런데 호가창이 빈번히 오르내리는 경우 (변동성이 높은 경우)에는 노란색 (구분 불가)이 의외로 많이 발생한다.
이 방법은 쉽게 적용할 수는 있지만 구분이 불가한 경우가 너무 많다는 것이 단점이다. 또한 이 방법을 적용하려면 호가 데이터와 체결 데이터의 동시성이 보장되어야 한다. 만약 체결 데이터와 직전 호가 데이터의 순서가 바뀌거나, 직전 호가 데이터가 유실된 경우에는 매수/매도 구분이 달라질 수 있다.
2. 체결 데이터만 이용하는 방법 (Tick rule)
이 방법은 호가 데이터가 없는 경우에 체결 데이터만으로 매수/매도를 구분할 수 있는 방식이다. 아래 그림은 최근에 상장된 코스피200 미니선물의 데이터이다. 아직 유동성이 풍부하지 않아 빈 호가가 많이 보인다. 아래 데이터에 Quote rule을 적용하면 매수/매도 구분이 불가한 경우가 너무 많이 발생한다. 따라서 이런 경우에는 체결 데이터만을 이용하는 것이 타당할 수도 있다.

이 방법은 현재 체결 가격과, 이전 체결 가격을 비교하는 방식이다. 현재 체결 가격이 이전 체결 가격보다 높으면 매수 거래로 구분하고, 이전 체결 가격보다 낮으면 매도 거래로 구분한다. 만약 현재 체결 가격과 이전 체결 가격이 동일하다면 현재 체결 구분은 이전 체결 구분을 따른다.
이 방법은 매수/매도 구분이 불가한 경우는 없지만, 체결 데이터만을 이용하기 때문에 구분이 잘못될 가능성이 있다. 특히 호가창의 변화는 많지만 (지정가 주문 및 취소 주문이 빈번함), 체결 데이터가 가끔씩 발생하는 경우 (거래량이 작음)에는 오류의 가능성이 더 커진다.
3. 혼합 방법 (Lee-Ready rule)
이 방법은 Quote rule과 Tick rule을 혼용하는 방식으로, Quote rule에서 구분이 불가한 경우를 Tick rule로 커버하는 방식이다. 이 방법도 일부 단점을 보완할 수는 있지만 그래도 완전하지는 않다. 참고로 이 방법은 [1] Lee & Ready (1991)가 사용하였다 (상세 내용은 아래 reference 참조).
1, 2, 3. 번 모두 대체적으로 맞긴 하지만 정확히 맞는 것은 아니다. 그러나 이 정도의 구분만으로도 웬만한 분석에 큰 지장은 없을 것이다.
4. 종가와 거래량으로 매수/매도 체결량을 계산하는 방법
이 방법은 호가 데이터나 체결 데이터가 모두 없는 경우에 사용할 수 있는 방법이다. 분봉이나 일봉 등의 데이터에는 기본적으로 종가와 거래량이 포함되어 있다. 종가의 변화를 이용하면 거래량을 매수 거래량과 매도 거래량으로 분리해 볼 수 있다. 이 방법은 [2] David Easley 등이 VPIN 모형에서 사용한 방법이다 (VPIN 모형은 다음에 상세히 알아볼 예정임).
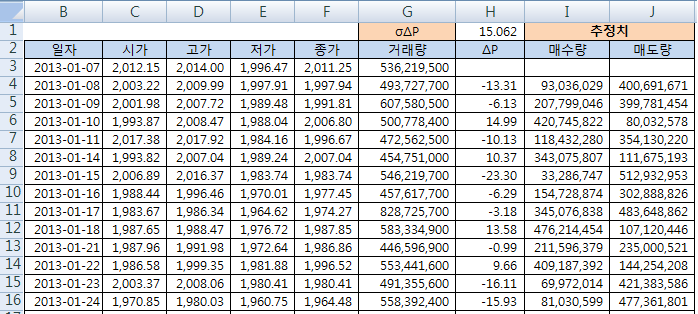
위 그림은 종합주가지수의 일봉 데이터이다. 이 데이터에는 시장 전체의 거래량이 있으므로, 주가의 변화를 이용하면 시장 전체의 매수, 매도 체결량을 추정해 볼 수 있다.
계산 방법 : reference [2]를 응용한 방법임. 상세 내용은 [2] 참조.
1. 주가 변화를 계산한다 : 주가 변화 (ΔP) = 금일 종가 – 전일 종가
2. 주가 변화의 전체 표준편차를 계산한다 : σΔP = STDEV(H4:H266)
3. 매수 체결량을 추정한다 : 매수량 (I4) = G4 * NORMSDIST(H4/$H$1)
4. 매도 체결량을 추정한다 : 매도량 (J4) = 거래량 – 매수량
2013-01-08 에는 지수가 -13.31 포인트 하락했으므로, 매도 체결량이 더 높게 추정되었고, 2013-01-10 에는 지수가 14.99 포인트 상승했으므로, 매수 체결량이 더 높게 추정되었다.
Reference :
[1] Lee, C. and M. Ready (1991), Inferring Trade Direction from Intraday Data
[2] David Easley, Marcos M. Lopez de Prado, and Maureen O’Hara (2012), Flow Toxicity and Liquidity in a High Frequency World
[출처]36. 매수/매도 체결 수량 추정|작성자아마퀀트
