
News & Events
[알고리즘 트레이딩/시장미시구조] 34. PIN 모형 (10) – 클러스터 PIN (CPIN)

시장미시구조론 (Market Microstructure) – (34)
PIN 모형 (10) – 클러스터 PIN (CPIN)
이번 시간에는 2014년 Wang Chun 등이 제안한 클러스터 PIN (Cluster PIN : CPIN) 모형에 대해 알아본다. CPIN은 MLE를 사용하는 대신, 데이터 사이언스 기법 중 군집분석 (Clustering)을 이용하여 PIN 모형의 파라메터들을 측정한다. MLE를 사용하지 않기 때문에 수치해석 알고리즘이 필요 없고, MLE에 비해 측정 속도가 대단히 빠르다는 장점이 있다.
이전 포스트에서 여러 번 언급했듯이, PIN 모형은 매수 체결강도와 매도 체결강도를 분석하여 시장에 참여한 정보기반 거래자의 비중을 추정하는 것이다. CPIN 모형은 매수 체결강도 (B)와 매도 체결강도 (S)의 차이 (D = B – S)를 분석한다. B와 S가 포아송 분포를 따를 때 D는 Skellam 분포를 따른다. D가 0 에 가까우면 매수와 매도가 균형을 이룬 상태이고, D > 0 이면 매수 체결강도가 높고, D < 0 이면 매도 체결강도가 높은 상태이다.
아래 표는 어떤 종목에서 단위 시간 당 매수 체결강도와 매도 체결 강도를 측정한 것이다. 1 번 시간대는 매수 체결강도에 비해 매도 체결강도가 높았고, 4 번 시간대는 균형상태를 이루었고, 10 번 시간대에는 매수 체결강도가 높았다.
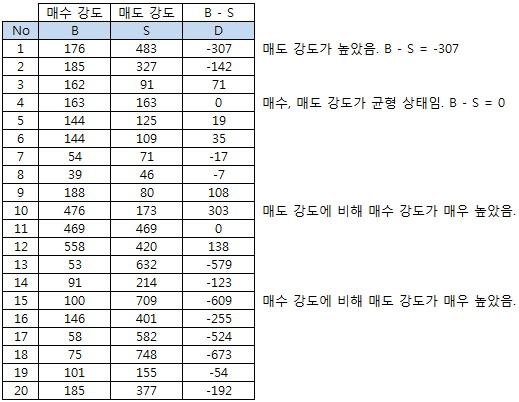
위의 데이터를 이용하여 D를 분류해 보자. 이전 포스트에서 언급한데로 D를 3 그룹으로 분류할 수 있다. D가 0에 가깝다면 시장에 사적정보가 존재할 가능성이 낮은 것이고, D가 0에서 멀어진다면 시장에 사적정보가 존재할 가능성이 커진다. 이 분류를 이용하면 PIN 모형의 α를 추정할 수 있다. D가 0에서 많이 떨어져 있고 D > 0 이라면, B > S 이므로, 시장에는 호재성 정보가 존재할 가능성이 크다. 반대로 D < 0 이라면 S > B 이므로 악재성 정보가 존재할 가능성이 크다. 이 분류를 이용하면 PIN 모형의 δ를 추정할 수 있다.
그룹-1) D ~ 0 : D가 0에 가까우면 시장에 사적정보가 존재할 가능성이 낮음. α는 0에 가까움.
그룹-2) D > 0 : D가 0보다 클수록 호재성 정보가 존재할 가능성이 높음. 1-δ 가 1에 가까워짐.
그룹-3) D < 0 : D가 0보다 작을수록 악재성 정보가 존재할 가능성이 높음. δ가 1에 가까워짐.
D를 위와 같이 3 그룹으로 분류할 수 있다면 PIN 모형의 파라메터를 추정해 볼 수 있다. 이것이 CPIN의 기본적인 아이디어이다. 그러면 분류의 경계점은 어떻게 결정할 수 있을까? 즉, D가 0에 얼마나 가까워야 그룹-1으로 분류하고, D가 얼마나 커야 그룹-2로 분류할 것인가? 이러한 문제는 데이터 사이언스 분야에서 패턴인식 등을 위해 오래전에 이미 개발되어 있다.
Wang Chun 등은 D를 3 그룹으로 분류하기위해 계층적 군집화 알고리즘 (Hierarchical Cluster Analysis)을 사용하였다. 위의 데이터에서 4번 데이터는 (D = 0)는 11번 데이터와 동일한 그룹으로 분류할 수 있다. 그리고 8번 데이터 (D = -7)도 동일 그룹에 포함시킬 수 있다. 한편, 15번 데이터 (D = -609)는 13번 데이터 (D = -579)와 동일 그룹으로 분류할 수 있다. 이런 방식으로 인접한 D의 모든 데이터를 하나씩 분류해 가면서 최종적으로 3개의 그룹이 되면 그룹화 과정을 중단한다.
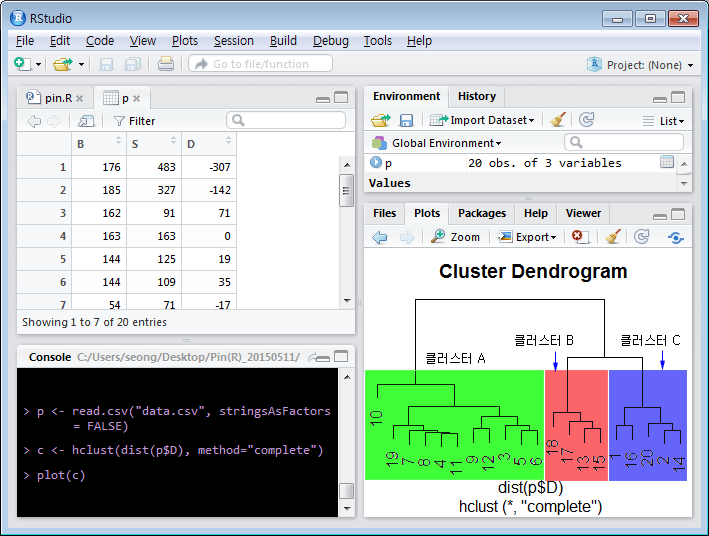
위의 그림은 R에서 기본적으로 제공하는 hclust() 함수를 이용하여 D를 3개의 그룹 (클러스터)으로 분류한 것이다. 여기서는 설명을 위해 20개의 데이터만 사용했지만, 실제 분석에서는 수백개 혹은 수천개의 데이터를 분류한다. 위의 결과에서, 18, 17, 13, 15번 데이터는 클러스터-B로 분류하였고, 1, 16, 20, 2, 14 번 데이터는 클러스터-C로 분류하였다. 그리고 나머지는 클러스터-A로 분류하였다.
클러스터-A는 D가 0에 가까운 것이므로, 사적정보가 존재할 가능성과 밀접한 관계가 있다. 전체 20개 중에 11개가 클러스터-A에 있으므로 정보가 존재하지 않을 가능성은 대략 11 / 20 = 0.55 로 생각해 볼 수 있다 (정보가 존재할 가능성 = 0.45). 클러스터-B는 D < 0 이므로 악재성 정보일 가능성과 관계가 있다. 전체 20개 중에 4개 이므로 20% 정도가 된다.
Wang Chun 등은 이러한 아이디어를 이용하여 아래와 같은 방식으로 PIN 모형의 파라메터들을 측정하였다. 아래의 R-스크립트는 해당 논문에 정리된 측정 절차를 그대로 코딩한 것이다 (상세 내용은 해당 논문 참조). 아래 절차는 MLE를 사용한 PIN 모형보다 훨씬 간단하고 계산 속도도 대단히 빠르다. 따라서 대량의 데이터를 이용한 실증분석이나 PIN 모형을 활용한 실시간 전략에 큰 도움이 될 수 있다. (아래 코드에서 D를 X로 표현하고, Cluster를 Class로 표현하는 등 일관성이 좀 없네요 …)
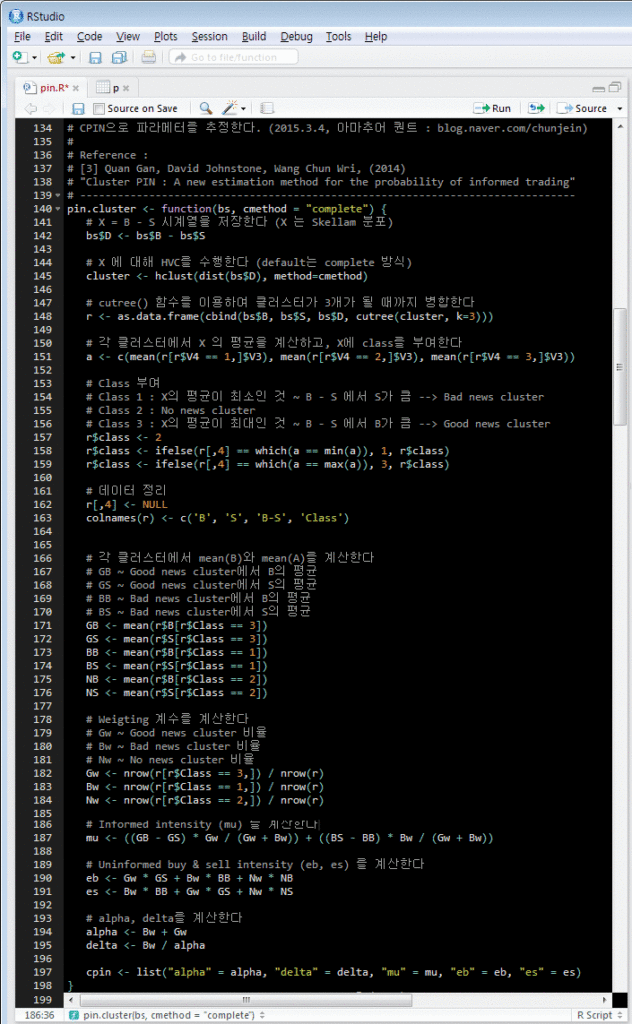
위의 스크립트는 다음과 같이 실행하면 된다. B, S, D가 포함된 data.csv 파일을 만들어 놓고, R-Studio에서 아래와 같이 실행하면 된다.
> bs <- read.csv(“data.csv”)
> cpin <- pin.cluster(bs)
> cpin$alpha
> cpin$delta
여기까지 CPIN 모형을 활용하여 PIN의 각 파라메터를 측정하는 방법에 대해 알아보았다. 논리가 매우 단순하므로 이해하는데 큰 어려움이 없고, 실제 시장에 적용하는 것도 매우 간단해 보인다. 다음 시간에는 동일한 데이터로 PIN 모형의 결과와 CPIN 모형의 결과를 비교해 보기로 한다.
